



CLIP是一个神经网络,它使用自然语言来监督视觉训练,可以将它运用到任何视觉分类任务,具体的就是将类别的名字用自然语言进行描述,然后和图片一起进行混合编码,可以0样本学习(zero-shot learning)。值得注意的是,该神经网络并没有使用到标签,是自监督学习。
背景
SimCLR
自监督学习会涉及到对比学习的概念,SimCLR [1](A Simple Framework for Contrastive Learning of Visual Representations)是一种对比学习网络,可以对含有少量标签的数据集进行训练推理,它包含无监督学习和有监督学习两个部分。
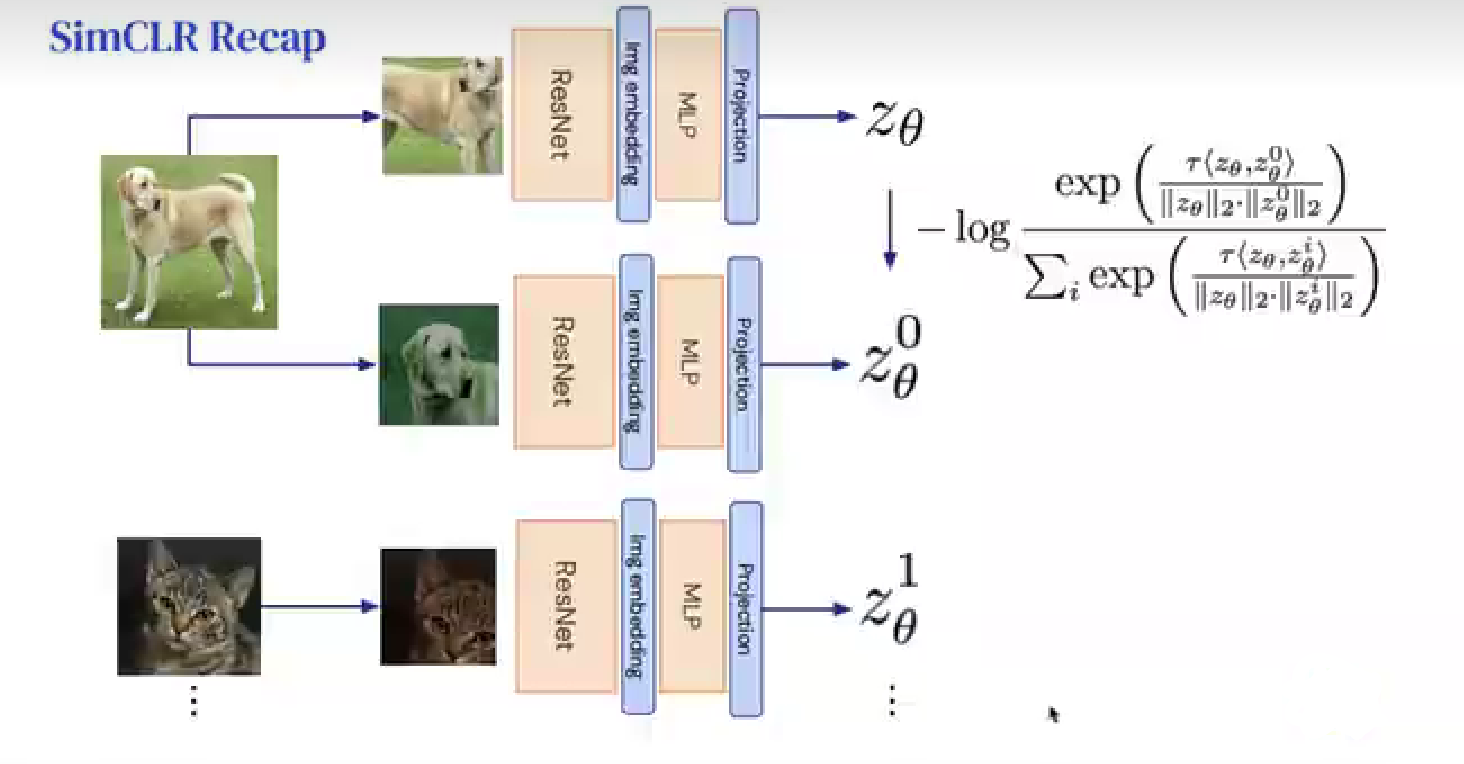
在第一阶段先进行无监督学习,对输入图像进行两次随机图像增强,即由一幅图像得到两个随机处理过后的图像,依次放入网络进行训练,计算损失并更新梯度。如图所示,将小狗进行了两次随机图像变换,再经过残差网络,进行图片编码,使用一个MLP(多层感知机)做预测或者投影到另外一个空间,进行横向比较,从同一个图像生成的结果相近,与猫对比,则相差较远,损失函数目的就是使得两个正样本距离更近([latex] z_{ \theta } [/latex],[latex] z_{\theta}^{0} [/latex]),与负样本之间的距离更远([latex] z_{ \theta } {1} [/latex])。第二阶段,加载第一阶段的特征提取层训练参数,用少量带标签样本进行有监督学习(只训练全连接层)。这一阶段损失函数为交叉熵损失函数CrossEntropyLoss[2]。
BYOL
再进一步发展,提出了一种新的自监督学习方法,BYOL(Bootstrap Your Own Latent)[3][4],和以往需要大量负样本的对比学习方法不同(SimCLR),BYOL不依赖于负样本对。
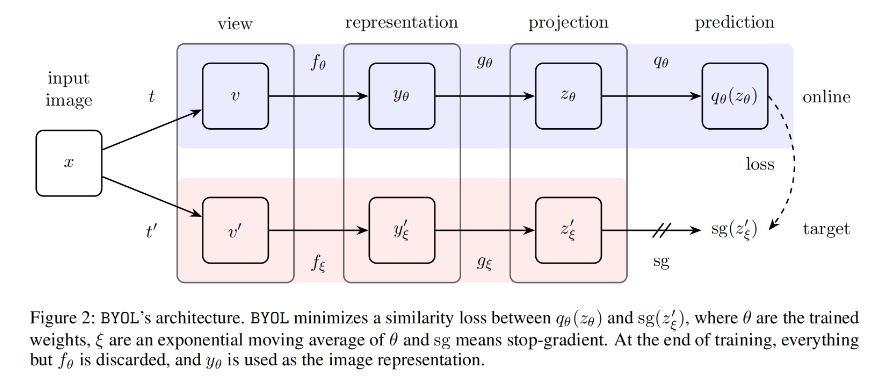
BYOL使用online和target两个神经网络来学习,online网络由一组权重定义并由三个阶段组成:encoder 、projector(投影到同一个空间) 、predictor 。target与online架构相同,但使用不同的参数。target提供了用于训练online的回归目标,其参数是online参数的指数移动平均值。学习loss的梯度只会反向传播给online网络,不会反向传播给target网络,类似于MoCo[5],target网络使用动量更新,相当于target模拟给online提供了一个负样本。(补充:为什么使用指数移动平均值,整体网络的不确定性很大,target和online同时学习,很快就会收敛,收敛到online和target结果一致,也就是模式崩塌,loss为0,然而并不希望出现这样的结果,通过降低学习的效率来避免这样的情况,也就是target不进行学习,target通过历史online进行慢慢的更新,online预测结果和target进行对比,计算损失,更新迭代)
CLIP
CLIP模型由图像编码器和文本编码器两个部分组成,图像编码器负责将图像转换为特征向量,可以是卷积神经网络或Transformer模型(ViT)[7],文本编码器负责将文本转换为特征向量,通常是一个transformer模型,通过共享一个向量空间来实现跨模态的信息交互。
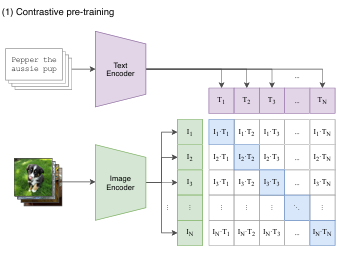
模型的输入是一个图片和文字的配对,图片输入到图片编码器,得到一个特征向量,文本会通过一个文本编码器,从而得到对应文本的特征向量。CLIP会在这些特征上做对比学习,配对的图片文本对就是正样本,在矩阵中对角线上的即正样本,有N个正样本,[latex]N^{2}-N[/latex]个负样本。
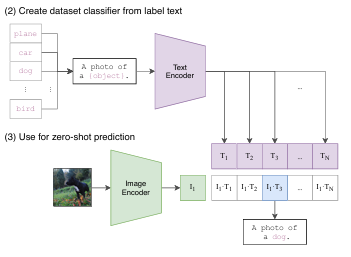
clip中没有分类头,进行预测的话,这里做了一个处理,就是将数据集中的类别描述成一个句子,以 ImageNet 为例,CLIP 先把 ImageNet 这1000个类(如图中"plane", “car”, “dog”, …, “brid”)变成一个句子,也就是将这些类别去替代 “A photo of a {object}” 中的 “{object}” ,以 “plane” 类为例,它就变成"A photo of a plane",那么 ImageNet 里的1000个类别就都在这里生成了1000个句子,然后通过先前预训练好的 Text Encoder 就会得到1000个文本的特征。
在推理时,只要把这张图片扔给 Image Encoder,得到图像特征后,就拿这个图片特征去跟所有的文本特征去做 cosine similarity(余弦相似度)计算相似度,看这张图片与哪个文本最相似,就把这个文本特征所对应的句子挑出来,从而完成分类任务。
参考
[1]SimCLR图像分类——pytorch复现_simclr pytorch-优快云博客
[2]Pytorch CrossEntropyLoss() 原理和用法详解-优快云博客
[3]BYOL(NeurIPS 2020)原理解读-优快云博客
[5]深度学习(自监督:MoCo)——Momentum Contrast for Unsupervised Visual Representation Learning-优快云博客
[6]CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili


















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











