



作者:皮皮关
来源:zhihu.com/question/50076174/answer/1101330430
经常看到有同学在抱怨现在的游戏、APP占用非常大的空间,基本都是 10G 起步。
在网上看到一个问题:
为什么魂斗罗只有 128KB 却可以实现那么长的剧情呢?
这篇文章将会给大家讲讲这里面的奥秘~
正文

现代程序员 A 和 1980 年代游戏程序员 B 的对话:
A:为什么你用 128KB 能实现这么多画面、音乐、动画?
B:128KB 还不够么?其实为了表现力已经相当奢侈了,加了很多不重要的细节。
A:就说你们的音乐,这个音乐,我压到最低码率的 mp3,也得至少 1MB 吧。
B:你怎么压的?一首背景音乐怎么可能超过 1KB。
A:那你实现全屏卷轴,用了多少显存?
B:一共就只有 2KB 显存,多了也放不下啊。
A:……
我们对“数据量”无法直观认识
除非是专家,一般人根本无法估算到底多大算大,多小算小。
一般人对“数据量”并没什么概念。一篇 800 字的作文有多少数据量?按照 GBK 编码,约 1.6KB,按照 UTF-8 编码,则是 2.4KB。
只写了 1 个字的作文,按理来说 1 字节~3 字节就够了。但只写 1 个字的 word 文档,有 10956 字节,而由于硬盘格式化要求,再多占用 1332 字节

我就写了一个字,真的什么都没干
现实中常见的产品、流行的技术,实际上和时代背景密切相关。
当你抱着 15 寸笔记本还嫌小的时候,1990 年代初的家庭,可是一家人围着 14~18 寸的球面电视看的。把雪碧拿给古代人喝一口,估计他会齁得要死,必须喝点水压压惊。

当物质基础变得十分丰富的时候,一定会产生无法避免的“浪费”,这种“浪费”会进一步改变人感受的阈值,对度量的估计都变得紊乱了。
FC 时代的图形技术
由于早期的记忆芯片(ROM)非常贵,而且大容量磁盘的技术也不成熟,所以暂且不论硬件计算能力,仅仅是想增加游戏的总容量也非常困难。所以自然会使用符合当时水平的数据结构。
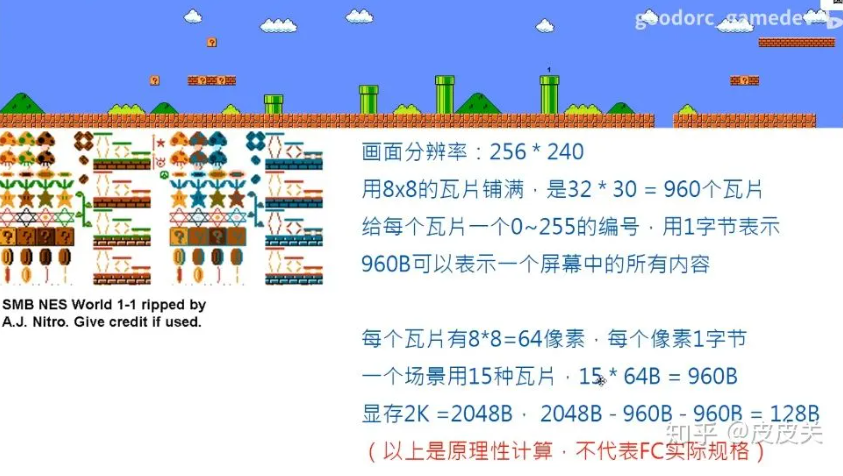
以红白机 FC 为例,它的分辨率为 256x240。分辨率不算低,但却只有 2KB 显存,而且还要实现全屏卷轴效果。
所以在 FC 设计之初,从硬件上就提供了充分利用显存的方法——使用 Tile(瓦片)。
对每一个场景来说,使用若干数量的瓦片,场景用有限的瓦片拼接即可。这种“二级”表示方法能极大节约存储量。
具体一些原理讲解可以看一些科普,比如这个:
https://www.bilibili.com/video/BV19J411e763
音频容量和代码容量
现代音乐格式往往直接保存声道的波形,这种做法保真度高、通用性强,但很显然占用空间多,一首曲子的容量以千字节、兆字节计算。
而八位芯片时代的音频解决方案,关键是一颗专用芯片,例如 FC 用的理光 2A03:

下:理光 2A03
音频芯片可以产生合成音效,能提供的音色可以在一定程度上配置,但非常有限。听听 FC 游戏的音乐可以体会到常用的音色几乎一样。
我觉得这个音频芯片最厉害的地方是可以同时播放几个音轨(但不能是和弦那种“同时”),《魂斗罗》、《沙罗曼蛇》、《忍者龙剑传》的殿堂级音乐,主要是靠多个音轨的交替配合实现的。
每个音符只要记录音色、频率和音高就足够了,音频芯片自然会识别出来。把音符按时间排列好就是“乐谱”了,可以简单理解为“简谱”。
这种简谱需要的数据量十分有限,而且大部分游戏音乐都是循环播放,数据量更是小的可怜。
代码也是类似的
FC 时代的游戏,没有所谓的“引擎层”,或者说引擎层就是“硬件层”。任天堂的主机完全是为游戏而设计的,瓦片、调色板、音乐、音效等基本功能已经预先考虑到了,这样一来就节约了大量底层代码。
程序员要仔细研究文档,在硬件框架下思考问题,比如如何显示图片、如何卷动屏幕等等;而且还要非常熟悉硬件底层和汇编,不要浪费代码空间。
一来二去,代码也能写的非常小。
总的来说,128KB 的游戏大作,在 30 年前稀松平常,放到现在简直就是黑科技。

科技的剧烈变革带来技术指标非线性的变化,让我们的记忆和直觉彻底落伍 :)

















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









