







 本文是针对Python爬虫初学者的一篇教程,分享作者在学习过程中遇到的问题及解决经验。文章通过实战案例,详细解释了使用BeautifulSoup和requests库进行网页抓取和数据抽取的基本步骤,并分析了常见错误及其解决方案。后续将探讨正则表达式、lxml以及CSS和Xpath选择器等其他数据抽取方法。
本文是针对Python爬虫初学者的一篇教程,分享作者在学习过程中遇到的问题及解决经验。文章通过实战案例,详细解释了使用BeautifulSoup和requests库进行网页抓取和数据抽取的基本步骤,并分析了常见错误及其解决方案。后续将探讨正则表达式、lxml以及CSS和Xpath选择器等其他数据抽取方法。
写之前想说的话:
新手码文,近来学习Python爬虫技术(level 0.0),我疯狂踩各种坑,用实战得到的经验,填码于此,与诸君共勉!图文并茂,尤其适合小白阅读。
学有余力的博友们,可以加入中国大学MOOC嵩天老师主讲的课程,十分有趣,或阅读下(人民邮电出版社、 Python Web Scraping)等(无利益相关,就不贴链接了),为以防小白从入门到放弃,本人注重实践第一,我对书中部分案例做了大幅度的修改,修改后的代码,适合反复观看并练习,具体如下:(超详细,附解说,附报错分析,纯手打,请勿随意搬运哈)
tips:如果你同样学爬虫,遇到代码报错的时候不要慌~~ 静下心来研究下发生了什么?【故作镇定.JPG】
正文:
< Python Web Scraping>案例如下:
添加链接描述
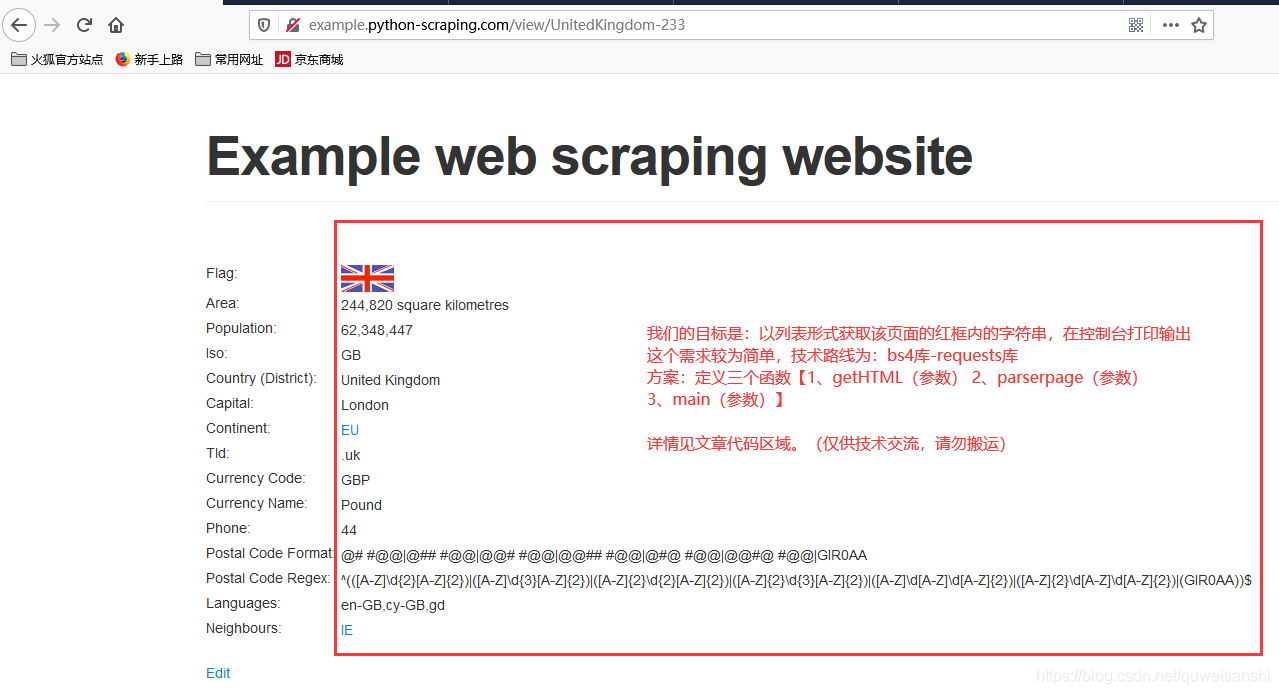
输出如下:(删减了printInfoList 打印输出控制模块,不影响效果)

代码区域:
from bs4 import BeautifulSoup
import requests
import bs4
#以上是需要导入的库,没有的话,需要pip 指令安装下,pass。
#1、获取网页内容的模块,参数为自定义的url,此代码建议反复记忆,小白必备。 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2535
2535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









