






摘要
随着城市化进程的加速,地铁作为现代城市的重要交通工具,其站点命名不仅反映了城市的地理和文化特征,还承载了历史记忆和社会变迁。本研究基于高德地图提供的全国5805个地铁站数据,通过详尽的数据分析,揭示了中国地铁站命名背后的规律与特点。
引言
随着中国城市化进程的加速,地铁作为现代城市交通的重要组成部分,其站点命名不仅反映了城市的地理特征和文化背景,还承载了丰富的历史记忆和社会变迁。该报告旨在通过对中国5085个地铁站名称的数据分析,揭示地铁站命名背后的规律与特点,探讨汉字在城市空间中的应用及其背后的文化、历史和社会因素。
研究基于高德地图提供的全国地铁站数据,采用定量分析与定性分析相结合的方法,系统地探讨了中国地铁站命名的模式。首先,我们统计了地铁站名称中出现频率最高的词、字,并分析了这些高频词在不同城市中的分布情况。接着,通过城市级别的字使用频率分析,深入理解各城市对特定字命名地铁站的偏好。此外结合地理因素,探讨了汉字选择与城市地理位置之间的关系。
初步结果显示,“路”字以 1119 次的高频使用量位居榜首,其次是“大”、“南”、“园”等常用字。不同城市对高频汉字的使用存在显著差异,例如北京偏好使用“桥”,而上海、天津、武汉等城市则更倾向于“路”。进一步分析表明,某些汉字如“门”、“街”、“庄”等具有特定的文化或历史背景,它们的使用频率和分布模式能够反映出城市的独特风貌和发展脉络。
爬取与预处理
获取数据的部分参考了文章https://mp.weixin.qq.com/s/fTt_-DJXFa5GmTZa3J03og.
定义抓取函数 get_message(ID, cityname, name) 与获取城市列表函数 get_city(),分别构建了指向高德地图地铁服务 API 的 URL 和城市列表页面 URL,先从城市列表抓取所有支持地铁查询的城市,再通过 GET 请求获取地铁线路及站点的 JSON 数据,写入”subway.csv” 文件。这里打印head查看。
import pandas as pd
file_path='D:/FILE/CLASSFILE/DataScience/Final/subway.xlsx'
df=pd.read_excel(file_path)
df.columns=['城市','线路','站点']
print(df.head())
print(df.isnull().sum())

当前统计共有地铁站点 6920 个,但实际上,由于爬取站点数据时采用了逐个城市逐条地铁线路爬取的策略,不可避免地重复统计两条或两条以上地铁线路交汇的站点,也就是换乘站。对于同一个站点出现在多条线路上的情况,我们希望合并这些记录,使得每个站点只出现一次,但是仍然保存它所属的所有线路。这可以通过分组聚合来实现。
result_df=df.groupby(['城市','站点'])['线路'].agg(lambda x:', '.join(dict.fromkeys(x).keys())).reset_index()
result_df.rename(columns={'线路':'所有线路'},inplace=True)
print(result_df.head())
output_file_path='D:/FILE/CLASSFILE/DataScience/Final/cleaned_subway.xlsx'
result_df.to_excel(output_file_path,index=False)
做了如下工作:使用 groupby() 函数按“城市”和“站点”两列进行分组。对每组应用自定义函数,该函数接收一个包含该站点所有线路的列表,去除重复项后排序,并将它们用逗号连接成字符串。然后用reset_index() 将分组后的结果转换回标准的 DataFrame 格式。最后为了清晰表达新列的内容,将原“线路”列重命名为“所有线路”。如下图所示。

统计得去除重复爬取的换乘站后,所有地铁站点共 5805 个,这构成了展开下面分析的原始数据。
基础统计
分别统计全国开通地铁的城市数、总地铁线路数和总地铁站数。
nation_total_stations=len(df_cleaned)
print(f"全国地铁站总数:{nation_total_stations}")
全国地铁站总数:5805
nation_cities_with_metro = df_cleaned['城市'].nunique()
print(f"全国开通地铁的城市总数: {nation_cities_with_metro}")
全国开通地铁的城市总数: 41
all_lines = df_cleaned['所有线路'].str.split(', ').explode()
unique_lines = all_lines.nunique()
print(f"全国地铁线路总数: {unique_lines}")
全国地铁线路总数: 104
city_line_counts = df_cleaned.groupby('城市')['所有线路'].apply(lambda x: pd.Series(x.str.split(', ').sum()).nunique()).reset_index(name='线路数')
city_station_counts = df_cleaned.groupby('城市').size().reset_index(name='地铁站数')
top_cities = city_station_counts.nlargest(5, '地铁站数')
print(f"地铁站前五名多的城市是:\n{top_cities}")
all_lines_with_city = df_cleaned[['城市', '所有线路']].assign(所有线路=df_cleaned['所有线路'].str.split(', ')).explode('所有线路').reset_index(drop=True)
line_station_counts = all_lines_with_city.groupby(['城市', '所有线路']).size().reset_index(name='站点数')
top_lines_with_city = line_station_counts.nlargest(5, '站点数')
print(f"站点最多的前五条线路及所在城市: \n{top_lines_with_city}")
地铁站前五名多的城市是:
城市 地铁站数
0 上海 410
5 北京 401
28 深圳 317
20 成都 299
23 杭州 296
站点最多的前五条线路及所在城市:
城市 所有线路 站点数
152 成都 6号线 56
110 天津 6号线 47
32 北京 10号线 45
214 深圳 2号线/8号线 42
151 成都 5号线 41
有价值的基础统计的可视化

北京和上海的地铁线路总数显著高于其他城市,分别达到了 25 条以上。广州、杭州、深圳等一线城市也拥有较多的地铁线路,数量在 15 条左右。成都、南京、重庆等二线城市地铁线路数量也在10条以上。这表明了较明显的区域分布特点,一线城市和部分发达二线城市的地铁线路数量明显较多,这与这些城市的经济规模和人口密度密切相关。

地铁线路的分布出现了部分东西、南北差异和明显的都市圈效应。在京津冀地区、长三角地区和粤港澳大湾区,地铁线路分布十分密集,尤其是长三角地区中浙江北部、江苏南部和上海,地铁线路城市分布沿长江构成了密集的网络。这进一步证明地铁线路数量和经济发展水平有着严格的相关关系。在除了上述提到的都市圈之外,广大中西部省份和东北省份中,地铁都仅仅存在于省会城市,在其他地市则没
有分布。这表明了在这些经济相对薄弱地区,省会城市对周边人口、本省人口的虹吸效应和财富聚集作用。对于人口规模更小的省份如宁夏、青海、西藏则没有地铁分布。
词频统计
import jieba
import re
from wordcloud import WordCloud
from collections import Counter
plt.rcParams['font.sans-serif']=['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
file_path = 'D:/FILE/CLASSFILE/DataScience/Final/cleaned_subway.xlsx'
df_cleaned = pd.read_excel(file_path)
def clean_station_name(name):
name = re.sub(r'$.*?$', '', name)
name = re.sub(r'【.*?】', '', name)
name = re.sub(r'[^\w\s]', '', name)
return name.strip()
df_cleaned['站点'] = df_cleaned['站点'].apply(clean_station_name)
station_names = df_cleaned['站点'].tolist()
def tokenize_and_filter(text):
stop_words = set(['的', '地', '得', '了', '着', '在', '上', '是', '我', '有', '和', '就', '不', '都', '个', '这', '很', '到', '说', '为', '你', '们', '看', '好', '也', '而'])
words = jieba.lcut(text)
filtered_words = [word for word in words if word not in stop_words and len(word) > 1]
return filtered_words
all_words = []
for name in station_names:
all_words.extend(tokenize_and_filter(name))
word_counts = Counter(all_words)
print("最常见的前20个词:")
print(word_counts.most_common(20))
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path='simhei.ttf',scale=20)
wordcloud.generate_from_frequencies(word_counts)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('中国地铁站名高频词汇词云图')
plt.show()
观察发现有的站点名字含有特殊字符,比如上海 10 号线 (航中路-基隆路)、10 号线 (虹桥火车站-基隆路) 和 13 号线的换乘站:一大会址·新天地,或上海 1 号线, 14 号线的换乘站:一大会址·黄陂南路,或兰州 1 号线的兰州城市学院 (省科技馆),观察发现或含有括号,或含有特殊字符,因此我们在统计前需移除这些特殊的量,而只统计字词。同时,删除不具有实际意义的汉字字词。
中间输出为:
最常见的前20个词:
[(‘公园’, 150), (‘大道’, 110), (‘广场’, 103), (‘中心’, 58), (‘南路’, 53), (‘大学’, 39), (‘东路’, 36), (‘机场’, 36), (‘北路’, 34), (‘火车站’, 31), (‘西路’, 30), (‘医院’, 30), (‘大街’, 30), (‘中路’, 24), (‘西站’, 21), (‘新城’, 21), (‘北站’, 21), (‘体育中心’, 20), (‘新村’, 19), (‘人民’, 19)]
绘制词云图。

遍历查找包含“公园”的地铁站在各城市的分布发现,苏州拥有 10 个名称中包含“公园”的地铁站,位于榜首,包括中央公园、南施公园南、夏架河公园、方洲公园、桐泾公园、白洋湾公园、祖冲之公园、花溪公园、莲湖公园和虎丘湿地公园。从地铁站分布上看,可能与苏州悠久的历史文化和丰富的自然景观有关。作为著名旅游目的地,苏州有许多公园园林,往往是游客休闲好去处,因此地铁线路设计时会特别考虑连接这些景点。
广州、深圳、成都、郑州、长沙都各有 9 个名称中包含“公园”的地铁站,紧随苏州之后,这些城市均为中国重要都市或新兴一线城市,拥有较大的人口基数和快速发展的城市化进程。公园作为市民休闲娱乐的场所和城市生态建设的重要组成部分,能够表明这些城市在发展过程中注重生态环境保护和居民生活质量提升。
通过类似方法,继续分析中国地铁站名高频词前三名“公园”之外的“大道”、“广场”。
keywords = ['公园']
keyword_results = {keyword: [] for keyword in keywords}
for index, row in df_cleaned.iterrows():
for keyword in keywords:
if keyword in row['站点']:
keyword_results[keyword].append({
'城市': row['城市'],
'站点': row['站点'],
'线路': row['所有线路']
})
all_results_list=[]
for keyword, results in keyword_results.items():
for result in results:
all_results_list.append({
'关键词': keyword,
'城市': result['城市'],
'站点': result['站点'],
'线路': result['线路']
})
all_results_df = pd.DataFrame(all_results_list)
sns.set(style="whitegrid")
city_counts = all_results_df['城市'].value_counts().reset_index()
city_counts.columns = ['城市', '数量']
print(city_counts)



再查看地铁站名包含“大学”的城市。

这是否能反映该城市高校数量呢?要同时意识道,不是所有以高校名称命名的地铁站都完整包含“大学”二字,比如“南大仙林校区”,因此,“校区”也是我们需要关注的关键词。对含“校区”的地铁站点名进行统计,果然发现遗漏了不少站点,结果如下:
城市: 南京, 站点: 东大九龙湖校区, 线路: 3 号线
城市: 南京, 站点: 南大仙林校区, 线路: 2 号线
城市: 合肥, 站点: 六中菱湖校区, 线路: 5 号线
城市: 合肥, 站点: 安大磬苑校区, 线路: 3 号线
城市: 合肥, 站点: 工大翡翠湖校区, 线路: 3 号线
城市: 呼和浩特, 站点: 内大南校区, 线路: 2 号线
城市: 天津, 站点: 南开大学津南校区, 线路: 6 号线
城市: 天津, 站点: 天津大学北洋园校区, 线路: 6 号线
城市: 徐州, 站点: 师大云龙校区, 线路: 2 号线
城市: 徐州, 站点: 矿大文昌校区, 线路: 3 号线
城市: 成都, 站点: 川大望江校区, 线路: 8 号线
城市: 成都, 站点: 川大江安校区, 线路: 8 号线
城市: 成都, 站点: 成都医学院新都校区, 线路: 3 号线
城市: 杭州, 站点: 浙大国际校区, 线路: 杭海城际
城市: 西安, 站点: 理工大曲江校区, 线路: 5 号线
城市: 西安, 站点: 西工程大西科大临潼校区, 线路: 9 号线
城市: 西安, 站点: 西电科大南校区未来之瞳, 线路: 6 号线
城市: 长沙, 站点: 一师范西校区, 线路: 6 号线
在更新了这些站点数量后,计算站点数量和大学数量的皮尔逊相关系数 =0.6102。
字频统计
import pandas as pd
from collections import Counter
import jieba
subway_df = pd.read_excel('D:\FILE\CLASSFILE\DataScience\Final\cleaned_subway.xlsx')
all_stations = subway_df['站点'].dropna().tolist()
char_counter = Counter()
for station in all_stations:
for char in station:
if '\u4e00' <= char <= '\u9fff': # 确保只统计汉字
char_counter[char] += 1
char_freq_df = pd.DataFrame.from_dict(char_counter, orient='index', columns=['频率'])
char_freq_df = char_freq_df.sort_values(by='频率', ascending=False)
print("频率最高的前20个汉字:")
print(char_freq_df.head(20))
绘制词云图。
from wordcloud import WordCloud
wordcloud = WordCloud(font_path='simhei.ttf', width=800, height=400, background_color='white').generate_from_frequencies(char_counter)
plt.figure(figsize=(14, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title("中国地铁站名称中最常用的汉字词云", fontsize=16)
plt.show()

路”稳居榜单之首,包含“路”字的地铁站占全国所有地铁站的约 20%,这符合我们日常生活的认知,地铁站似乎都倾向于以“xx 路”命名。
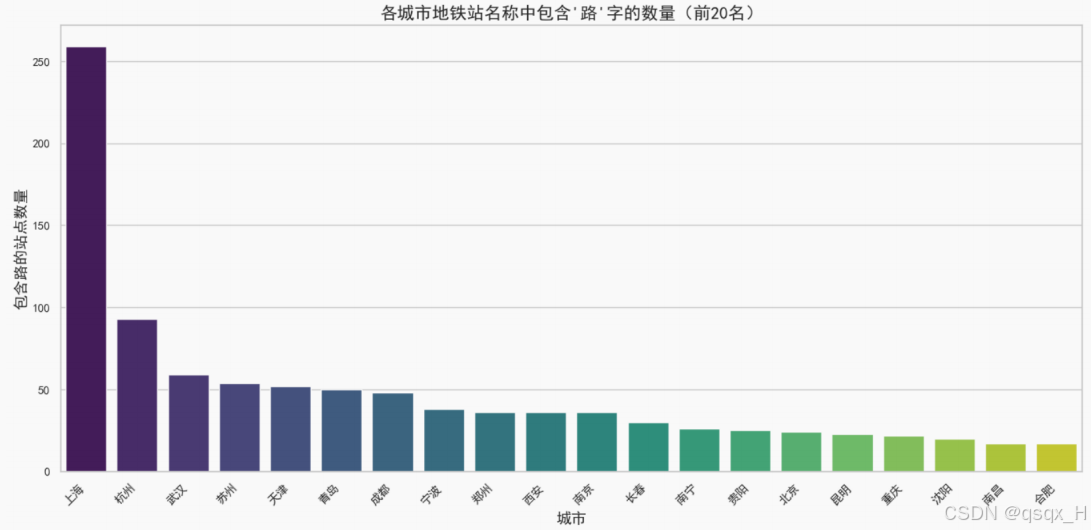
在全国 1119 个包含“路”字的地铁站中,上海又独居 259 个,约占全国 23%,这也意味着上海的所有410个地铁站中,包含“路”字的地铁站就占到了 63% 的极高比例。上海为什么如此青睐于以“xx 路”命名地铁站呢?
经过对城市规划的初步了解,我认为上海的地铁站点在很大程度上是依托现有的城市道路系统进行规划的。地铁线路与道路网络之间的高重合性意味着许多地铁站的名称往往与沿线的道路名称直接关联。在上海,特别是在老城区和历史文化区,道路系统大多是由早期的外国租界区及近现代的城市发展规划所形成,许多重要街道(如南京路、淮海路、陕西路等)都以国内地名命名“xx 路”,这种命名方式展现着上海作为中国经济中心的浓厚博大氛围,也逐渐成为上海街道命名的标准。
此外,上海的地铁建设始于 20 世纪 90 年代,由于上海城区早期的道路命名体系已经广泛普及,以“xx路”命名地铁站能够避免混淆,保持城市的命名一致性,并且有助于市民快速识别和定位。很多地铁站沿线路段命名,如“南京东路站”、“静安寺路站”等,都是为了简化导航和使用,使人们能够方便地记住地铁站的位置。作为国际化大都市,上海在地铁命名时自然也通常会考虑到外籍人士的需求。对于国际化城市
来说,采用“路”这种简洁且具有明确指向性的名称,既符合中国的命名传统,又具备了较强的可理解性,便于外国人和游客快速理解地铁站的位置。
绘制所有城市最常用字的热力图。
import seaborn as sns
import numpy as np
pivot_table = most_common_chars_df.pivot(index='城市', columns='最常用汉字', values='频率').fillna(0)
# 热力图
plt.figure(figsize=(14, 10))
sns.heatmap(pivot_table, annot=True, cmap='coolwarm', fmt='.0f', cbar_kws={'label': '频率'})
plt.title("各城市地铁站中最常用的汉字", fontsize=16)
plt.tight_layout()
plt.show()
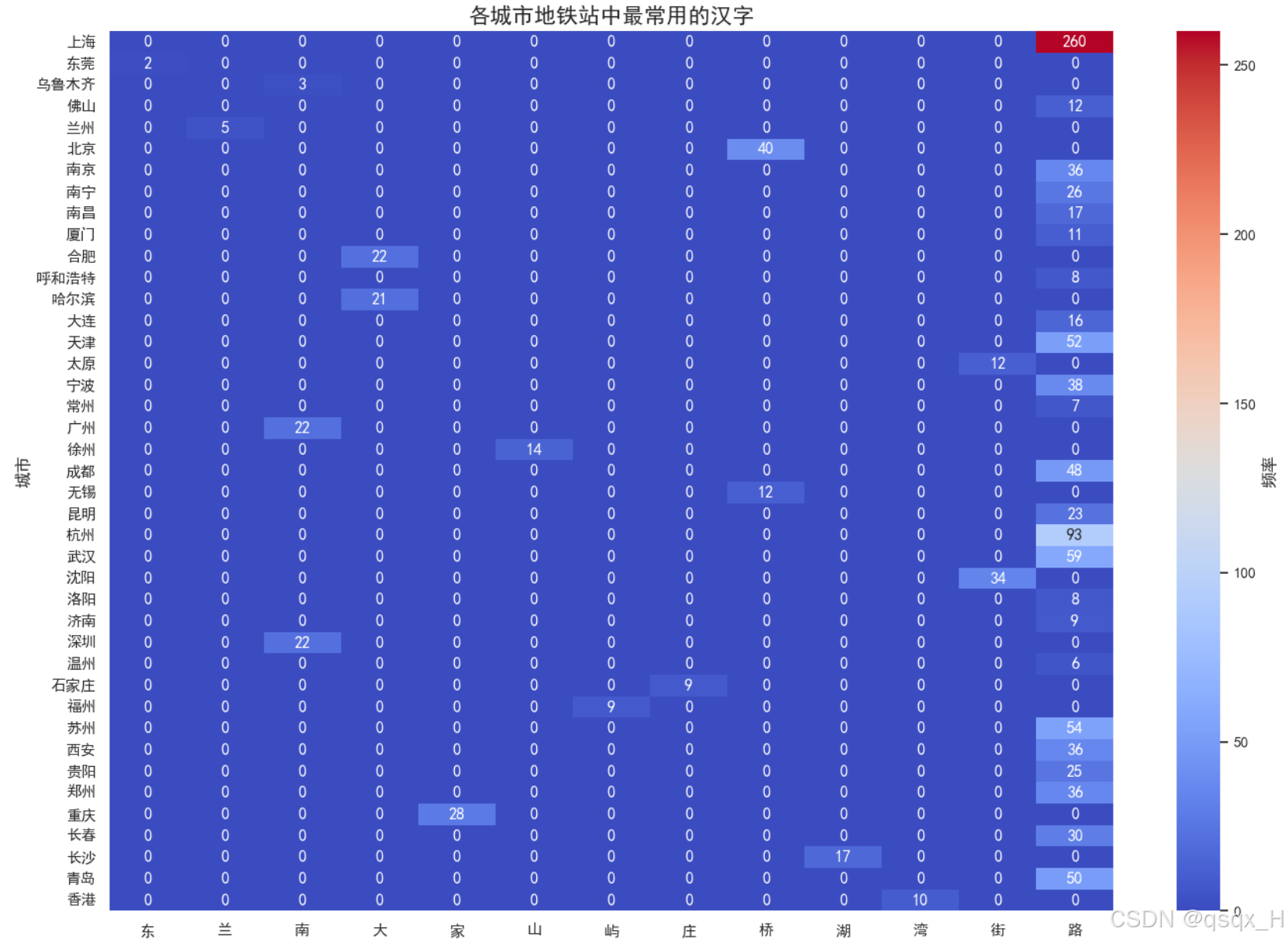
深圳地铁站“湾”字出现较多93次;
杭州“街”字出现了54次;
南京地铁站“庄”字出现较高36次;
重庆由于地形特点,“山”字在站名中出现频次较高28次;
武汉地铁站命名中“湖”字的使用59次;
“桥”字在广州出现48次。
对于一些特色字,大部分城市基本不使用,这说明不同城市命名的特色用字是高度区域化的。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









