



铁子们!牛回速归!!!
第一次见到交易所崩了,以前都是同花顺或者券商出故障
交易所今天最开始无法撤单,后面就直接无法交易了,所有股票拉成一条线了
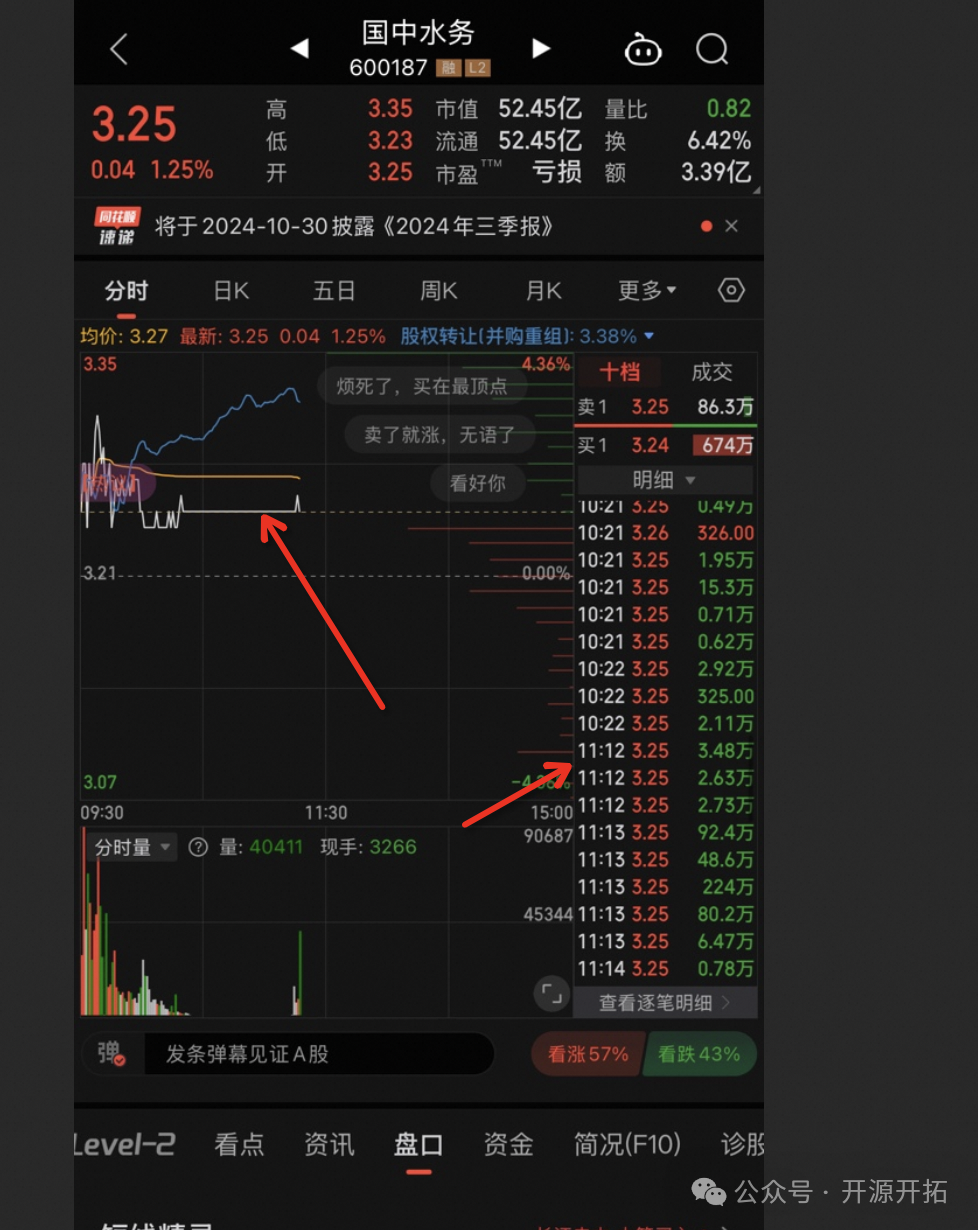
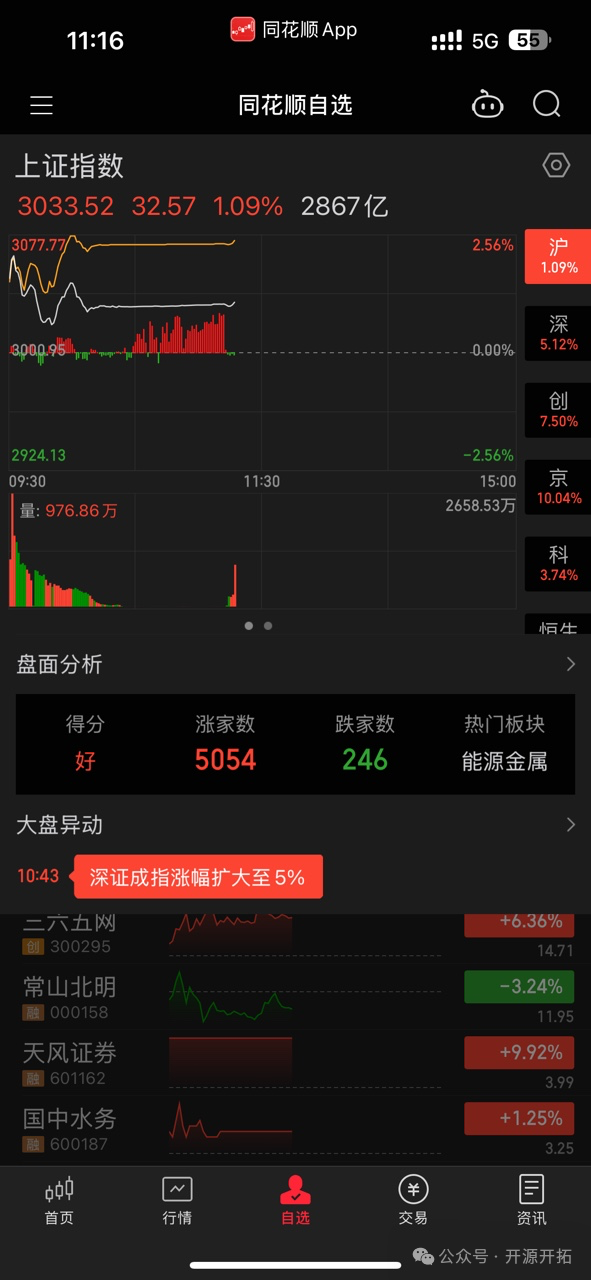
50 分钟故障处理完成,这在阿里估计一排的开发都凉了~又有开发要背锅咯~
铁子们!牛回速归!!!
第一次见到交易所崩了,以前都是同花顺或者券商出故障
交易所今天最开始无法撤单,后面就直接无法交易了,所有股票拉成一条线了
50 分钟故障处理完成,这在阿里估计一排的开发都凉了~又有开发要背锅咯~

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 7955
7955





