



今天我们来聊的就是MOE
什么是混合专家( MoE )?
专家混合( MoE )是一种机器学习框架,类似于一个专家团队,每个专家都擅长处理复杂任务的不同方面。
这就像将一个大问题分成更小、更易于管理的部分,并将每个部分分配给不同的专家。
从技术上讲,它是 Transformer 架构的一种变体,它引入了一个新的 MoE 块,该块包含多个专家(网络/ FFN ),前面有一个门控函数,用于决定传入的令牌必须路由到哪个专家!
﹣专家:专家可以是基本的前馈网络,也可以是 LLM 本身。
﹣门/路由器:在 MoE 块中,门控函数 GATE (.)使用 softmax 来衡量每个专家的传入 token 处理能力。
他们有何特别之处?
﹣它让我们拥有专业的专家。一位专家可能擅长编码,另一位专家擅长数学,还有一位专家擅长写作。
﹣每个专家可以并行分布在多个 GPU 上,从而加快推理速度
-由于每个 token 都有自己的专家(或前 k 名专家)进行处理,因此我们在技术上添加了更多可学习的参数,而不会影响推理成本!!!
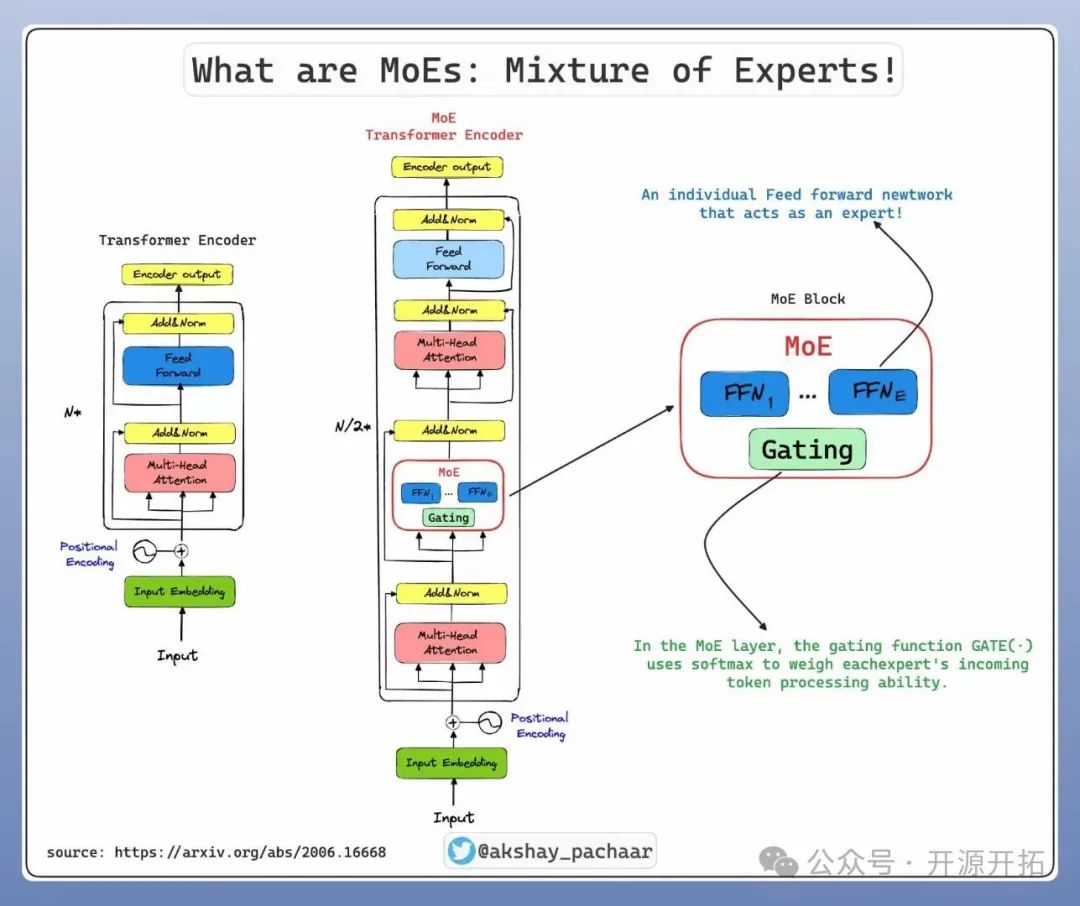
MoE(Mixture-of-Experts,专家混合),首次出现于1991年的论文Adaptive Mixture of Local Experts中,其前身是“集成学习”(Ensemble Learning),作为一种由专家模型和门控模型组成稀疏门控制的深度学习技术,MoE由多个子模型(即专家)组成,每个子模型都是一个局部模型,专门处理输入空间的一个子集。
在“分而治之”的核心思想指导下,MoE 使用门控网络来决定每个数据应该被哪个模型去训练,从而减轻不同类型样本之间的干扰。
通俗来讲,MoE就像复仇者联盟,每个子模型(专家)都是一个超级英雄,门控网络则是尼克·弗瑞,负责协调各个超级英雄,决定在什么情况下召唤哪位英雄。门控网络会根据任务的特点,选择最合适的专家进行处理,然后将各位专家的输出汇总起来,给出最终的答案。
门控功能“稀疏性”的引入让MoE在处理输入数据时只激活使用少数专家模型,大部分专家模型处于未激活状态。换言之,只有擅长某一特定领域的超级英雄会被派遣,为用户提供最专业的服务,而其他超级英雄则原地待命,静待自己擅长的领域到来。这种“稀疏状态”作为混合专家模型的重要优势,进一步提升了模型训练和推理过程的效率。
MoE的加入让整个神经网络系统就像一个大型图书馆,每层都有不同类型的书籍和专业的图书管理员,门控系统(图书馆的智能导引系统)会根据读者的不同需求,将他们引导至最合适的楼层(多层网络中的某一层级),而这一过程也不断根据数据特点进行实时动态处理。
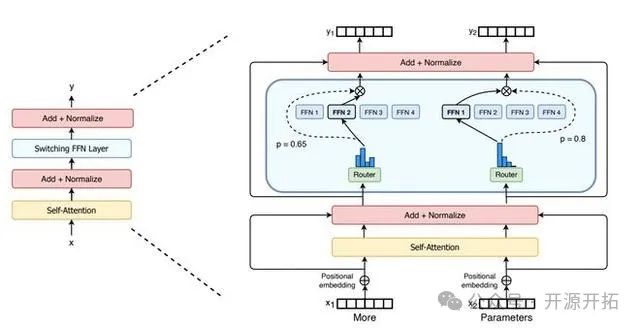
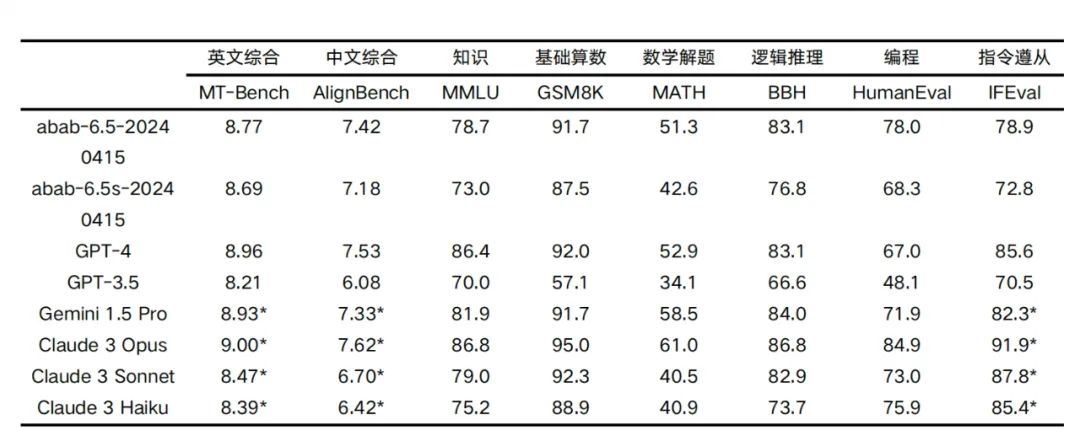
目前小余哥所了解的国内的大模型里面只有深度求索公司的DeepSeek-V2和miniMax公司的大模型具备MOE。
在这里不得不提一下miniMax公司的大模型目前是国内唯一一个万亿参数级别的大模型
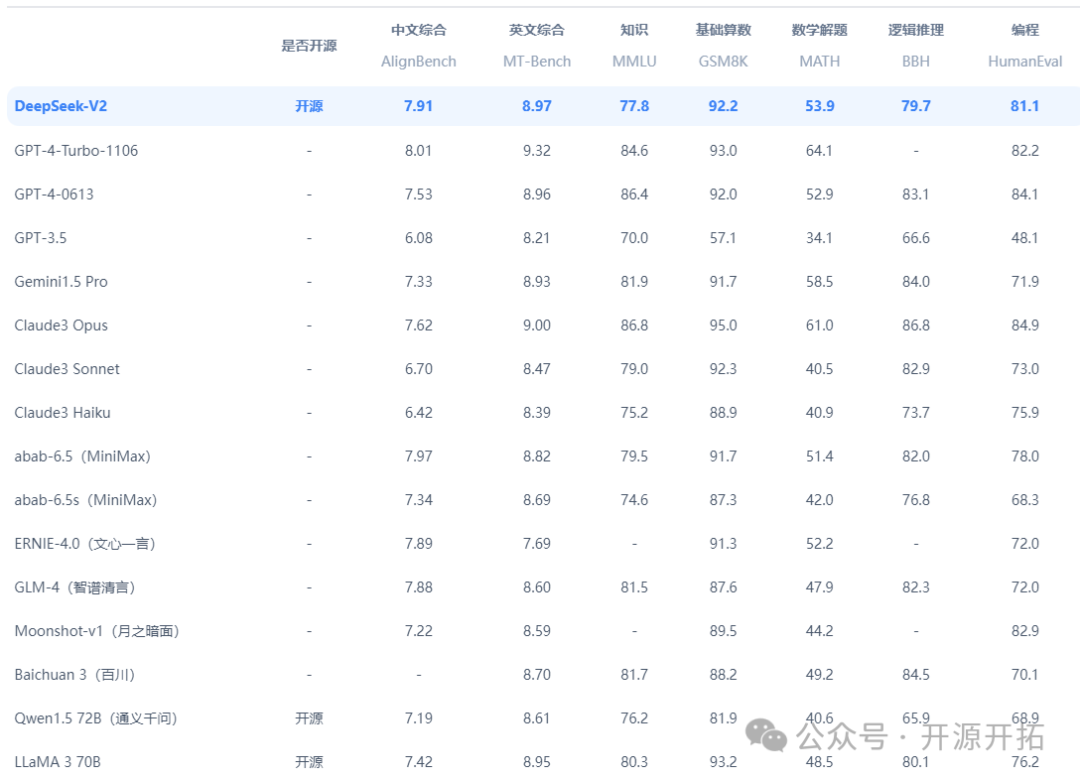
而深度求索公司也是在最近开源出了2千亿的MOE底座大模型,深度求索公司目前是全国范围内开源参数级别最大的一个公司,他们的DeepSeek-V2中文理解能力已经超越了GPT-4.0。
如果你也对大模型感兴趣欢迎关注下方公众号!!!

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









