



 本文介绍了一种名为Selective Kernel Networks的新型卷积神经网络结构。该网络通过Split、Fuse和Select三个步骤来提升模型的灵活性与表现力。文章详细阐述了SKNet的工作原理,并提供了其PyTorch实现代码。
本文介绍了一种名为Selective Kernel Networks的新型卷积神经网络结构。该网络通过Split、Fuse和Select三个步骤来提升模型的灵活性与表现力。文章详细阐述了SKNet的工作原理,并提供了其PyTorch实现代码。
论文链接:Selective Kernel Networks
code:Selective Kernel Networks
模块结构
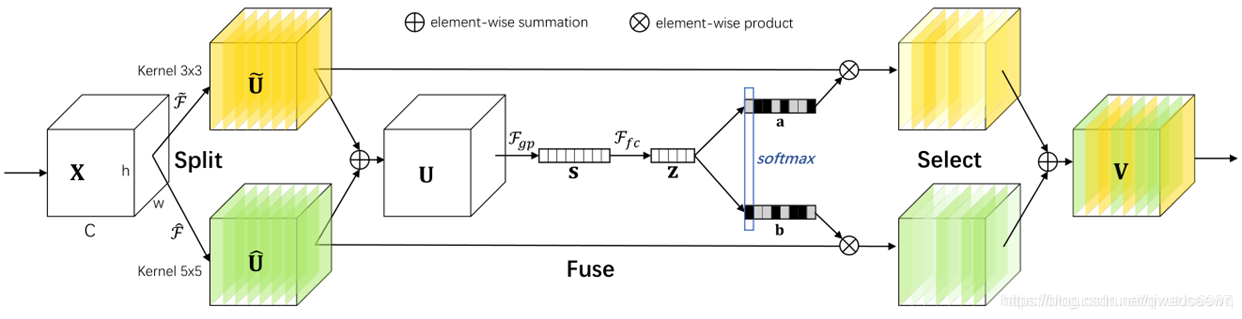
网络主要分为Split,Fuse,Select三个操作
1.Split
对X进行Kernel3×3和Kernel5×5的卷积操作,得到两个输出
2.Fuse
![]()
Ffc为先降维再升维的两层全连接层。输出的两个矩阵a和b,其中矩阵b为冗余矩阵,在如图两个分支的情况下b=1-a
3.Select
![]()
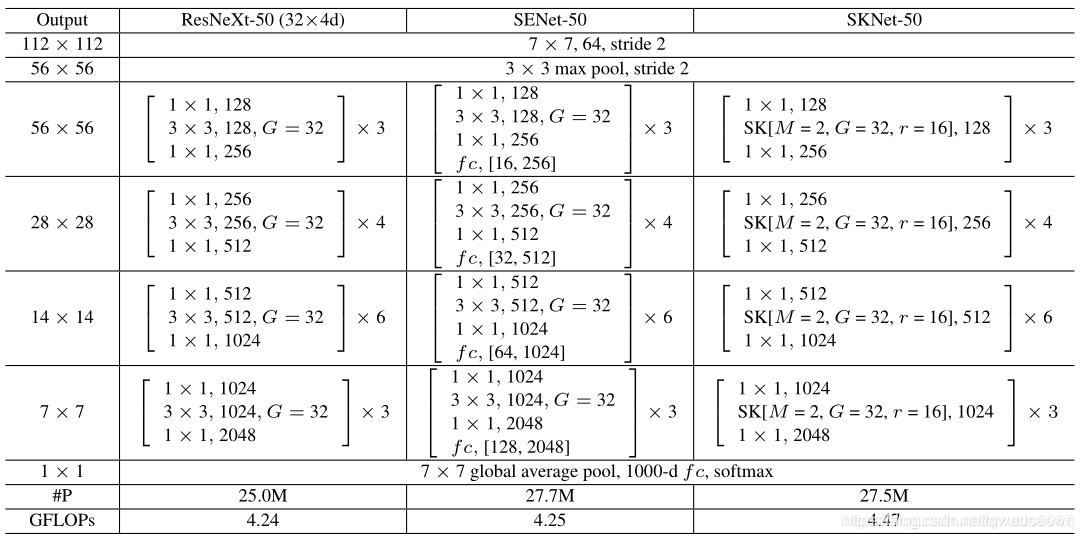
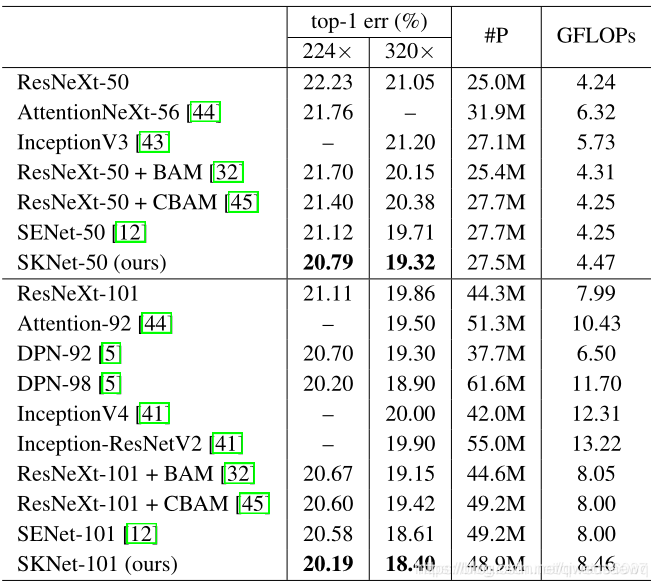
SKNet替代了ResNext中3*3卷积部分,用两个或多个不同卷积核大小的卷积操作 加学习通道权重全连接层替代。输出向量再继续进行1×1卷积操作
pytorch实现
import torch
from torch import nn
#被替换的3*3卷积
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1 ,L=32):
""" Constructor
Args:
features: input channel dimensionality.
WH: input spatial dimensionality, used for GAP kernel size.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features/r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3+i*2, stride=stride, padding=1+i, groups=G),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
self.gap = nn.AvgPool2d(int(WH/stride))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Linear(d, features)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
fea_s = self.gap(fea_U).squeeze_()
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector], dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
#新的残差块结构
class SKUnit(nn.Module):
def __init__(self, in_features, out_features, WH, M, G, r, mid_features=None, stride=1, L=32):
""" Constructor
Args:
in_features: input channel dimensionality.
out_features: output channel dimensionality.
WH: input spatial dimensionality, used for GAP kernel size.
M: the number of branchs.
G: num of convolution groups.
r: the radio for compute d, the length of z.
mid_features: the channle dim of the middle conv with stride not 1, default out_features/2.
stride: stride.
L: the minimum dim of the vector z in paper.
"""
super(SKUnit, self).__init__()
if mid_features is None:
mid_features = int(out_features/2)
self.feas = nn.Sequential(
nn.Conv2d(in_features, mid_features, 1, stride=1),
nn.BatchNorm2d(mid_features),
SKConv(mid_features, WH, M, G, r, stride=stride, L=L),
nn.BatchNorm2d(mid_features),
nn.Conv2d(mid_features, out_features, 1, stride=1),
nn.BatchNorm2d(out_features)
)
if in_features == out_features: # when dim not change, in could be added diectly to out
self.shortcut = nn.Sequential()
else: # when dim not change, in should also change dim to be added to out
self.shortcut = nn.Sequential(
nn.Conv2d(in_features, out_features, 1, stride=stride),
nn.BatchNorm2d(out_features)
)
def forward(self, x):
fea = self.feas(x)
return fea + self.shortcut(x)
class SKNet(nn.Module):
def __init__(self, class_num):
super(SKNet, self).__init__()
self.basic_conv = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64)
) # 32x32
self.stage_1 = nn.Sequential(
SKUnit(64, 256, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(256, 256, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(256, 256, 32, 2, 8, 2),
nn.ReLU()
) # 32x32
self.stage_2 = nn.Sequential(
SKUnit(256, 512, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(512, 512, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(512, 512, 32, 2, 8, 2),
nn.ReLU()
) # 16x16
self.stage_3 = nn.Sequential(
SKUnit(512, 1024, 32, 2, 8, 2, stride=2),
nn.ReLU(),
SKUnit(1024, 1024, 32, 2, 8, 2),
nn.ReLU(),
SKUnit(1024, 1024, 32, 2, 8, 2),
nn.ReLU()
) # 8x8
self.pool = nn.AvgPool2d(8)
self.classifier = nn.Sequential(
nn.Linear(1024, class_num),
# nn.Softmax(dim=1)
)
def forward(self, x):
fea = self.basic_conv(x)
fea = self.stage_1(fea)
fea = self.stage_2(fea)
fea = self.stage_3(fea)
fea = self.pool(fea)
fea = torch.squeeze(fea)
fea = self.classifier(fea)
return fea
if __name__=='__main__':
x = torch.rand(8,64,32,32)
conv = SKConv(64, 32, 3, 8, 2)
out = conv(x)
criterion = nn.L1Loss()
loss = criterion(out, x)
loss.backward()
print('out shape : {}'.format(out.shape))
print('loss value : {}'.format(loss))


















 3178
3178





 到【灌水乐园】发言
到【灌水乐园】发言







