






HunyuanVideo 是腾讯重磅开源的视频生成大模型,具有与领先的闭源模型相媲美甚至更优的视频生成表现,但由于推理时对显卡的门槛比较高,拥有低显卡的用户望而却步,最近大神Kijai发布了FP8量化版本模型,使得模型可以在显卡较低的情况下可以成功运行。
本次我们利用HunYuanVideo量化版模型在Ubuntu系统本地部署,实现文生视频的功能。
1、本地部署ComfyUI框架
1.1首先需要本地部署ComfyUI框架,克隆官方项目:
git clone https://github.com/comfyanonymous/ComfyUI.git1.2创建运行的conda环境
官网推荐使用 CUDA 12.4 或 11.8 的版本,本文使用的是CUDA12.4版本。
下载ComfyUI代码后,进入ComfyUI项目目录安装conda环境:
注意:这里安装的torch 版本为2.5.1,官网推荐的2.4.0版本在运行时会得到黑的图片和视频(当时在这卡了很久)。
cd ComfyUI
conda create -n HunyuanVideo python==3.10.9
conda activate HunyuanVideo
pip3 install requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
其中,requirement.txt文件修改如下:
torch==2.5.1
torchsde==0.2.6
torchvision==0.20.1
torchaudio==2.5.1
einops==0.8.0
transformers>=4.28.1
tokenizers>=0.13.3
sentencepiece==0.2.0
safetensors>=0.4.2
aiohttp
pyyaml
Pillow
scipy
tqdm
psutil
#non essential dependencies:
kornia>=0.7.1
spandrel
soundfile至此,基于ComfyUI框架的HunyuanVideo虚拟环境安装完成。
2、本地部署ComfyUI-HunyuanVideoWrapper
首先进入ComfyUI项目中的custom_nodes目录,
随后,本地部署 ComfyUI-HunyuanVideoWrapper项目节点,这个节点用来生成视频。
cd custom_nodes
git clone https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.git
cd ComfyUI-HunyuanVideoWrapper
pip3 install requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple至此,ComfyUI-HunyuanVideoWrapper环境安装完成。
3、本地部署ComfyUI-VideoHelperSuite
首先进入ComfyUI项目中的custom_nodes目录,
随后,本地部署 ComfyUI-VideoHelperSuite项目节点,这个节点用来处理视频。
cd custom_nodes
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
cd ComfyUI-VideoHelperSuite
pip3 install requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple至此,ComfyUI-VideoHelperSuite环境安装完成。
4、下载HunyuanVideo相关的模型
4.1首先打开以下链接下载视频模型的fp8量化版本:
https://www.modelscope.cn/models/Kijai/HunyuanVideo_comfy/files这里模型包括fp8本体和vae模型,注意都下载体积小的那个。
模型名称分别是:hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors 和 hunyuan_video_vae_bf16.safetensors。
下载成功后,分别放入 models/diffusion_models 目录 和 models/vae 目录即可。
2.2接着下载文本编码模型:
git clone https://www.modelscope.cn/Kijai/llava-llama-3-8b-text-encoder-tokenizer.git把这个模型放入 models/LLM 目录,如下:
~/ComfyUI/models/LLM
LLM
└── llava-llama-3-8b-text-encoder-tokenizer
├── config.json
├── generation_config.json
├── model-00001-of-00004.safetensors
├── model-00002-of-00004.safetensors
├── model-00003-of-00004.safetensors
├── model-00004-of-00004.safetensors
├── model.safetensors.index.json
├── special_tokens_map.json
├── tokenizer.json
└── tokenizer_config.json 2.3最后,下载 clip 模型:
https://www.modelscope.cn/models/AI-ModelScope/clip-vit-large-patch14/files注意,只下载model.safetensors模型和其他配置文件即可,其他格式的模型没有必要下载,随后放到models/clip目录,结构如下:
~/ComfyUI/models/clip
clip
└── clip-vit-large-patch14
├── config.json
├── merges.txt
├── model.safetensors
├── preprocessor_config.json
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
└── vocab.json至此,模型就下载好了,注意模型总体积加上环境大概40G左右,请预留足够的磁盘空间。
5、启动整个项目
第一步:进入ComfyUI文件夹内,运行以下命令:
python3 main.py第二步:导入ComfyUI-HunyuanVideoWrapper目录里面examples hyvideo_lowvram_blockswap_test.json工作流即可运行,如下图所示:
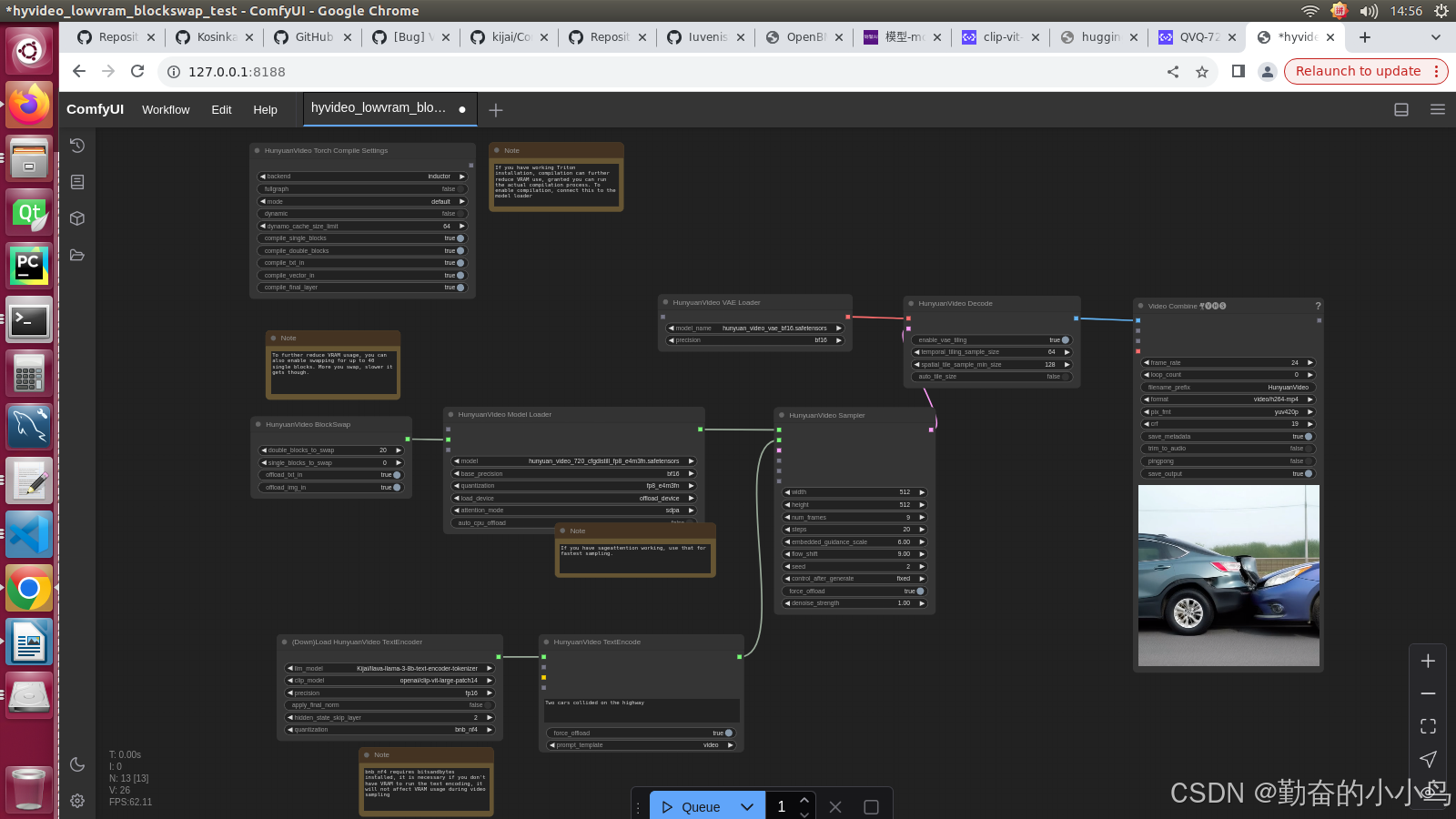
至此,整个项目搭建完成,可正常生成视频!!!

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









