






1.1.1导入数据
import pandas as pd
file = dp.read_scv('train.csv')1.1.2对数据模块进行逐块读取
【思考】什么是逐块读取?为什么要逐块读取呢?
逐块读取:有chunksize参数可以进行逐块加载。它的本质就是将文本分成若干块,每次处理chunksize行的数据,最终返回一个TextParser对象,对该对象进行迭代遍历,可以完成逐块统计的合并处理。
这里查询到pandas的read_csv()提供了chunk分块读取能力
chunk用法: (这里以一千行为一个数据模块)
方法一:for循环
chunker = pd.read_csv('tain.csv',chunksize=10000)
for chunk in chunker:
print(chunk)方法二:get_chunk()
df = pd.read_csv('train.csv',chunksize=1000)
df.get_chunk()1.1.3修改表头和索引
#df1 = pd.read_csv('train.csv')函数默认情况下,会把数据内容的第一行默认为字段名标题。
这里以修改一段英文表头为中文为实例
思路是我们给它加列名或者让它以为没有列索引
#df1 = pd.read_csv('train.csv',header=None)
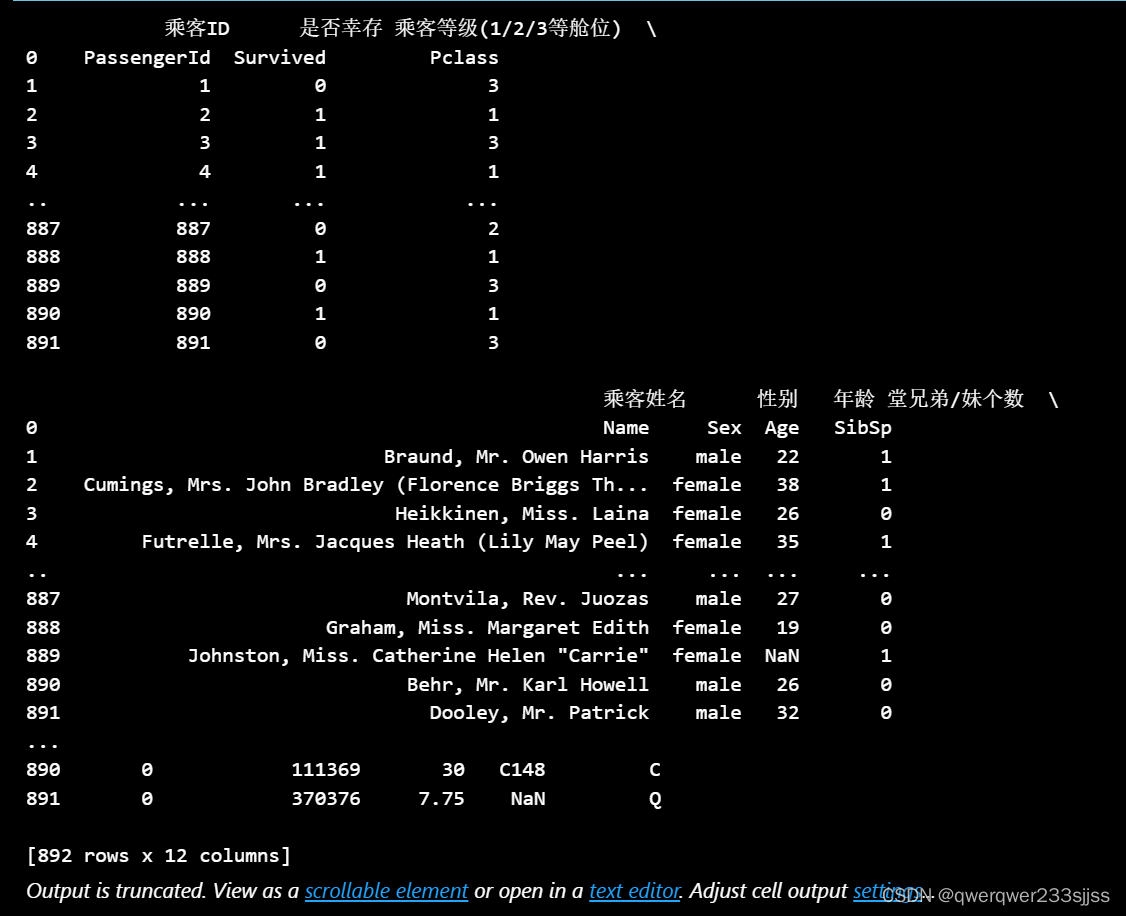
names = ['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别','年龄','堂兄弟/妹个数','父母与小孩个数','船票信息','票价','客舱','登船港口']
df2 = pd.read_csv('train.csv',name=names)df1让它以为没有列索引
df2我们给它传递一个列表,里面是列表头名
打印出来就是这样
1.2初步观察
1.2.1查看数据基本信息
这里查到有多个函数可以使用
df.info(): # 打印摘要
df.describe(): # 描述性统计信息
df.values: # 数据 <ndarray>
df.to_numpy() # 数据 <ndarray> (推荐)
df.shape: # 形状 (行数, 列数)
df.columns: # 列标签 <Index>
df.columns.values: # 列标签 <ndarray>
df.index: # 行标签 <Index>
df.index.values: # 行标签 <ndarray>
df.head(n): # 前n行
df.tail(n): # 尾n行
pd.options.display.max_columns=n: # 最多显示n列
pd.options.display.max_rows=n: # 最多显示n行
df.memory_usage(): # 占用内存(字节B)
describe() #进一步观察数据的分布情况,该函数可以帮助我们计算每列数据的分布以及平均值等内容。1.2.2观察表格前10行和后15行数据
df2.head(10)
df2.tail(15)1.2.4判断数据是否为空,为空的地方返回True,其余地方返回False
print(df2.isnull()) # 是空值返回True,否则返回False1.3保存数据
data=df2.to_csv('edited_train.csv',encoding='utf_8_sig')
# 注意:不同的操作系统保存下来可能会有乱码,可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘来防止乱码!
1.4pandas
1.4pandas数据类型:Datafrmae和Series
series
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
pandas.Series( data, index, dtype, name, copy)
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False。
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)#写入代码
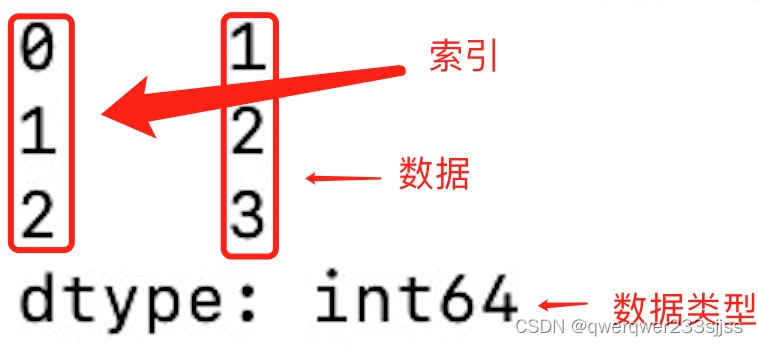
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
print(myvar[1])我们还可以指定索引:pd.Series(a, index = ["x", "y", "z"]) 使用series的index参数
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)我们也可以使用键值对来创建series:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
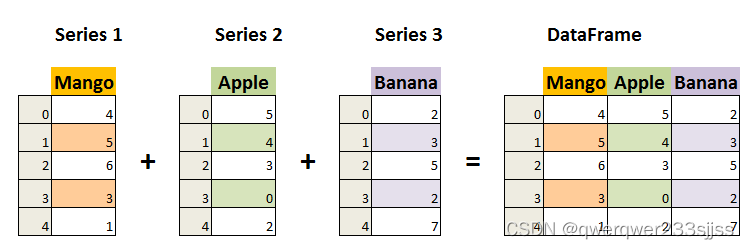
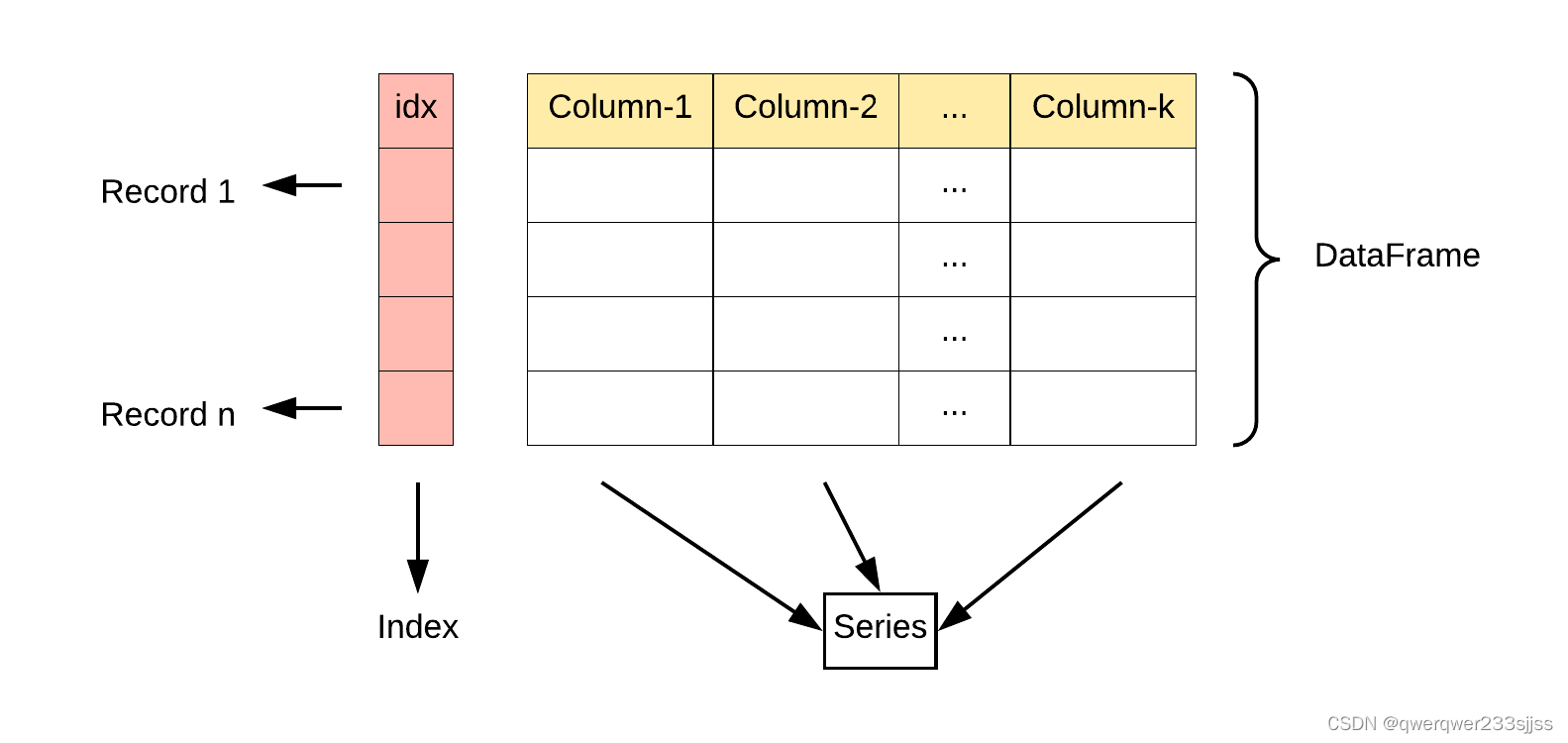
Dataframe
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
列和行:
DataFrame由多个列组成,每一列都有一个名称,可以看作是一个Series。同时,DataFrame有一个行索引,用于标识每一行。二维结构:
DataFrame是一个二维表格,具有行和列。可以将其视为多个Series对象组成的字典。列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
pandas.DataFrame( data, index, columns, dtype, copy)参数说明
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
dataframe创建
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
df1
lkey value
0 foo 1
1 bar 2
2 baz 3
3 foo 5
df2
rkey value
0 foo 5
1 bar 6
2 baz 7
3 foo 81.4.3查看DataFrame数据的每行每列的名称
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1......
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
#使用字典方式建立Dataframe对象
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])直接使用 表单名[colum值] 可以获取某列的数值:
titanic = pd.read_csv("data/titanic.csv")
titanic.head()
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
我对泰坦尼克号乘客的年龄很感兴趣:
ages = titanic["Age"]
ages.head()
Out[5]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
我对泰坦尼克号乘客的年龄和性别很感兴趣:
age_sex = titanic[["Age", "Sex"]]
age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male还可以使用条件获取指定要求的物品信息:
我对 35 岁以上的乘客感兴趣:
above_35 = titanic[titanic["Age"] > 35]
above_35.head()
Out:
PassengerId Survived Pclass ... Fare Cabin Embarked
1 2 1 1 ... 71.2833 C85 C
6 7 0 1 ... 51.8625 E46 S
11 12 1 1 ... 26.5500 C103 S
13 14 0 3 ... 31.2750 NaN S
15 16 1 2 ... 16.0000 NaN S
titanic["Age"] > 35
Out:
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool1.4.5过指定标签名称和相应的标签名称来删除行或列
df = pd.DataFrame(np.arange(12).reshape(3, 4),
columns=['A', 'B', 'C', 'D'])
df
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
下面来删除B,C列:使用
df.drop(['B', 'C'], axis=1)
或者
df.drop(columns=['B', 'C'])
变成:
A D 0 0 3 1 4 7 2 8 11
删除行:
df.drop([0, 1]) 变成: A B C D 2 8 9 10 11
如果想要完全的删除你的数据结构,使用inplace=True
比如:
df.drop(columns=['B', 'C'],inplac=True)
1.5.2使用交集和并集操
1.5.3查看具体数据值
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000}]
df = pd.DataFrame(mydict)
df
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000方法一:iloc()
访问索引
df.iloc[0]
a 1
b 2
c 3
d 4
Name: 0, dtype: int64
df.iloc[[0, 1]]
a b c d
0 1 2 3 4
1 100 200 300 400访问切片
df.iloc[:3]
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000标量访问
df.iloc[0, 1]
返回:
2列表访问
df.iloc[[0, 2], [1, 3]]
b d
0 2 4
2 2000 4000
df.iloc[1:3, 0:3]
a b c
1 100 200 300
2 1000 2000 3000方法2:loc()
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8单个标签:这会将该行作为 Series 返回。
df.loc['viper']
max_speed 4
shield 5
Name: viper, dtype: int64标签列表:返回一个dataframe
df.loc[['viper', 'sidewinder'],['shield']]
shield
viper 5
sidewinder 81.6处理数据
1.6.1利用pandas对数据进行排序
创建dataframe
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=[2,1] :DataFrame 对象的索引列
columns=['d', 'a', 'b', 'c'] :DataFrame 对象的索引行
创建dataftame:
np.arange(8).reshape((2, 4))
index=[2,1,4,3,5]
columns=['d', 'a', 'b', 'c','e']
frame = pd.DataFrame(np.arange(25).reshape((5, 5)),index=index,columns=columns)
frame.sort_values(by='a',ascending=False)
d a b c e
5 20 21 22 23 24
3 15 16 17 18 19
4 10 11 12 13 14
1 5 6 7 8 9
2 0 1 2 3 4让行索引为'a'的一列进行升序排序
sort_value(by, *, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)z这边是sort_value()函数的参数
frame.sort_values(by='a',ascending=False) #对a这列进行降序排序注意:ascending为False时按照降序排列,为True时按升序排列
按照某第五行行进行排序
frame.sort_index(by=5)将行索引升序排列
frame.sort_index()
d b a c e
1 5 6 7 8 9
2 0 1 2 3 4
3 15 16 17 18 19
4 10 11 12 13 14
5 20 21 22 23 24让列索引升序排序
frame.sort_index(axis=1)
a b c d e
2 2 1 3 0 4
1 7 6 8 5 9
4 12 11 13 10 14
3 17 16 18 15 19
5 22 21 23 20 24让列索引降序排序
frame.sort_index(axis=1,ascending=False)
e d c b a
2 4 0 3 1 2
1 9 5 8 6 7
4 14 10 13 11 12
3 19 15 18 16 17
5 24 20 23 21 22注意:axis为1,表示是列索引

















 3407
3407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









