







 本文围绕语音识别展开,先介绍孤立词识别的模板匹配法,阐述语音特征提取过程,得到MFCC序列,还提及DTW算法、高斯混合模型、隐马尔科夫模型等。对于连续语音识别,探讨了n - gram、最大熵或神经网络等模型。最后说明神经网络在语音识别中应用,利用GMM + HMM提供标准答案提取特征。
本文围绕语音识别展开,先介绍孤立词识别的模板匹配法,阐述语音特征提取过程,得到MFCC序列,还提及DTW算法、高斯混合模型、隐马尔科夫模型等。对于连续语音识别,探讨了n - gram、最大熵或神经网络等模型。最后说明神经网络在语音识别中应用,利用GMM + HMM提供标准答案提取特征。
首先,对孤立词的识别,观察yes和no的波形,他们差异很大,现在再输入一个yes或no,即使是不同人说的,也能分辨出来说的是yes还是no,这是最基本的模板匹配法

特征提取
要对波形进行特征提取,舍弃不同人之间的差异,抓住词语音波形的本质。
一帧信号通常为20-50毫秒,
微观上足够长即包括几个周期,宏观上又要足够短即需要在一个音素以内(音素: y,e,s,n,o就是5个音素)
对一帧信号进行傅里叶变换形成频谱
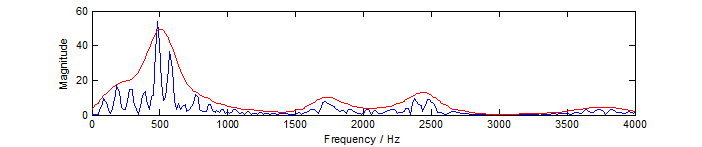
语音频谱的特点是有很多尖的波形,不同尖的高度不同,
频谱具有精细结构和音高
精细结构反应音高,用处较小
包络反应音色,是主要信息
特征提取的目的就是去掉精细结构,只留下包络
方法是用三角滤波,滤波器输出近似频谱包络
人耳对低频敏感,对高频不敏感
一个帧的包络信息进行三角滤波后可能有40个数表示,进一步数学处理压缩,用13个左右的数来表示。得到的结果被称为MFCC
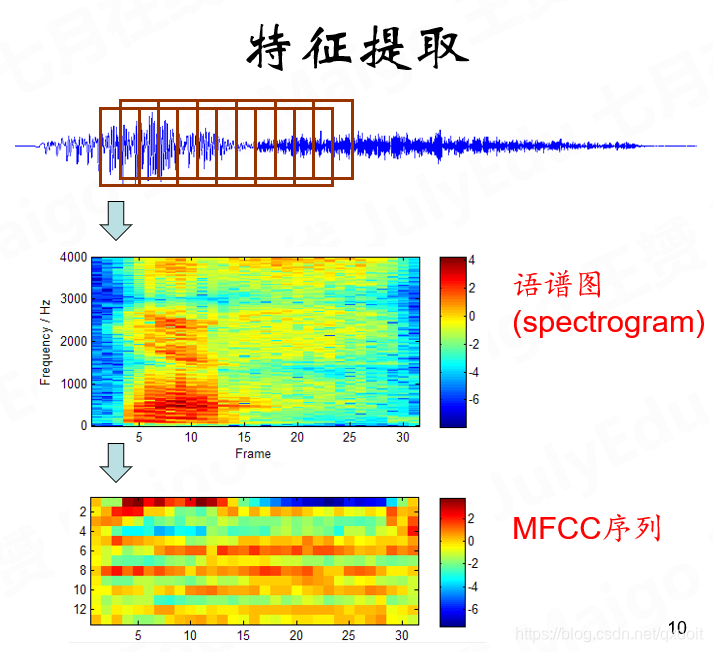
在提取帧的时候还有一个加窗的过程,就是由于取帧会有帧于帧之间的间隔,为了消除明显的分割,可以只向前移半帧这样上一次的帧分割线就在帧中间了
语谱图是经过傅里叶变换得来的,MFCC是又一部信息压缩得来的。
最后我们得到的是MFCC序列表示的一段语音。
MFCC的特征提取有过很多补充,在神经网络应用之后就偃旗息鼓了
现在有了MFCC特征序列,我们用MFCC来匹配模板的MFCC序列,计算距离得到最相似的模板,即和yes于no里面哪个更接近
因为一个词可以说的快也可以说的慢,体现在帧序列上就是一个词可以有不同数量的帧,这个时候怎么匹配呢?
用DTW算法,动态弯算法
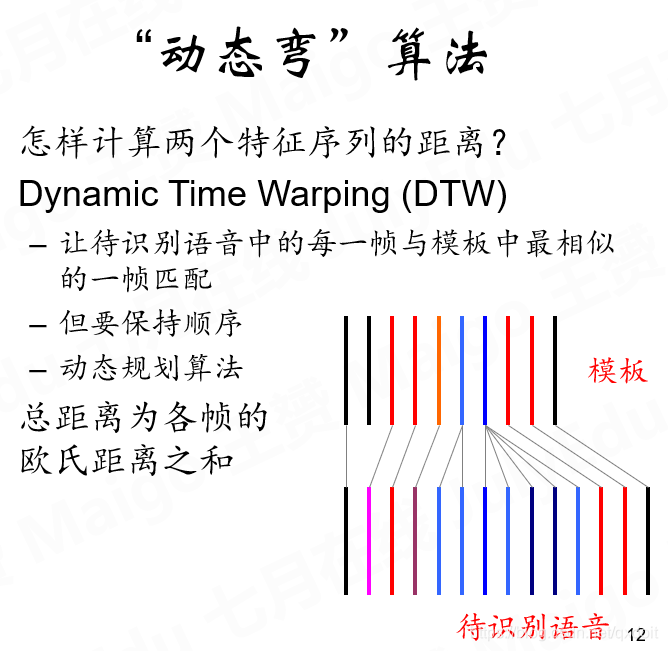
即尽量去匹配模板的特征序列
当然我们不可能只有一个模板,想一下,如果我们有多个yes的模板,然后我们综合一下提取,是不是能够得到一个更具一般性的模板?
那么如何去综合模板呢?
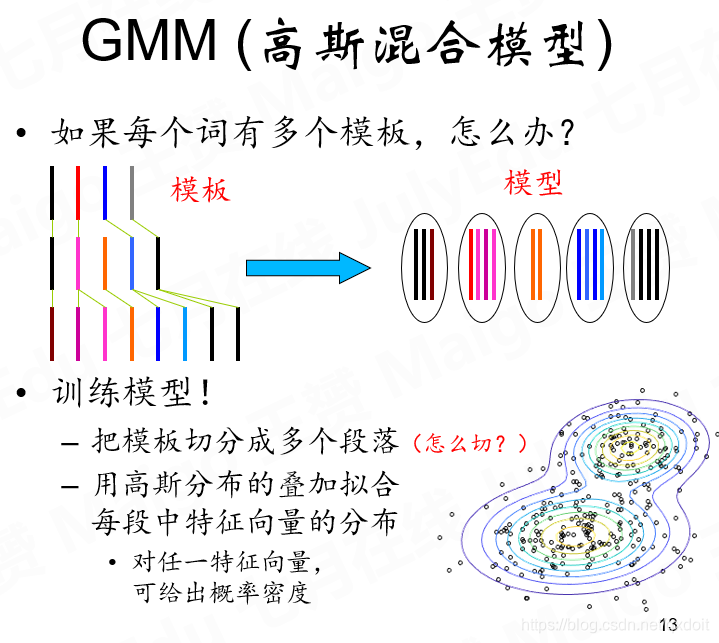
用高斯混合模型,首先选取一个模板,用DTW算法让其他模板向他对齐,主模板有几个特征序列(一个帧是一个特征序列),那么综合模型就有几个。现在我们有了一个综合的yes模板,它有5个特征序列

隐马尔科夫模型HMM,对音素持续时间进行建模,发出一个y,e,s,n,o的持续时间,当然这里面没有严格的对应,比如说yes有三个音素就一定要有3+2个状态,多出来的2是空白,停顿等,它也可以是6个,4个等。
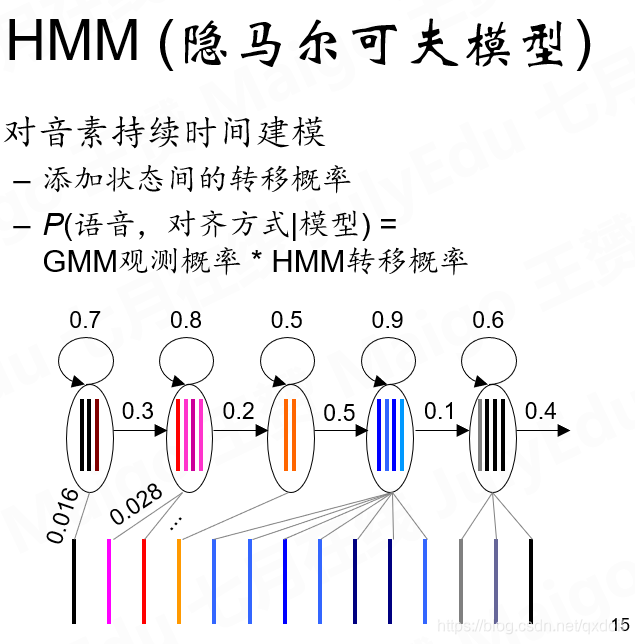


这个模型主要解决的问题就是,我们有一个模型,给定一段语音,那么和模型里面的模板会产生一种对齐方式然后求距离。但是对齐方式和模型是相互关联的,我们训练的目标就是不断优化模型参数和对齐方式。
鸡生蛋和蛋生鸡的问题就用到了EM算法,解决上面的两个目标:


于是现在对于孤立词识别就有了上面的基本公式
给我一段语音,我去找一个在给定这段语音条件下最有可能的一个词。正着求不好求,用贝叶斯公式反转一下
就变成了求在模型里面模板库中寻找一个词的概率乘上在给定这个词模板情况下输入语音模板和它更相似的概率(这个概率就是上文用GMM高斯混合模型得到的综合模板+HMM隐马尔科夫模型得到的最优参数于对齐方式)->P(X|W)
P(X|W)被称为语音模型,而P(W)是语言模型
语言模型这里面反应的是一个人说哪个词的概率更大。
语音模型则反应词本身波形特征序列之间在给定模型情况下的对应概率
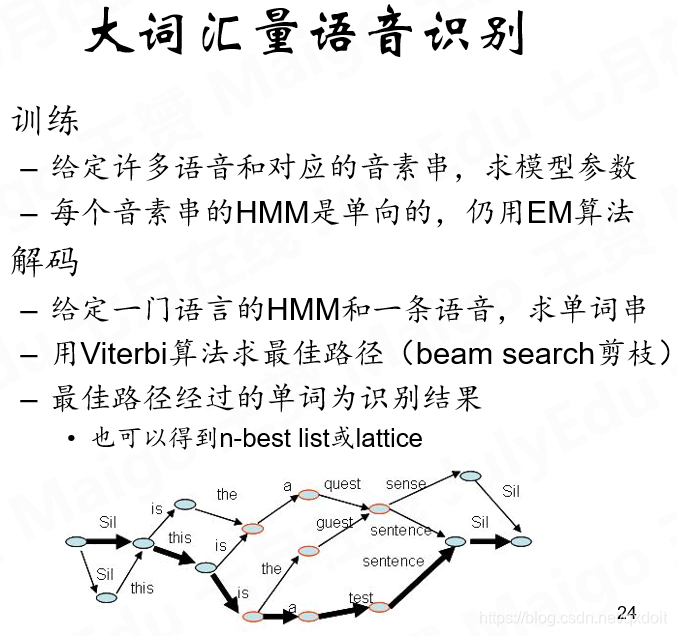
怎样去做连续语音识别?
即去求句子的声学模型,朴素想法是按照单词的声学模型串起来。

需要对上述链式法则进行简化的原因是,我们不可能穷尽所有的句子,比如,我爱...,后面可以接好多内容,不可能把所有的都列进来并给出它的概率,这种情况下,去寻找更加细粒度的东西,即n-gram,只考虑一个词的前面几个字,这是容易的。和单词类似,组成单词的指数26个英文字母,所以排列组合的情况也是有限的,但是如果对单词进行排列组合,那就大多了。
有了n-gram后为什么还要其他模型呢?
因为n-gram关注的范围较小,如果一段话很长,它开头以因为开始,那么很可能后面会跟着一个所以,即遥远的开始也会决定后面的词出现的概率。最大熵或神经网络考虑到了这一点。
把语言模型和语音模型结合,其实结合的就是一个单词和另一个单词之间的转移概率,单词中间是音素的转移概率。
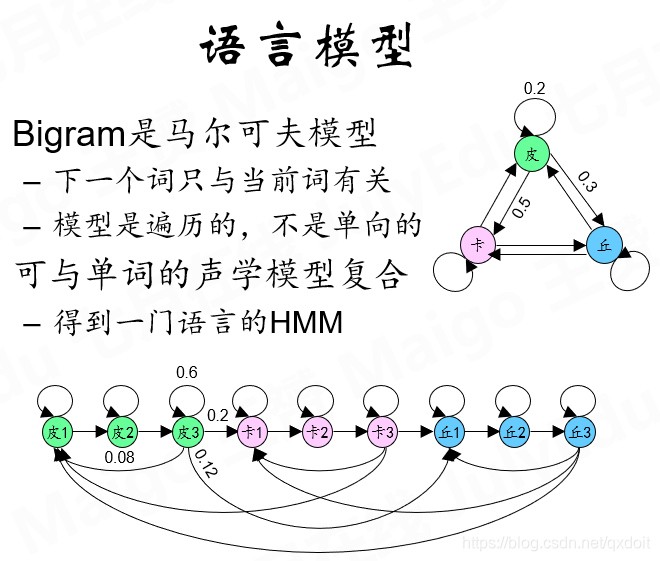
到这一步,同样有上面的问题,需要更进一步的细粒度化,原因同样是单词太多,即使是两个单词的排列组合也很大,比如有10万个词,不可能直接在10万个词上训练马尔可夫模型。
更细粒度化,同样是从音素上着手。
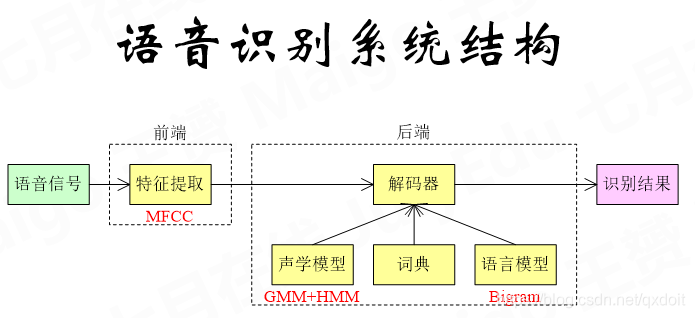
这里,声学模型就是得到一个单词内部的音素概率,词典是单词语音特征序列模板。语言模型是词和词之间的转移概率。
这种结构在以后都是不断打补丁,效果提升缓慢,系统越来越复杂,直到神经网络出现
神经网络在语音识别中的应用:
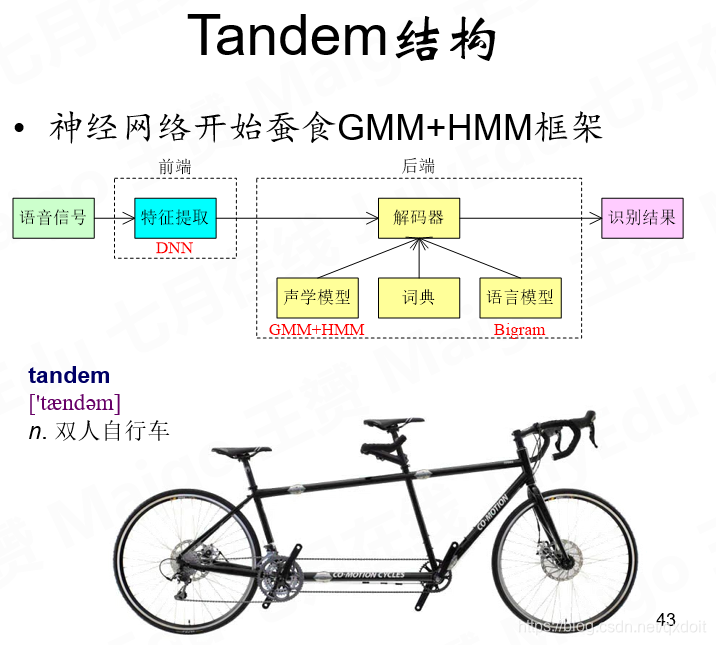
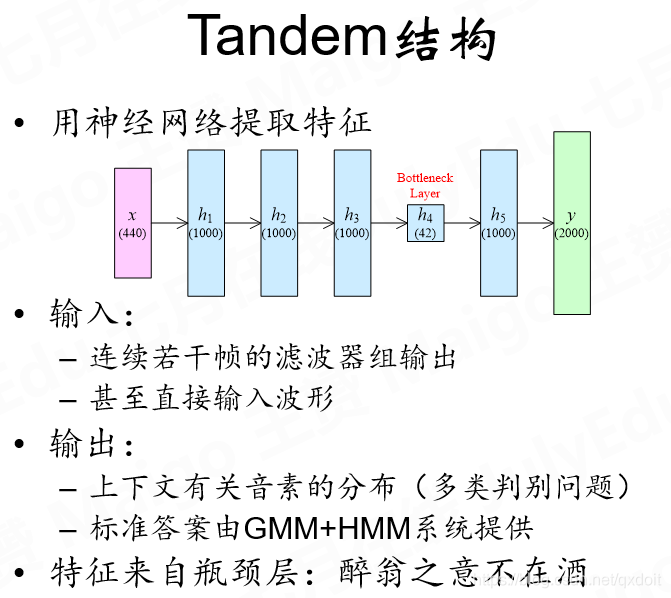
这里的特征提取需要用到GMM+HMM提供标准答案,用于在训练时提取特征。即音素组成单词的概率,GMM解决的是对齐的EM概率,是单个帧的概率,HMM是多帧组成单词的概率。在瓶颈层能够极大限度地压缩提取特征。
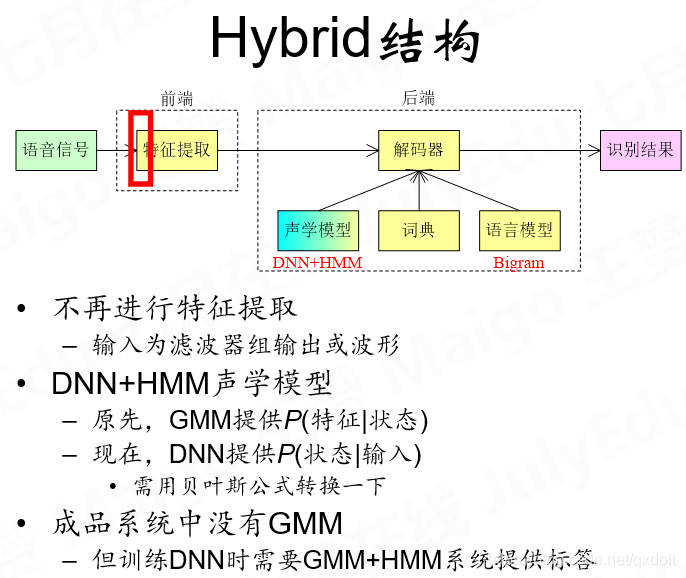

















 2092
2092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









