







 本文详细介绍了TensorFlow中四种学习率调整策略:多项式衰减、余弦衰减、余弦衰减循环和指数衰减,通过实例演示了如何在训练过程中动态调整学习率以优化模型性能。
本文详细介绍了TensorFlow中四种学习率调整策略:多项式衰减、余弦衰减、余弦衰减循环和指数衰减,通过实例演示了如何在训练过程中动态调整学习率以优化模型性能。
一、基本学习率
1.1 多项式衰减
1.1.1 函数参数
def polynomial_decay(learning_rate,
global_step,
decay_steps,
end_learning_rate=0.0001,
power=1.0,
cycle=False,
name=None):
- learning_rate:
初始学习率 - end_learning_rate=0.0001
默认终止学习率为0.001, 注意:如果不修改这个,初始学习率设置为0.001,那就。。不衰减了。 - global_step:
当前step - decay_step:
- cycle:
如果选择为True, 将会在当前step超过衰减step后,循环来过,只不过初始学习率会变小。
1.1.2 实例
import tensorflow as tf
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=0.01, shape=[], dtype=tf.float32)
learning_rate = tf.train.polynomial_decay(learning_rate, global_step,
500, end_learning_rate=0.0,
power=1.0, cycle=True)
summary_lr = tf.summary.scalar("lr", learning_rate)
train_op = tf.assign(global_step, global_step+1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter("./", tf.get_default_graph())
for epoch in range(2000):
s_lr = summary_lr.eval()
summary_writer.add_summary(s_lr, epoch)
sess.run(train_op)
对应图像:
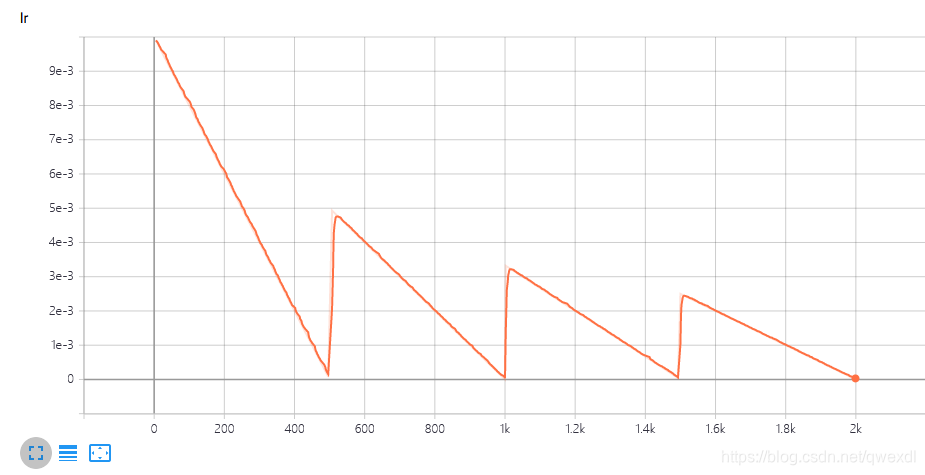
1.2 余弦衰减
1.2.1 函数参数
def cosine_decay(learning_rate,
global_step,
decay_steps,
alpha=0.0,
name=None):
- alpha:
最小学习率
1.2.2 实例
import tensorflow as tf
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=0.01, shape=[], dtype=tf.float32)
learning_rate = tf.train.cosine_decay(learning_rate, global_step, 500)
summary_lr = tf.summary.scalar("lr", learning_rate)
train_op = tf.assign(global_step, global_step+1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter("./", tf.get_default_graph())
for epoch in range(2000):
s_lr = summary_lr.eval()
summary_writer.add_summary(s_lr, epoch)
sess.run(train_op)
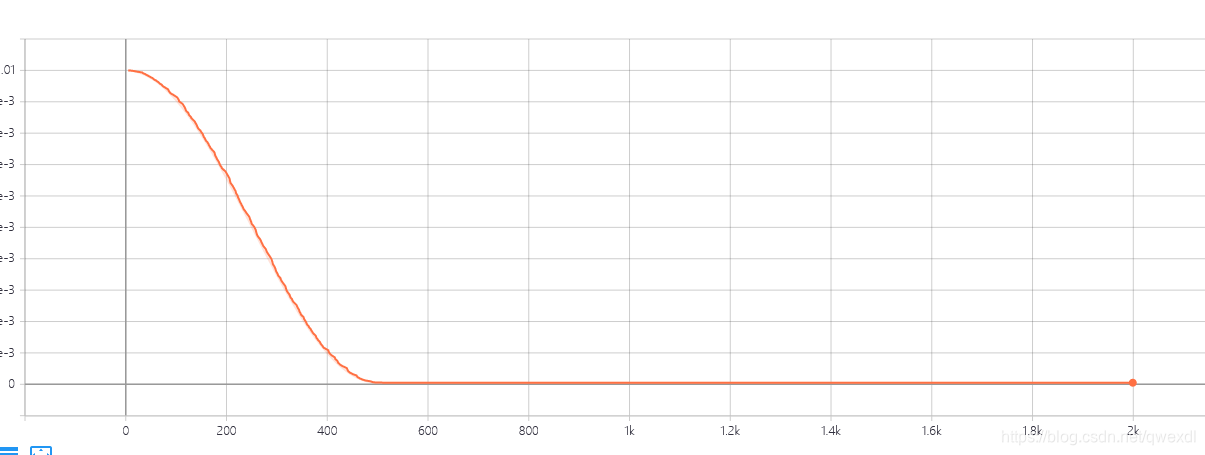
1.3 余弦衰减循环
1.3.1 函数参数
def cosine_decay_restarts(learning_rate,
global_step,
first_decay_steps,
t_mul=2.0,
m_mul=1.0,
alpha=0.0,
name=None):
- t_mul:
用来控制第i轮的step数 - m_mul:
用来控制第i轮的学习率 - alpha:
Minimum learning rate value as a fraction of the learning_rate
1.3.2 实例
import tensorflow as tf
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=0.01, shape=[], dtype=tf.float32)
learning_rate = tf.train.cosine_decay_restarts(learning_rate, global_step, 500, alpha=0.005)
summary_lr = tf.summary.scalar("lr", learning_rate)
train_op = tf.assign(global_step, global_step+1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter("./", tf.get_default_graph())
for epoch in range(2000):
s_lr = summary_lr.eval()
summary_writer.add_summary(s_lr, epoch)
sess.run(train_op)
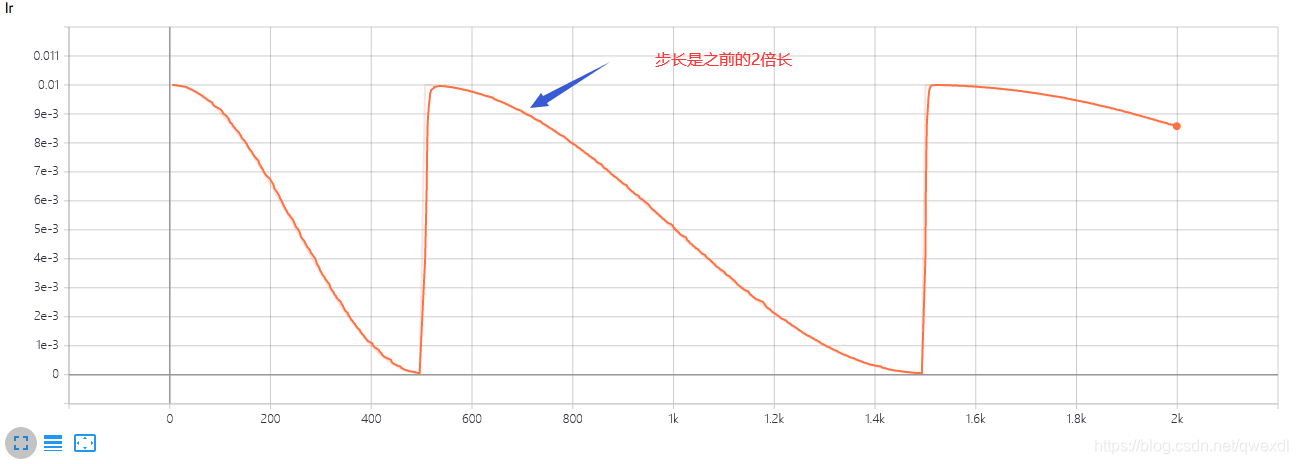
1.4 指数衰减
公式如下:
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
1.4.1 函数参数
tf.train.exponential_decay(
learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None
)
- decay_rate
由公式可以看出, decay_rate <= 1, 且decay_rate越接近0,衰减得越快。
二、高级学习率
1.1 学习率预热
1.1.1 介绍
如果global_step < num_warmup_steps,则学习率为global_step / num_warmup_steps * init_lr。
1.1.2 实例
import tensorflow as tf
num_warmup_steps = 50
init_lr = 0.01
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.constant(value=init_lr, shape=[], dtype=tf.float32)
learning_rate = tf.train.polynomial_decay(learning_rate,
global_step,
500,
end_learning_rate=0.0,
power=1.0,
cycle=False)
with tf.variable_scope("warm_up"):
global_steps_int = tf.cast(global_step, tf.int32)
warmup_steps_int = tf.constant(num_warmup_steps, tf.int32)
global_steps_float = tf.cast(global_steps_int, tf.float32)
warmup_steps_float = tf.cast(warmup_steps_int, tf.float32)
warmup_percent_percent = global_steps_float / warmup_steps_float # 百分比.
warmup_learning_rate = init_lr * warmup_percent_done
# 判断是否需要预热, 如果当前步 < warmup_steps, 则为1. 否则为0.
is_warmup = tf.cast(global_steps_int < warmup_steps_int, tf.float32)
learning_rate = (1.0 - is_warmup) * learning_rate + is_warmup * warmup_learning_rate
summary_lr = tf.summary.scalar("lr", learning_rate)
train_op = tf.assign(global_step, global_step + 1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter("./", tf.get_default_graph())
for epoch in range(500):
s_lr = summary_lr.eval()
summary_writer.add_summary(s_lr, epoch)
sess.run(train_op)
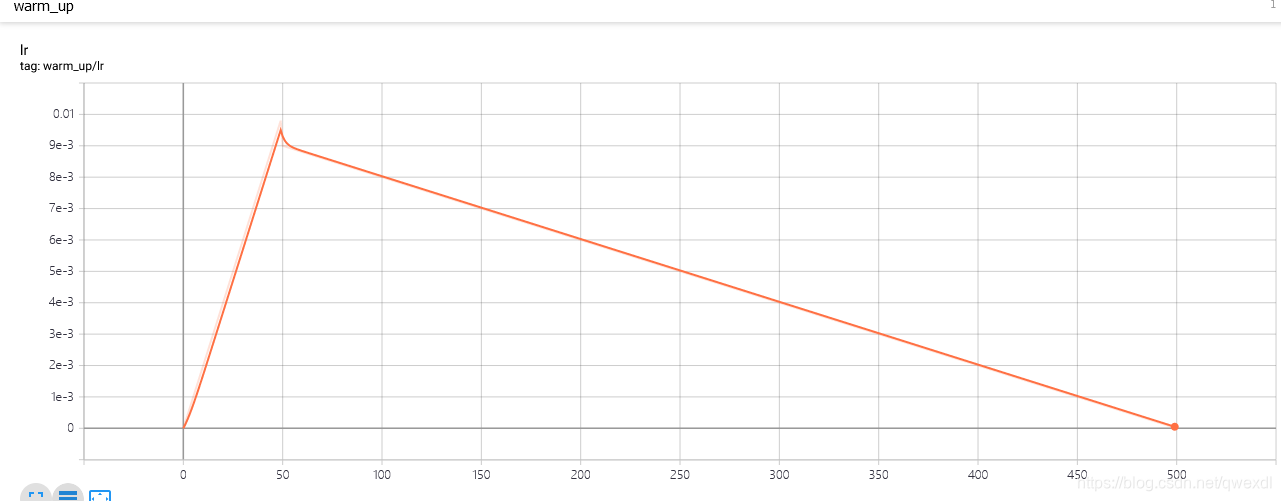

















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









