




 本文探讨了Hadoop在工业大数据中的作用,介绍了Hadoop作为分布式处理框架的起源、核心组件和优势。Hadoop适用于存储大量半结构化数据和实现高效分布式计算,尤其在大型集团企业的工业大数据项目中。然而,小型项目可能不需要分布式计算,中型项目推荐使用公有云提供的Hadoop服务,而大型项目当前更适合自建Hadoop环境。
本文探讨了Hadoop在工业大数据中的作用,介绍了Hadoop作为分布式处理框架的起源、核心组件和优势。Hadoop适用于存储大量半结构化数据和实现高效分布式计算,尤其在大型集团企业的工业大数据项目中。然而,小型项目可能不需要分布式计算,中型项目推荐使用公有云提供的Hadoop服务,而大型项目当前更适合自建Hadoop环境。
现在,一谈到大数据的技术,Hadoop都是绕不开的话题,似乎在项目中不使用Hadoop或者类似的分布式数据库技术,就不是大数据应用。那么,到底在工业大数据应用中,没有没必要使用Hadoop,或者在什么样的应用环境中使用Hadoop才是适合的呢?
首先,让我们来看一看Hadoop是什么,它是为解决什么问题而发展起来的。
简单说,Hadoop是一个能够对大量数据进行分布式处理的软件框架。它包含众多的应用,其最核心的是分布式文件系统HDFS(Hadoop Distributed FileSystem)、分布式计算框架MapReduce。2003年Google发表了一篇技术学术论文详细讲解了谷歌文件系统(GFS),2004年Google又发表了一篇技术学术论文讲解了MapReduce。2004年Nutch创始人Doug Cutting基于Google的GFS论文实现了分布式文件存储系统名为NDFS。2005年Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。2006 年 ,Apache将Map/Reduce 和 Nutch Distributed FileSystem (NDFS) 分别被纳入称为 Hadoop 的项目中。从此,Hadoop作为开源界的分布式大数据处理框架开始迅速流行起来。
Hadoop除了核心HDFS和MapReduce外,还有许多实现具体应用的子项目,其核心组件如下图所示:
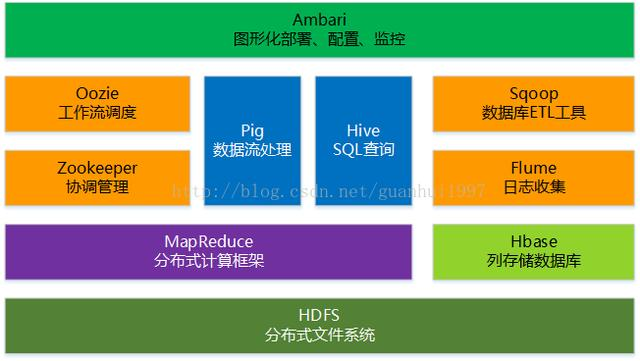
Hadoop核心组件
具体每个组件的功能我们改天另文介绍。今天主要谈谈Hadoop的优点和适用领域。Hadoop由于其自身的特点,在以下场景中有比较大的优势:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









