






一、项目概述
本项目基于 KDD Cup 99 数据集,旨在利用机器学习与深度学习(卷积神经网络)对网络入侵进行检测和分类。项目同时包含了数据预处理、特征工程、模型训练、预测和伪造数据(如 IP、地理位置信息)等功能,为网络安全相关的研究和应用提供参考。
技术栈:Python+flask+vue+cnn(pytorch)+随机森林+echart+sqlite
二、目录结构说明
项目在解压后,主要包含以下三个目录:
交付-最新 │ ├── algos │ ├── .gitignore │ ├── predict_save.py │ ├── ml.py │ ├── ml_scaler.pkl │ ├── ml_drop_duplicate.pkl │ ├── ml_rf_model.pkl │ ├── cnn_model.pth │ ├── nn_encoder.pkl │ ├── ml_ohe.pkl │ └── nn.py │ ├── data │ └── kddcup99_csv.csv │ └── web
1. algos 文件夹
该文件夹存放与机器学习(ML)和深度学习(DL)相关的所有核心算法、模型文件和脚本,包括:
.gitignore- 指定 Git 需要忽略的文件或目录,通常包括一些中间文件、模型文件等不需要版本管理的大文件。
predict_save.py- 主要用于加载机器学习和神经网络模型,并进行数据预测和处理。
- 读取原始数据(
kddcup99_csv.csv); - 通过
Faker库生成伪造的 IP 地址和地理位置信息; - 加载已训练好的模型(随机森林模型、CNN 模型等)及相关预处理器(如 StandardScaler、LabelEncoder 等)进行预测;
- 最终可将预测结果或处理后数据保存到文件或数据库(如 SQLite)中。
ml.py- 机器学习部分的核心脚本,包含以下功能:
- 特征工程:通过
DropDuplicateFeatures等方式去除重复特征; - 模型训练:使用 Ridge、RandomForestRegressor 等模型对数据进行训练(示例中主要是随机森林),并保存训练好的模型;
- 数据预处理:采用
StandardScaler对数据进行归一化或标准化; - 模型序列化:将训练好的模型、特征工程对象(如
DropDuplicateFeatures、StandardScaler等)序列化并保存为.pkl文件。
nn.py- 深度学习部分的核心脚本,定义了一个简单的卷积神经网络(CNN)和一个用于处理 KDD 数据的类:
CNN类:
- 包含两个卷积层(含 BatchNorm、ReLU 激活和 MaxPool),以及全连接层;
- 输入为 (batch_size, in_dim, 8, 8) 的数据张量,输出为多分类或二分类的预测结果。
KddData类:
- 用于加载并处理 KDD Cup 1999 数据,将 41 维特征通过填充/变形处理为 8x8 的矩阵输入;
- 将数据集中字符类型特征(协议、服务、flag 等)用 LabelEncoder 转换为数值;
- 完成训练集与测试集的拆分,并封装为 PyTorch 的
DataLoader。 ml_scaler.pkl/ml_drop_duplicate.pkl/ml_ohe.pklml_scaler.pkl:保存了数据标准化所需的缩放器(StandardScaler)对象;ml_drop_duplicate.pkl:保存了去重特征的对象;ml_ohe.pkl:保存了 One-Hot 编码器的对象。ml_rf_model.pkl- 训练好的随机森林模型,用于机器学习(非深度学习)方式的入侵检测或分类。
cnn_model.pth- 训练好的卷积神经网络权重文件(PyTorch 格式)。
nn_encoder.pkl- 用于神经网络模型预处理的编码器对象(如
LabelEncoder或自定义编码逻辑)。
2. data 文件夹
kddcup99_csv.csv- KDD Cup 1999 数据集的 CSV 文件版本,包含了网络连接记录及其特征、标签信息。
- 共有 41 个主要特征(连续值或离散值)以及标签(是否“normal”或某种类型的“attack”)。
3. web 文件夹
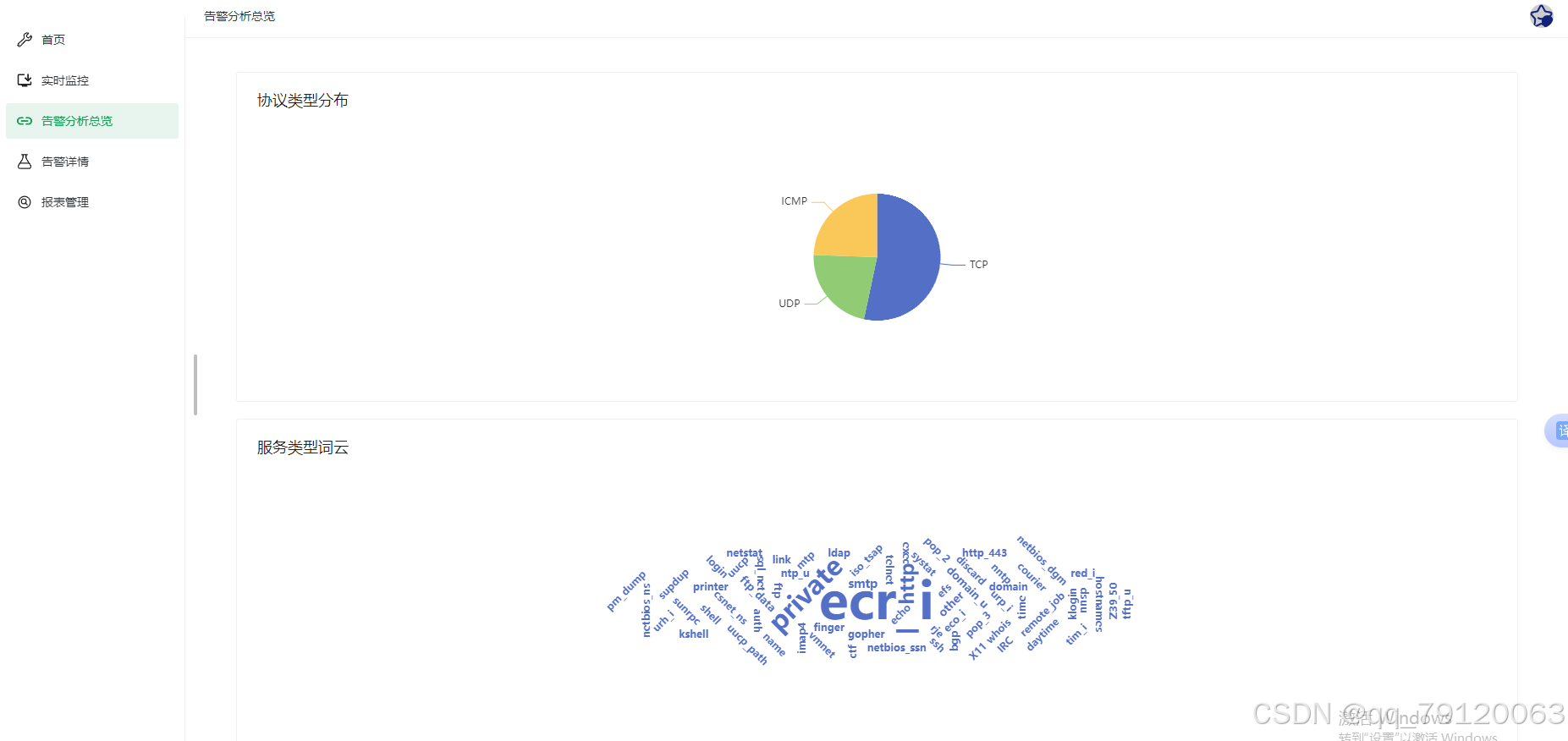
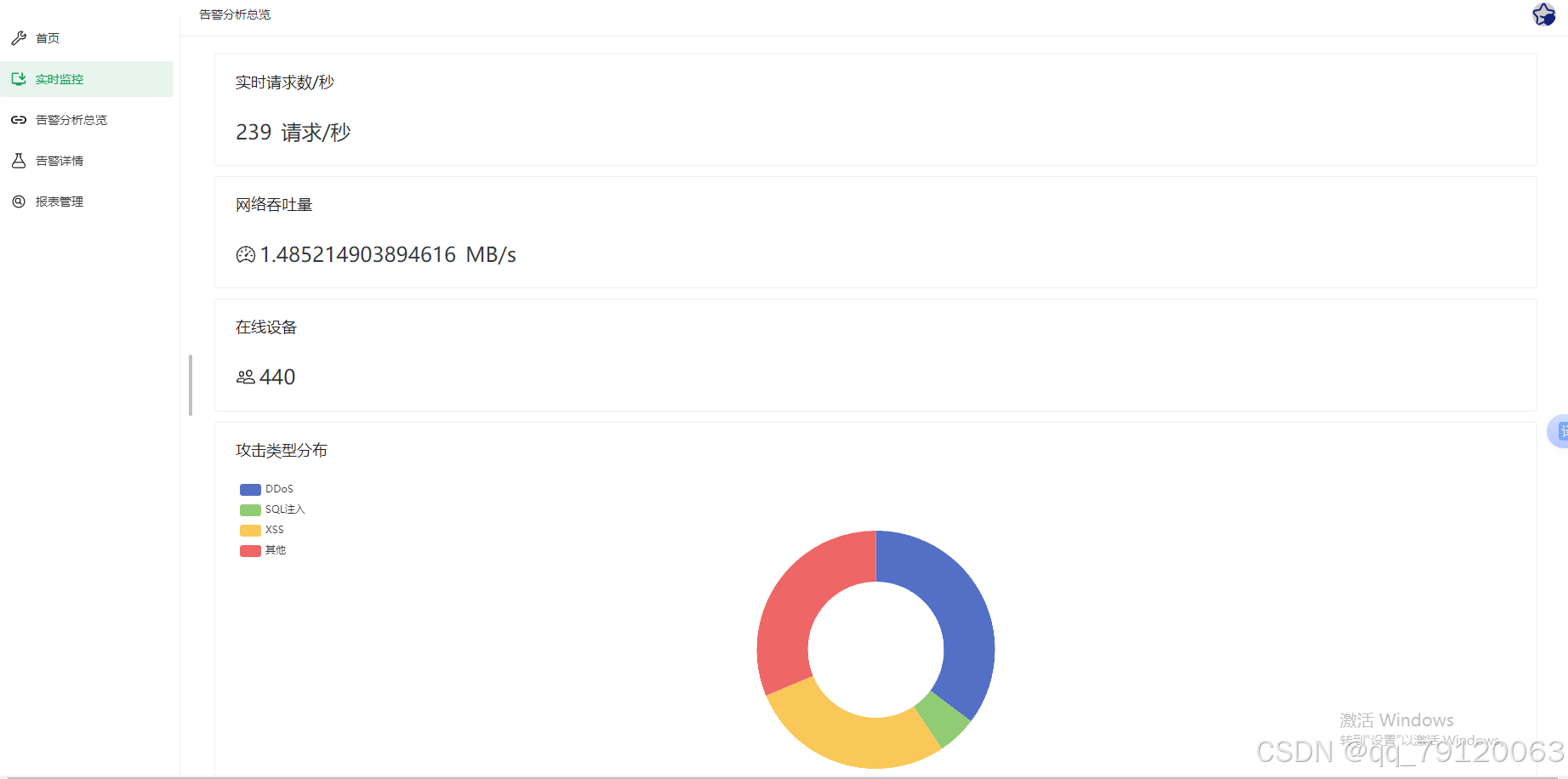
该文件夹可能用于 Web 端或后端服务的部署,目前未提供详细文件信息。可能包含以下内容:
- Web 前端页面或后端 API 代码;
- 用户交互界面,用于上传流量日志、查看检测结果等。
三、主要功能介绍
- 数据读取与预处理
- 读取
kddcup99_csv.csv文件; - 进行特征工程(去重、标准化、编码等);
- 将字符型数据(如协议类型、服务类型)转换为数值或 One-Hot 编码;
- 将 41 维的原始特征填充后变形为 8x8 矩阵(仅在 CNN 训练时)。
- 模型训练
- 机器学习(ML):包括随机森林(
ml_rf_model.pkl)等传统模型; - 深度学习(DL):包括卷积神经网络(
cnn_model.pth); - 训练完成后会将模型及必要的预处理器保存为相应的
.pkl或.pth文件,便于后续加载和推理。
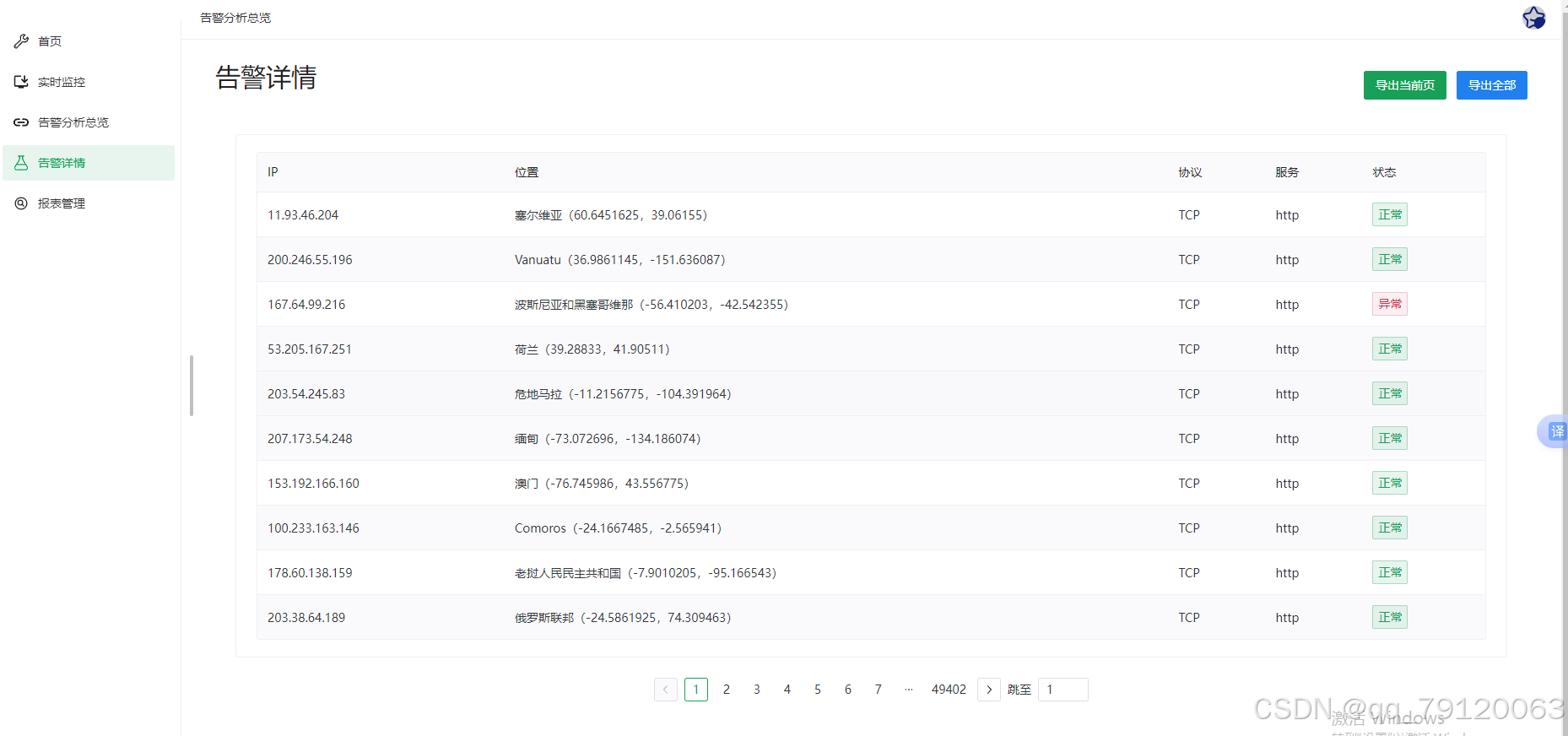
- 模型预测
- 通过
predict_save.py等脚本加载训练好的模型进行预测; - 对新输入的数据进行同样的预处理和编码;
- 可以附加生成随机 IP 和伪造地理位置等功能,以模拟真实的网络环境。
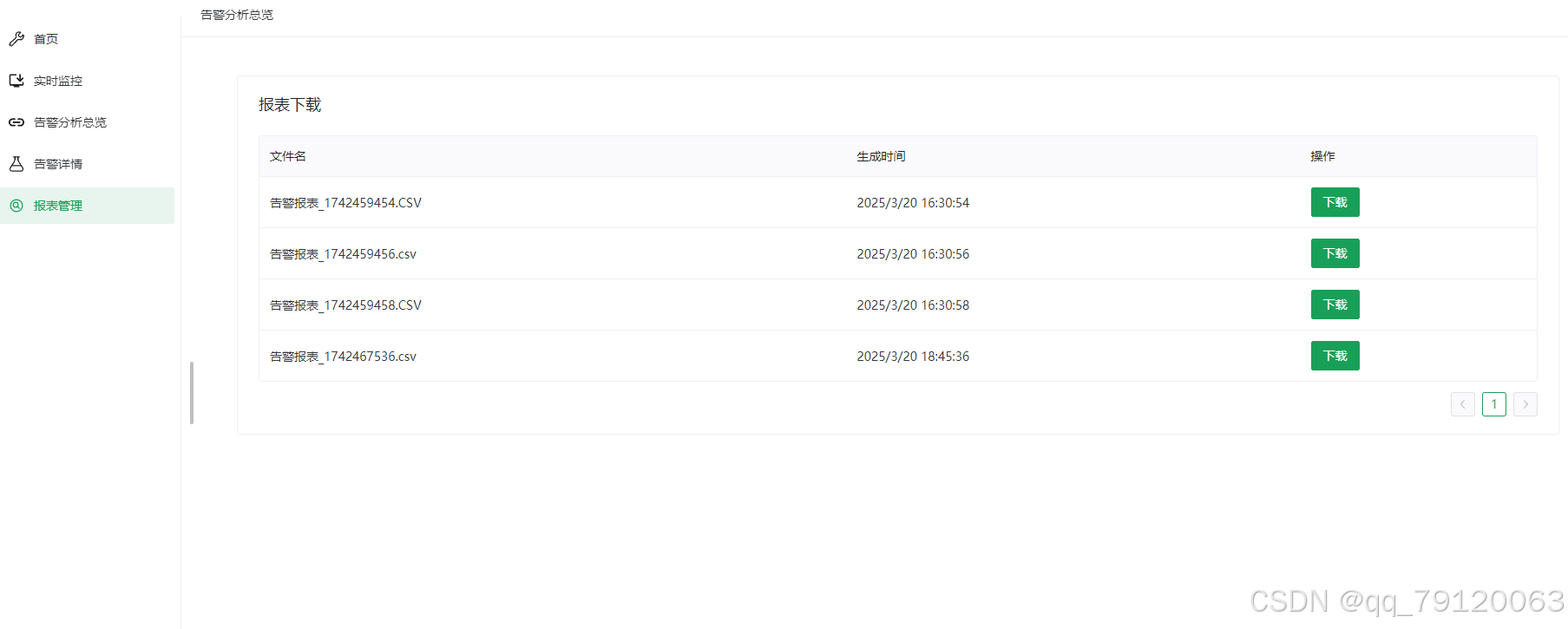
- 结果输出
- 预测结果可以保存在本地文件或数据库(如 SQLite);
- 可将模型预测的 “normal” / “attack” 等标签与其他信息一起输出。
四、使用说明
- 环境配置
- 建议使用 Python 3.7+;
- 安装所需的包:
pandas,numpy,torch,sklearn,feature_engine,joblib,faker, 等。
pip install pandas numpy torch scikit-learn feature_engine joblib Faker
- 数据准备
- 确保
data文件夹下存在kddcup99_csv.csv文件; - 可自行替换为处理后的其他格式数据,但需要兼容脚本中的读取逻辑。
- 模型训练
- 若要重新训练随机森林或 CNN 模型,可在
ml.py/nn.py文件中查看训练代码; - 训练完成后,会在
algos目录下生成(或更新)对应的.pkl/.pth文件。
- 模型预测
- 运行
predict_save.py,它会加载各种预处理器和模型,并对指定输入(或 CSV 数据)进行预测; - 同时可生成随机 IP 与位置,并将结果可视化或存储在 SQLite 中。
- 扩展 / 部署
- 若需在 Web 中使用,可将脚本功能打包为 API 或在后端调用;
- 需要部署到服务器时,需确认所需的依赖环境、内存、GPU(若使用深度学习)等资源就绪。
五、模型与数据说明
- KDD Cup 1999 数据集
- 包含 41 个特征(数值型、字符型)以及标签(normal 或多种攻击类型),部分示例特征:
duration、protocol_type、service、flag、src_bytes、dst_bytes等。- 常见用途:网络攻击检测、异常检测等。
- 随机森林模型(
ml_rf_model.pkl)
- 传统机器学习方法;
- 在预处理后(去重、标准化、One-Hot 等)进行训练;
- 适用于数值型或离散型较多的场景。
- 卷积神经网络(
cnn_model.pth)
- 通过将 41 维特征填充到 64(8x8)维度,构建适合图像处理的输入;
- 两层卷积 + BN + ReLU + MaxPool,然后接全连接层;
- 可以根据项目需求加深或调整网络结构。
六、维护与扩展建议
- 数据归一化 / 标准化
- 建议统一在数据预处理中使用标准化 / 归一化,提高模型的鲁棒性。
- 模型细化
- 对 CNN 的结构进行调整或添加正则化(如 Dropout),有助于提升泛化能力;
- 考虑进一步的特征选择或数据增强(对于网络流量可模拟更多流量特征)。
- 评估指标
- 除了准确率(Accuracy),可在模型评估时使用精确率(Precision)、召回率(Recall)、F1-score 等指标,更好地衡量分类性能。
- 分布式部署
- 如果需要处理大量实时流量,可将训练好的模型部署在分布式环境(如 Spark、Flink)或者使用微服务架构进行扩展。
七、常见问题(FAQ)
- 为什么需要将 41 维特征转为 8x8?
- 这是项目中采用的一种将网络流量特征映射到“图像”形状的方式,以利用 CNN 在图像特征提取方面的优势。
- 如果使用自己的数据集,如何对接?
- 请确保数据格式与当前脚本兼容(如相同或相似的特征列),或者根据需要修改
KddData类和Encode类中的特征处理逻辑。
- 模型推理速度慢怎么办?
- 可以考虑升级硬件(GPU 或更快的 CPU),或使用更加轻量级的模型(如裁剪过的 CNN、或只有机器学习模型)。
- 能否做多分类攻击检测?
- 是可以的。在 CNN 或随机森林输出层使用多分类输出(如 Softmax)并将标签细分为不同类型的攻击,即可实现多分类。
八、总结
本项目通过对 KDD Cup 1999 数据集进行机器学习和深度学习模型训练,实现网络入侵检测的示例。包含了数据预处理、模型训练、推理与伪造数据等完整流程。用户可根据需求修改、扩展模型结构或 Web 功能,以满足特定场景的安全检测需求。
- 如需进一步使用,建议先运行
predict_save.py了解数据处理与推理流程; - 如需训练,可运行
ml.py/nn.py以重新进行模型训练并生成新模型文件; - 对任何自定义开发需求,可在此文档基础上进行调整。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









