






matplotlib可视化图形类型及运用(基于dataframe和series)
1.柱状图
单比例
df.pyplot.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwarg)
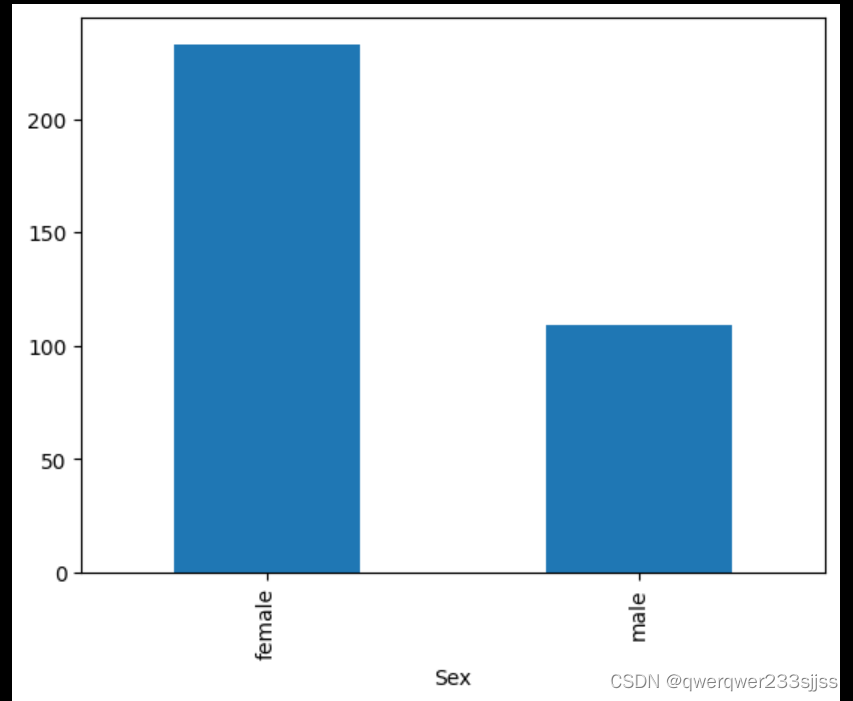
sex_sur
Sex
female 233
male 109
Name: Survived, dtype: int64 (series)
sex_sur.plot.bar()
(可视化)
多比例
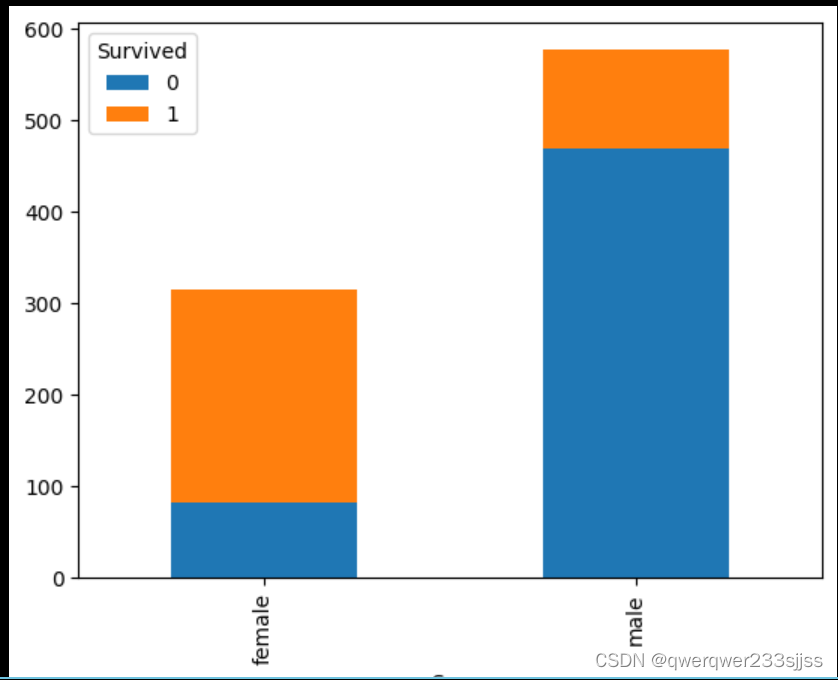
s_d_sex = data.groupby(['Sex','Survived'])['Survived'].count().unstack()
#构建dataframe
Survived 0 1
Sex
female 81 233
male 468 109
s_d_sex.plot.bar(stacked=True)
#可视化
stacked代表按比例,将两个列索引代表的值,显示在一个柱子上
这里解释下:
对于groupy分组操作进行完成后,得到的是一个类dataframe的groupy类型数据,进行count操作后,数据变为series类型,unstack操作过后,数据变为dataframe类型!
2.折线图
dataframe.plot.line( )
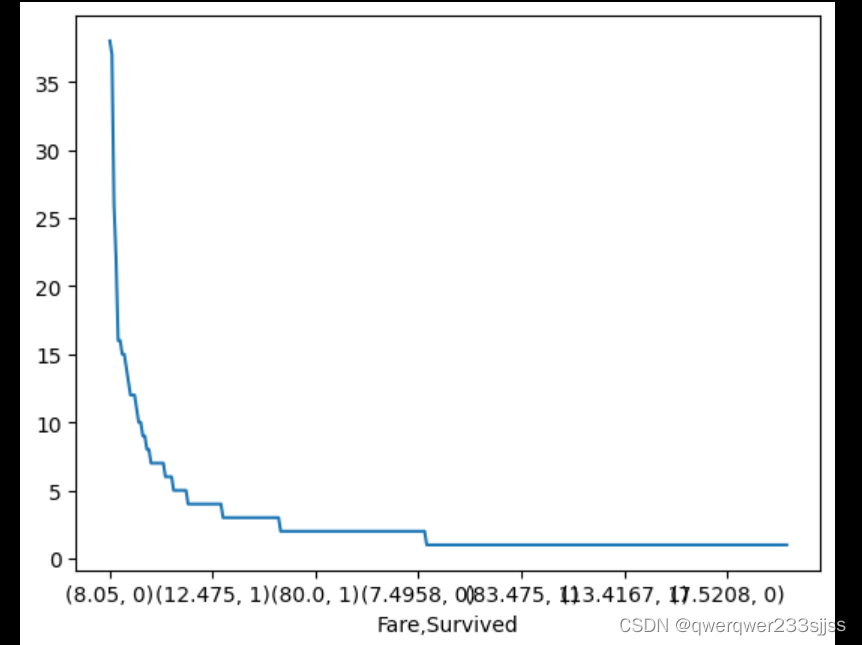
df = data.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
#构建数据
Fare Survived
8.0500 0 38
7.8958 0 37
13.0000 0 26
7.7500 0 22
13.0000 1 16
..
7.7417 0 1
26.2833 1 1
7.7375 1 1
26.3875 1 1
22.5250 0 1
Name: count, Length: 330, dtype: int64
这里有几个函数需要解释下:
value_counts() 这个函数是对于groupby操作完后的数据,进行对于Survivied(0或1)进行统计(也就是统计对于每一个Fare,0和一各有多少个)。这类似于把Fare和Survived都作为分类标准进行分类!
sort_values()这个函数是以0和1后面的值,把整个表进行排序进行排序(这个函数是默认升序排序的,那ascending自然就是降序排序啦!)
3.seaborn画核密度曲线图
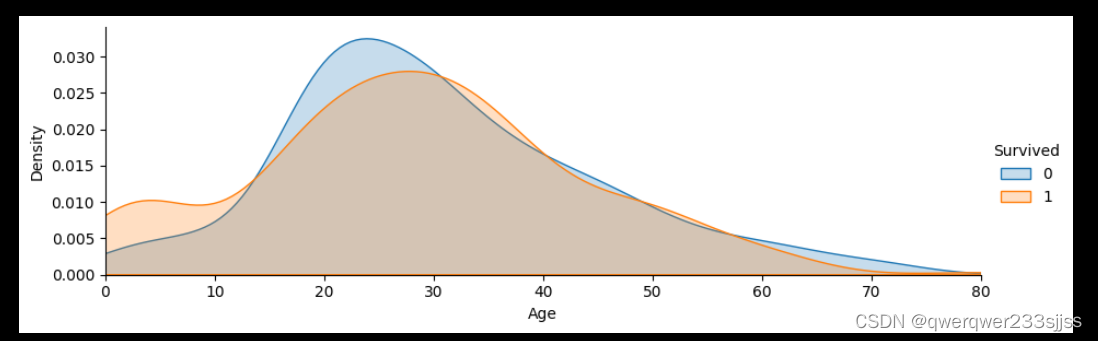
import seaborn as sns # 导入seaborn库
face = sns.FacetGrid(data,hue='Survived',aspect=3) # 创建一个分面网格图,并添加一个核密
# 度估计图,数据集为data,以'Survived'列的值进行分类,分面长宽比例为3
face.map(sns.kdeplot,'Age',shade=True) # 添加一个核密度估计图,展示'Age'列的数据分布
# shade 核密度图旁边添加颜色条,展示每个分面各个值的相对密度
face.set(xlim=(0,data['Age'].max())) # 设置网格图x轴的范围
face.add_legend() #标识每个和密度估计图的颜色代表的含义
4.matplotlib画核密度曲线图
data.Age[data.Pclass==1].plot.kde() # 选择年龄(条件是对应的Pclass为1)数据绘制该数据的和密度估计图
data.Age[data.Pclass==2].plot.kde()
data.Age[data.Pclass==3].plot.kde()
plt.xlabel('age') # 设置x轴标签轴为年龄
plt.legend((1,2,3),loc="best") # 添加图例,数字123分别代表Pclass123,loc参数设置为best表示
# 图例将自动设置为最佳位置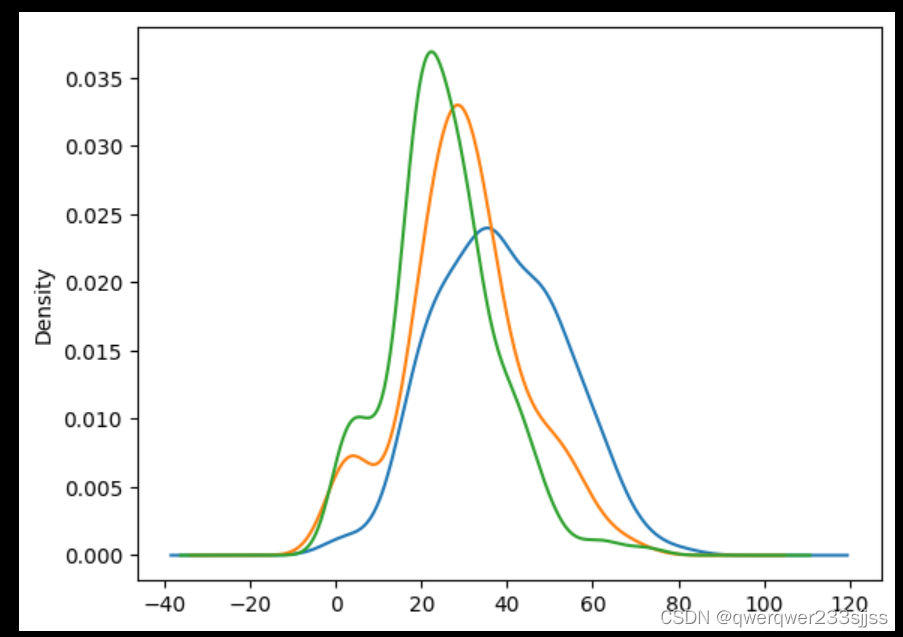
核密度曲线,是针对一个数据集进行画图,统计它每个阶段所占全部阶段的比例,然后按密度的计算方式,密度大的地方曲线陡,密度小的地方曲线较平缓。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









