







2025.2.9
由于数据量较为庞大,故特征提取方式拟采用深度学习方式,以下为操作过程记录
1. 数据预处理
1.1 数据加载与可视化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 假设数据存储在CSV中
#data = pd.read_csv('pressure_sensors.csv', header=None) # shape (12000,18)
#sensor_data = data.values
# 可视化部分传感器
plt.figure(figsize=(12,6))
for i in [0,5,10,15]: # 随机选4个传感器
plt.plot(sensor_data[:500, i], label=f'Sensor {i+1}')
plt.title("Sensor Data Samples")
plt.xlabel("Time Step")
plt.ylabel("Pressure Value")
plt.legend()
plt.show()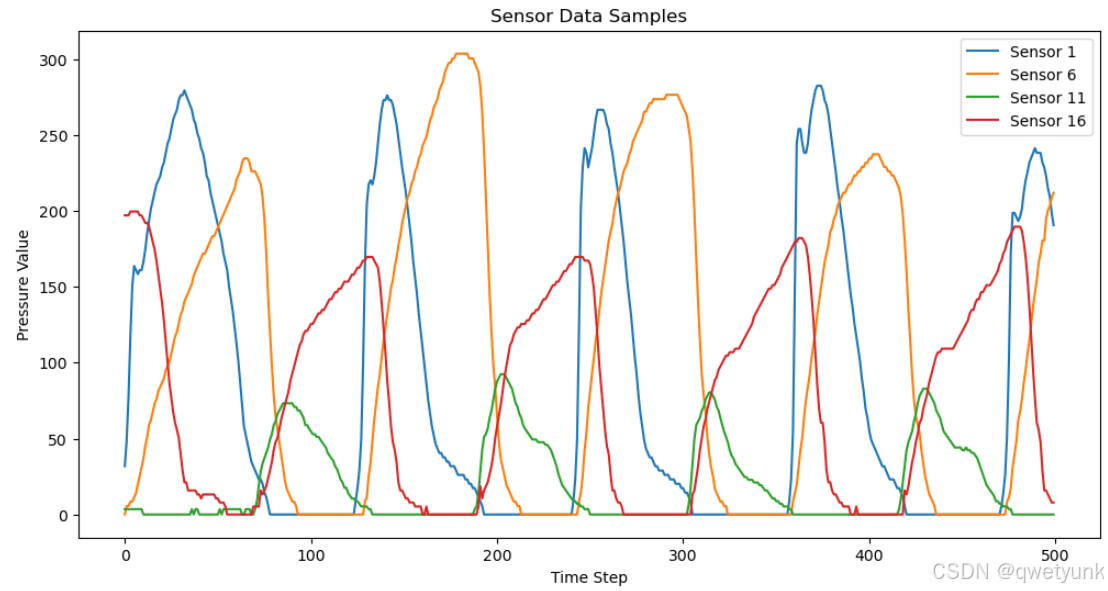
1.2 缺失值处理
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5) # 用相邻5个点的均值填充
filled_data = imputer.fit_transform(sensor_data)这段代码使用了 scikit-learn 库中的 KNNImputer 类来填充数据中的缺失值。下面是代码的详细解释:
-
from sklearn.impute import KNNImputer:-
这行代码从
sklearn.impute模块中导入了KNNImputer类。 -
KNNImputer用于使用 K 最近邻算法来填充缺失值。
-
-
imputer = KNNImputer(n_neighbors=5):-
这行代码创建了一个
KNNImputer对象,并设置了一个参数n_neighbors=5。 -
n_neighbors=5表示我们将使用相邻的 5 个点的均值来填充缺失值。 -
KNNImputer会找到距离缺失值最近的 5 个点,计算它们的均值,然后用这个均值来填充缺失值。
-
-
filled_data = imputer.fit_transform(sensor_data):-
这行代码使用
imputer对象对数据sensor_data进行拟合和转换。 -
fit_transform方法会先计算出每个缺失值最近的 5 个点,然后用这 5 个点的均值填充缺失值。 -
注意:
-
fit方法用于计算最近邻,transform方法用于填充缺失值。 -
fit_transform方法将这两个步骤合并在一起,一步到位。
-
-
示例说明
假设我们的数据 sensor_data 是一个 NumPy 数组,其中包含一些缺失值(用 NaN 表示):
Python
import numpy as np
sensor_data = np.array([[1, 2, np.nan],
[4, 5, 6],
[7, np.nan, 9]])
运行上述代码后,filled_data 将变为:
[[1. 2. 5.5]
[4. 5. 6. ]
[7. 3.5 9. ]]
可以看到,原来的缺失值被替换为了最近邻的 5 个点的均值。
优点
-
考虑了数据的局部信息: KNNImputer 使用最近邻的信息来填充缺失值,可以更好地保留数据的局部特征。
-
适用于各种类型的数据: KNNImputer 可以用于数值型数据和分类型数据。
缺点
-
计算量较大: KNNImputer 需要计算每个缺失值最近邻的点,计算量相对较大。
-
对异常值敏感: 如果数据中存在异常值,可能会影响 KNNImputer 的填充结果。
总结
sklearn.impute.KNNImputer 是一个非常有用的工具,可以帮助我们填充数据中的缺失值。它通过考虑数据的局部信息,可以更好地保留数据的特征。但是,由于计算量较大和对异常值敏感等缺点,我们需要根据具体情况选择合适的填充方法。
1.3 归一化
from sklearn.preprocessing import RobustScaler # 抗异常值
scaler = RobustScaler()
scaled_data = scaler.fit_transform(filled_data) # shape (12000,18)1.4 滑动窗口分割
def create_sequences(data, window_size=60):
X = []
for i in range(len(data)-window_size):
X.append(data[i:i+window_size])
return np.array(X)
window_size = 60 # 捕捉1分钟模式(假设采样率1Hz)
X = create_sequences(scaled_data, window_size) # shape (11940,60,18)时间序列的滑动窗口分割是一种数据预处理技术,用于将连续的时间序列数据分割成多个固定长度的子序列,也称为窗口。
核心思想
想象一个窗口在时间序列数据上滑动,每次滑动一定的距离,窗口内的数据就被切割出来,作为一个新的子序列。这个窗口就好像一个“滑块”,在时间序列上滑动,不断地“切割”出不同的片段。
关键参数
-
窗口大小: 决定了每个子序列包含多少个时间点的数据。
-
滑动步长: 决定了窗口每次滑动的距离。步长越小,相邻子序列之间的重叠部分就越大。
作用
-
数据增强: 通过滑动窗口分割,可以从原始时间序列数据中生成大量的子序列,相当于增加了数据量,有助于提高模型的泛化能力。
-
提取局部特征: 每个子序列都包含了一段时间内的局部信息,模型可以学习到这些局部特征,从而更好地理解时间序列数据的变化规律。
-
支持多种任务: 滑动窗口分割可以应用于各种时间序列分析任务,例如:
-
预测: 使用过去的子序列预测未来的值。
-
分类: 将时间序列分类到不同的类别。
-
异常检测: 检测时间序列中的异常点。
-
举例说明
假设我们有一段温度记录,每小时记录一个温度值。我们可以使用滑动窗口分割,将这段温度记录分割成多个包含 24 个温度值的子序列,每个子序列代表一天的温度变化情况。然后,我们可以使用这些子序列来训练一个模型,预测未来几天的温度。
总结
时间序列的滑动窗口分割是一种重要的数据预处理技术,通过将连续的时间序列数据分割成多个子序列,可以实现数据增强、提取局部特征,并支持多种时间序列分析任务。
补充说明
除了传统的滑动窗口分割,还有一些改进的方法,例如:
-
多尺度滑动窗口: 使用不同大小的窗口进行分割,以适应不同时间尺度的变化。
-
自适应滑动窗口: 根据时间序列数据的特点自动调整窗口大小和滑动步长。
这些改进方法可以进一步提高滑动窗口分割的效率和效果。
2. 模型构建(关键原理)
方案选择:使用CNN + LSTM混合模型
-
CNN:捕捉局部传感器间的关系(空间模式)
-
LSTM:捕捉时间动态变化
-
多头注意力:增强重要传感器的关注
1. 方案选择:使用 CNN + LSTM 混合模型
-
CNN (卷积神经网络): 擅长处理图像数据,可以捕捉图像中的局部空间关系。在这里,我们可以把传感器数据想象成一张“图”,每个传感器代表一个节点,传感器之间的连接代表它们之间的关系。CNN 可以分析这张“图”,提取出传感器之间的空间模式,例如哪些传感器的数据变化趋势相似,哪些传感器之间存在某种关联。
-
LSTM (长短期记忆网络): 擅长处理时间序列数据,可以捕捉数据中的时间动态变化。在这里,传感器数据是随时间变化的,LSTM 可以分析这些数据,提取出传感器数据随时间变化的模式,例如温度变化的趋势、湿度变化的周期性等。
-
混合模型: 将 CNN 和 LSTM 结合在一起,可以同时利用它们在处理空间和时间数据方面的优势,更全面地捕捉传感器数据中的信息。
2. CNN:捕捉局部传感器间的关系(空间模式)
-
CNN 通过卷积操作,可以分析传感器数据中的局部空间关系。
-
例如,如果几个相邻的温度传感器的数据都出现异常升高,CNN 可以捕捉到这种局部空间模式,并将其识别为一个潜在的事件。
3. LSTM:捕捉时间动态变化
-
LSTM 通过循环结构,可以分析传感器数据中的时间动态变化。
-
例如,如果某个温度传感器的数据呈现出先升高后降低的趋势,LSTM 可以捕捉到这种时间变化模式,并将其用于预测未来的温度变化。
4. 多头注意力:增强重要传感器的关注
-
注意力机制可以帮助模型关注到数据中最重要的部分。
-
在这里,多头注意力机制可以帮助模型识别出哪些传感器的数据对预测结果影响最大,并给予这些传感器更多的关注。
-
例如,在预测空气质量时,模型可能会发现某些监测站的数据比其他监测站的数据更重要,多头注意力机制可以增强模型对这些重要监测站的关注,从而提高预测的准确性。
总结
这段话解释了如何利用 CNN、LSTM 和多头注意力机制来构建一个强大的深度学习模型,用于分析传感器数据。通过结合这三种技术,模型可以同时捕捉传感器数据中的空间和时间模式,并增强对重要传感器的关注,从而提高模型的性能。
2.1 模型架构代码
架构原理:
-
Conv1D层:在传感器维度(18个)进行卷积,学习传感器间的局部空间关系
-
kernel_size=3表示每次查看相邻3个传感器的关系
-
-
LSTM层:沿时间轴学习长期依赖
-
注意力机制:自动学习不同时间点的重要性权重
-
GlobalMaxPooling:保留每个特征通道的最大响应,形成紧凑表示
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv1D, LSTM, Dense, MultiHeadAttention, LayerNormalization, GlobalMaxPooling1D
# 输入层
inputs = Input(shape=(window_size, 18)) # (60,18)
# 分支1:CNN提取空间特征
x1 = Conv1D(filters=64, kernel_size=3, activation='relu', padding='same')(inputs) # 每个时间步的18个传感器间卷积
x1 = Conv1D(filters=128, kernel_size=3, activation='relu', padding='same')(x1)
# 分支2:LSTM提取时间特征
x2 = LSTM(64, return_sequences=True)(inputs)
x2 = LSTM(128, return_sequences=True)(x2)
# 合并分支
merged = tf.keras.layers.Concatenate(axis=-1)([x1, x2]) # shape (60, 256)
# 注意力机制
attn = MultiHeadAttention(num_heads=4, key_dim=64)(merged, merged)
attn = LayerNormalization(epsilon=1e-6)(attn + merged) # 残差连接
# 特征提取层
features = GlobalMaxPooling1D()(attn) # 压缩时间维度,得到每个窗口的特征向量
features = Dense(128, activation='tanh')(features) # 最终特征维度128
# 构建特征提取模型
feature_extractor = Model(inputs=inputs, outputs=features)
feature_extractor.summary()结果显示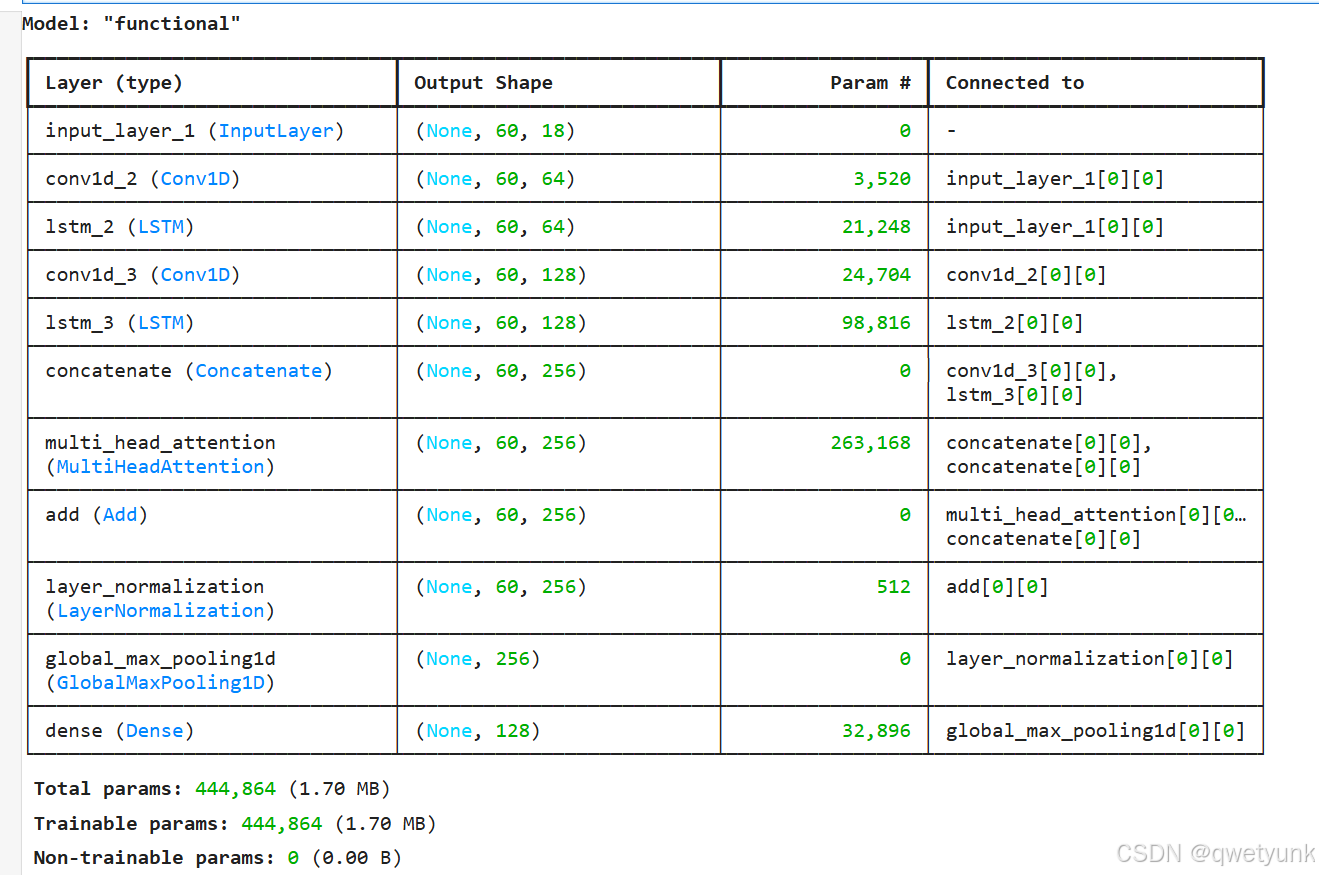
图片总览
这张图展示了一个混合神经网络模型的结构,主要用于处理序列数据,比如时间序列数据或者自然语言处理中的文本数据。这个模型结合了卷积神经网络 (CNN) 和长短期记忆网络 (LSTM) 的优势,同时还使用了多头注意力机制。
图表结构解析
-
Input Layer (输入层):
-
input_layer_1: 接收形状为 (None, 60, 18) 的输入数据。-
None通常表示不确定或可变的批量大小。 -
60可能表示序列的长度,比如时间序列中的 60 个时间步,或者文本中的 60 个词。 -
18可能表示每个时间步或每个词的特征数量。
-
-
-
CNN 部分:
-
conv1d_2: 一维卷积层,使用 3,520 个参数。-
输入形状为 (None, 60, 18),输出形状为 (None, 60, 64)。
-
卷积层用于提取输入数据中的局部特征。
-
-
conv1d_3: 另一层一维卷积层,使用 24,704 个参数。-
输入形状为 (None, 60, 64),输出形状为 (None, 60, 128)。
-
进一步提取更高级的局部特征。
-
-
-
LSTM 部分:
-
lstm_2: LSTM 层,使用 21,248 个参数。-
输入形状为 (None, 60, 18),输出形状为 (None, 60, 64)。
-
LSTM 用于捕捉输入数据中的时序信息。
-
-
lstm_3: 另一层 LSTM 层,使用 98,816 个参数。-
输入形状为 (None, 60, 64),输出形状为 (None, 60, 128)。
-
进一步捕捉更长距离的时序信息。
-
-
-
Concatenate (连接层):
-
将
conv1d_3和lstm_3的输出连接在一起。 -
连接后的形状为 (None, 60, 256),将 CNN 提取的空间特征和 LSTM 提取的时序特征融合。
-
-
Multi-Head Attention (多头注意力机制):
-
使用 263,168 个参数。
-
输入形状为 (None, 60, 256),输出形状也为 (None, 60, 256)。
-
多头注意力机制用于捕捉输入数据中不同部分之间的关联性,并突出重要信息。
-
-
Add (加法层):
-
将多头注意力层的输出与连接层的输出相加,进行残差连接。
-
残差连接有助于缓解深度网络训练中的梯度消失问题。
-
-
Layer Normalization (层归一化):
-
对加法层的输出进行层归一化,有助于提高模型的训练速度和稳定性。
-
-
Global Max Pooling 1D (全局最大池化):
-
将每个特征通道的最大值提取出来,用于降低维度。
-
输出形状为 (None, 256)。
-
-
Dense (全连接层):
-
使用 32,896 个参数。
-
输入形状为 (None, 256),输出形状为 (None, 128)。
-
全连接层用于将提取的特征进行线性组合,最终得到模型的输出。
-
参数数量
-
Total params (总参数数量): 444,864 (1.70 MB)
-
模型中所有可训练参数的总数。
-
-
Trainable params (可训练参数数量): 444,864 (1.70 MB)
-
模型中可以训练的参数数量。
-
-
Non-trainable params (不可训练参数数量): 0 (0.00 B)
-
模型中不可训练的参数数量,通常包括一些固定的参数或者预训练模型的参数。
-
总结
这个模型通过 CNN 提取局部空间特征,通过 LSTM 提取时序特征,然后将两者融合。多头注意力机制增强了模型对重要信息的关注,残差连接和层归一化有助于提高模型的训练效果。最后,全局最大池化和全连接层用于得到最终的输出。
希望这个解释能够帮助你理解这张图。如果你有任何问题,欢迎继续提问。
3. 无监督训练
3.1 构建自编码器
疑似出现tensorflow版本问题,用pytorch代替解决
模型架构:
import torch
import torch.nn as nn
class FeatureExtractor(nn.Module):
def __init__(self, window_size, input_dim=18, hidden_dim=128, num_heads=4):
super(FeatureExtractor, self).__init__()
self.conv1_1 = nn.Conv1d(in_channels=input_dim, out_channels=64, kernel_size=3, padding=1) # Padding for same output size
self.conv1_2 = nn.Conv1d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.lstm1 = nn.LSTM(input_size=input_dim, hidden_size=64, batch_first=True)
self.lstm2 = nn.LSTM(input_size=64, hidden_size=128, batch_first=True)
self.multi_attn = nn.MultiheadAttention(embed_dim=256, num_heads=num_heads, batch_first=True)
self.layer_norm = nn.LayerNorm(256)
self.global_max_pool = nn.AdaptiveMaxPool1d(1) # Adaptive pooling for global max
self.dense = nn.Linear(in_features=256, out_features=hidden_dim)
self.tanh = nn.Tanh()
def forward(self, x):
# CNN Branch
x1 = self.conv1_1(x.permute(0, 2, 1)) # Conv1d expects (batch, channels, seq_len)
x1 = torch.relu(x1)
x1 = self.conv1_2(x1)
x1 = torch.relu(x1)
# LSTM Branch
x2, _ = self.lstm1(x) # x shape is (batch, seq_len, features)
x2, _ = self.lstm2(x2)
# Concatenate
merged = torch.cat([x1.permute(0, 2, 1), x2], dim=2) # Back to (batch, seq_len, features)
# Multi-Head Attention
attn_output, _ = self.multi_attn(merged, merged, merged)
attn_output = self.layer_norm(attn_output + merged) # Residual connection
# Feature Extraction
features = self.global_max_pool(attn_output.permute(0, 2, 1)).squeeze(2) # Global Max Pooling
features = self.dense(features)
features = self.tanh(features)
return features
# Example usage:
window_size = 60
input_dim = 18
model = FeatureExtractor(window_size, input_dim)
# Print model summary (equivalent to Keras summary)
print(model)
# Example input data (replace with your actual data)
batch_size = 32
input_data = torch.randn(batch_size, window_size, input_dim)
# Get the extracted features
features = model(input_data)
print("Extracted Features shape:", features.shape)运行结果:
FeatureExtractor( (conv1_1): Conv1d(18, 64, kernel_size=(3,), stride=(1,), padding=(1,)) (conv1_2): Conv1d(64, 128, kernel_size=(3,), stride=(1,), padding=(1,)) (lstm1): LSTM(18, 64, batch_first=True) (lstm2): LSTM(64, 128, batch_first=True) (multi_attn): MultiheadAttention( (out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True) ) (layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True) (global_max_pool): AdaptiveMaxPool1d(output_size=1) (dense): Linear(in_features=256, out_features=128, bias=True) (tanh): Tanh() ) Extracted Features shape: torch.Size([32, 128])
代码解释:
这段代码定义了一个名为 FeatureExtractor 的特征提取器,它使用 PyTorch 构建。这个提取器包含以下几个主要组件:
-
卷积层 (Convolutional Layers):
-
(conv1_1): Conv1d(18, 64, kernel_size=(3,), stride=(1,), padding=(1,)):第一个一维卷积层。输入通道数为 18,输出通道数为 64,卷积核大小为 3,步长为 1,填充为 1。这意味着它处理的是 18 个特征的序列数据。 -
(conv1_2): Conv1d(64, 128, kernel_size=(3,), stride=(1,), padding=(1,)):第二个一维卷积层。输入通道数为 64,输出通道数为 128,卷积核大小、步长和填充与第一个卷积层相同。卷积层用于提取输入数据中的局部特征。
-
-
LSTM 层 (Long Short-Term Memory Layers):
-
(lstm1): LSTM(18, 64, batch_first=True):第一个 LSTM 层。输入维度为 18,隐藏层维度为 64。batch_first=True表示输入数据的第一个维度是 batch size。LSTM 层用于捕捉序列数据中的长期依赖关系。 -
(lstm2): LSTM(64, 128, batch_first=True):第二个 LSTM 层。输入维度为 64,隐藏层维度为 128。同样使用batch_first=True。
-
-
多头注意力机制 (Multi-head Attention):
-
(multi_attn): MultiheadAttention(...):多头注意力机制。它将来自 LSTM 层的输出进行处理,捕捉不同位置之间的关系。 -
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True): 注意力机制的输出投影层,将输出维度映射回 256。
-
-
层归一化 (Layer Normalization):
-
(layer_norm): LayerNorm((256,), ...):对注意力机制的输出进行层归一化,有助于训练稳定。
-
-
全局最大池化 (Global Max Pooling):
-
(global_max_pool): AdaptiveMaxPool1d(output_size=1):对特征序列进行全局最大池化,将每个通道的最大值提取出来,得到一个固定长度的向量。
-
-
全连接层 (Dense Layer):
-
(dense): Linear(in_features=256, out_features=128, bias=True):一个线性层,将全局最大池化的输出映射到 128 维。
-
-
激活函数 (Activation Function):
-
(tanh): Tanh():使用 tanh 激活函数。
-
输出形状解释:
Extracted Features shape: torch.Size([32, 128])
这个输出形状表示提取出的特征的维度。
-
32:这是 batch size。这意味着模型一次处理 32 个样本。 -
128:这是每个样本的特征向量的维度。每个样本经过特征提取器后,被表示为一个 128 维的向量。
总结:
这个 FeatureExtractor 模块结合了卷积层、LSTM 层、多头注意力机制和全局最大池化等技术,用于从序列数据中提取有用的特征。最终输出的特征形状为 (batch_size, feature_dimension),在这个例子中是 (32, 128)。 这个模块的设计目标是学习到输入序列数据的丰富表示,供后续的任务(如分类、回归等)使用。
自编码器
import torch
import torch.nn as nn
class Decoder(nn.Module):
def __init__(self, latent_dim=128, seq_len=60, output_dim=18):
super(Decoder, self).__init__()
self.dense = nn.Linear(latent_dim, seq_len * latent_dim)
self.seq_len = seq_len # 保存 seq_len,后面 reshape 要用
self.lstm1 = nn.LSTM(latent_dim, 64, batch_first=True)
self.lstm2 = nn.LSTM(64, output_dim, batch_first=True)
def forward(self, x):
d = self.dense(x)
d = torch.relu(d)
# 使用 torch.reshape() 或者 tensor.view() 进行 reshape
d = torch.reshape(d, (-1, self.seq_len, latent_dim)) # 或者 d = d.view(-1, self.seq_len, latent_dim)
d, _ = self.lstm1(d)
d, _ = self.lstm2(d)
return d
# Example usage (replace 128 with your actual latent dimension)
latent_dim = 128
decoder = Decoder(latent_dim=latent_dim)
# Example input (replace with your actual data)
batch_size = 32
input_tensor = torch.randn(batch_size, latent_dim) # Latent vector input
# Get decoder output
output = decoder(input_tensor)
print("Decoder output shape:", output.shape) # Should be (batch_size, 60, 18)
# You can now integrate this decoder with your encoder to form the autoencoder运行结果:
Decoder output shape: torch.Size([32, 60, 18])
在特征提取模型后面添加自编码器,通常是为了进一步提炼特征、进行数据降维或用于特定的应用场景。以下是一些常见的理由:
1. 进一步提炼特征:
-
增强特征表达能力: 特征提取模型可能已经提取了数据的关键特征,但自编码器可以通过学习数据的潜在表示,进一步提炼这些特征,使其更具有表达能力。自编码器可以捕捉到数据中更细微的结构和模式,从而提高特征的鲁棒性和泛化能力。
-
去除冗余信息: 特征提取模型提取的特征可能包含一些冗余信息,自编码器可以通过压缩和重建数据的过程,去除这些冗余信息,提取出更精简、更有效的特征。
2. 数据降维:
-
降低计算复杂度: 如果特征提取模型输出的特征维度较高,可能会增加后续模型(如分类器、回归器等)的计算复杂度。自编码器可以将高维特征压缩成低维表示,降低计算复杂度,提高模型的训练速度和效率。
-
减少过拟合风险: 高维特征容易导致过拟合,自编码器通过降维可以减少过拟合的风险,提高模型的泛化能力。
3. 特定应用场景:
-
自监督学习: 自编码器是一种自监督学习模型,可以通过重构原始数据来学习数据的特征。这种自监督学习方式可以利用大量无标签数据,提高模型的性能。
-
异常检测: 自编码器可以学习正常数据的表示,对于异常数据,自编码器很难将其完美重建。因此,可以通过重建误差来检测异常数据。
-
生成模型: 一些高级的自编码器(如变分自编码器 VAE)可以用于生成新的数据样本。
举例说明:
假设你正在处理图像分类任务。你首先使用卷积神经网络(CNN)作为特征提取模型,提取图像的特征。然后,你在 CNN 后面添加一个自编码器。
-
进一步提炼特征: 自编码器可以学习 CNN 提取的特征的潜在表示,进一步提炼图像的特征,使其更具有表达能力,从而提高分类的准确率。
-
数据降维: 如果 CNN 输出的特征维度较高,自编码器可以将其压缩成低维表示,降低后续分类器的计算复杂度。
-
自监督学习: 你可以使用大量的无标签图像来训练自编码器,提高 CNN 的特征提取能力。
总结:
在特征提取模型后面添加自编码器,可以进一步提炼特征、进行数据降维或用于特定的应用场景。具体是否需要添加自编码器,取决于具体的任务和数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









