






1、项目介绍
技术栈:
Python语言、Django框架、selenium爬虫框架、谷歌Chromediver、Echarts可视化
摘要
随着电子商务的快速发展,在线零售市场的竞争愈加激烈,商家亟需实时掌握商品销量、价格趋势及用户需求等关键数据。然而,现有的商品数据分析方式仍依赖人工处理,数据获取和分析效率低,准确性差,且无法提供全面的可视化分析。这使得商家在决策时缺乏及时有效的数据支持。
本系统通过爬虫技术从京东平台采集商品数据,结合数据清洗、统计和分析,为用户提供全面的商品分析报告。前端采用Echarts进行数据可视化,后端使用Django框架处理业务逻辑,数据库则使用MySQL进行数据存储。系统功能包括数据采集与清洗、数据查询与统计、店铺销量分析、价格分析、购买人数分析、词云分析、商品收藏以及退出登录等操作。
关键词:京东商品采集;数据可视化;爬虫技术;Django框架
京东商品数据采集分析可视化系统是一个基于京东商品数据的数据采集、分析和可视化的系统。该系统能够自动抓取京东商品的信息,并对其进行分析和可视化展示,帮助用户了解商品的销售情况、价格变化趋势、用户评价等信息。
系统的主要功能包括:
-
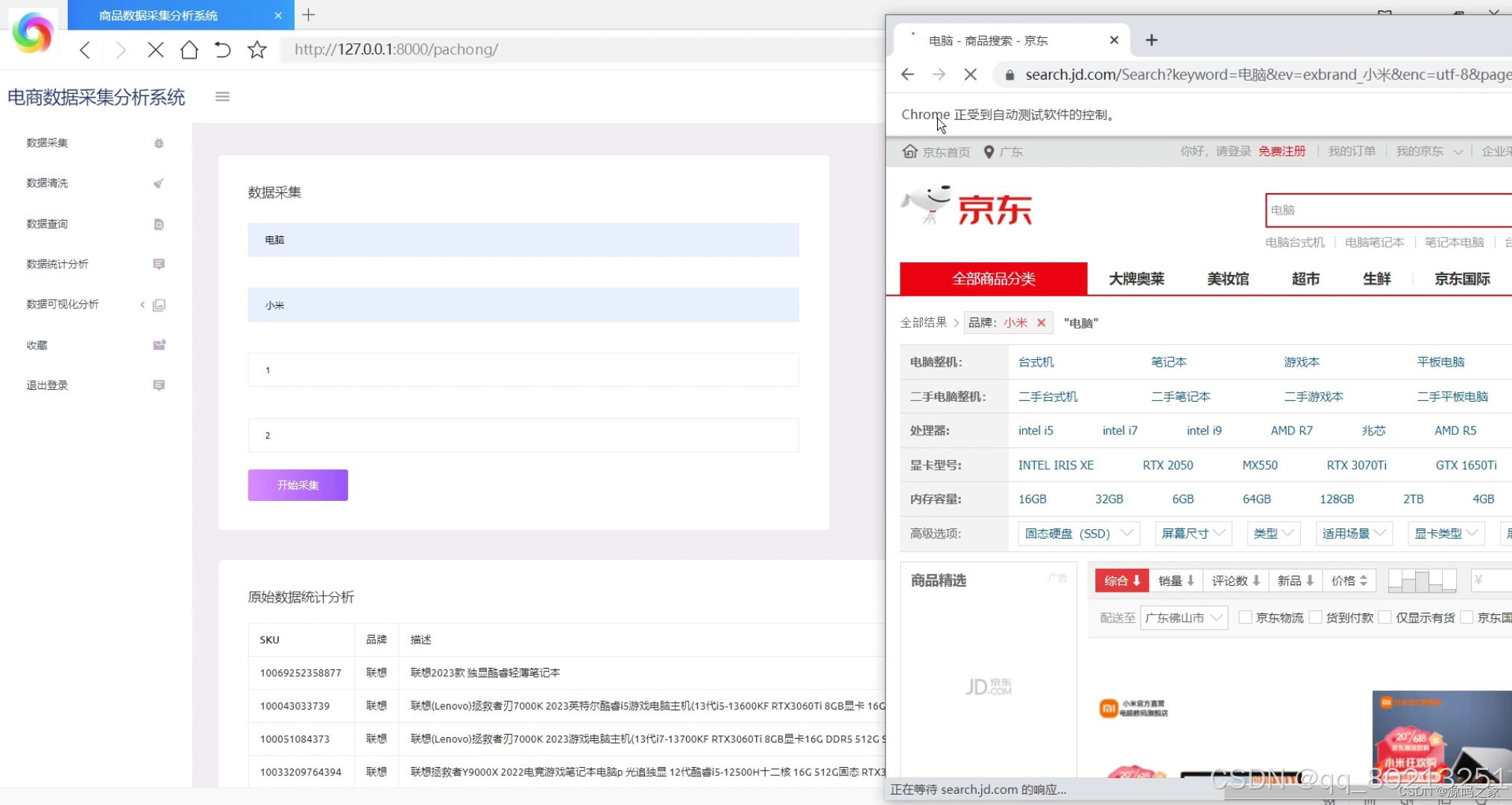
数据采集:系统能够自动抓取京东网站上的商品信息,包括商品名称、价格、销量、评价等。用户可以通过系统设置需要采集的商品类别或关键词,系统将自动从京东网站上抓取相关的商品信息。
-
数据分析:系统能够对采集到的商品数据进行各种统计和分析,包括销售趋势分析、价格变化分析、用户评价分析等。用户可以根据自己的需求选择不同的分析指标和时间范围,系统将生成相应的分析报告和图表。
-
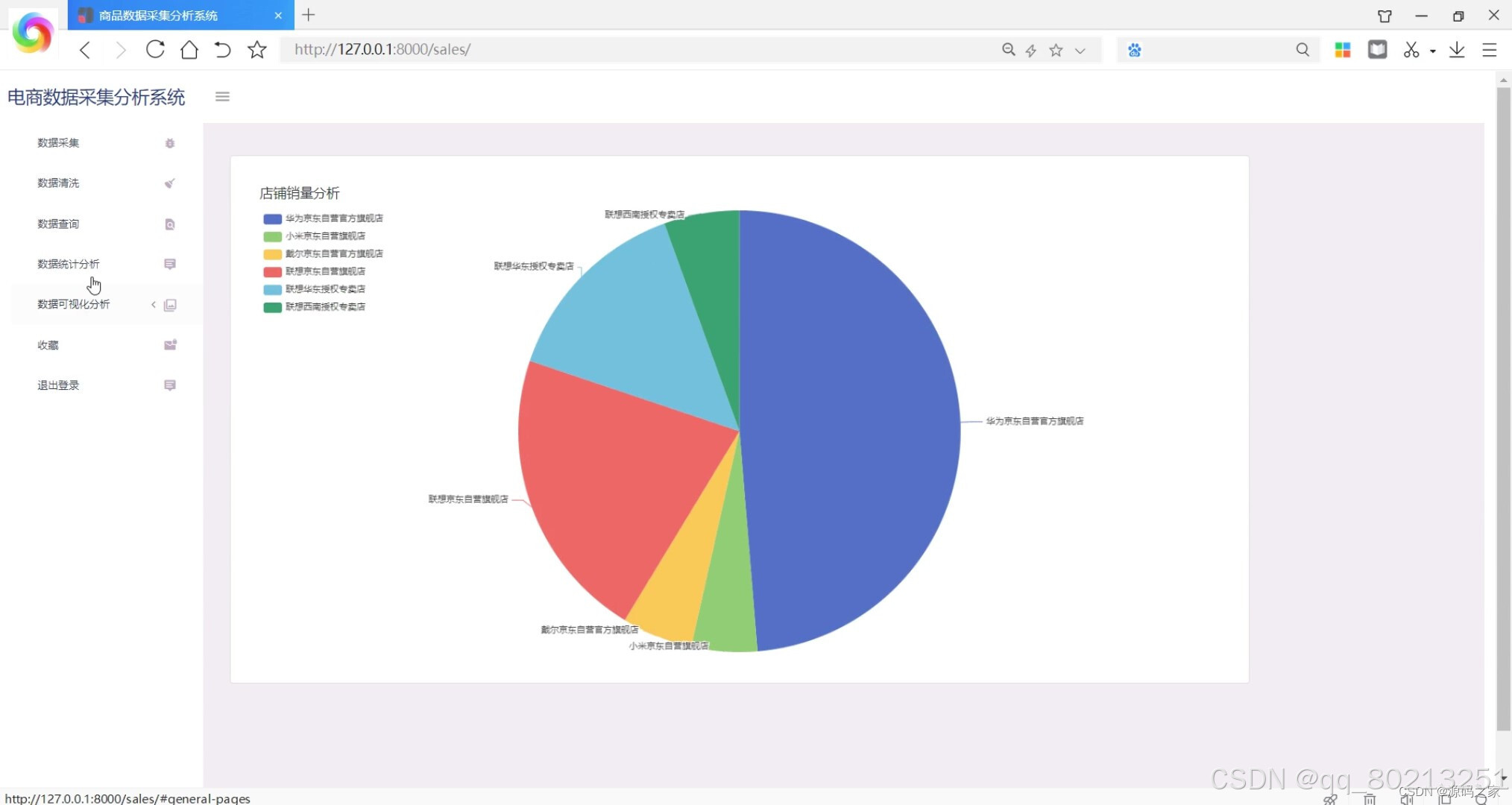
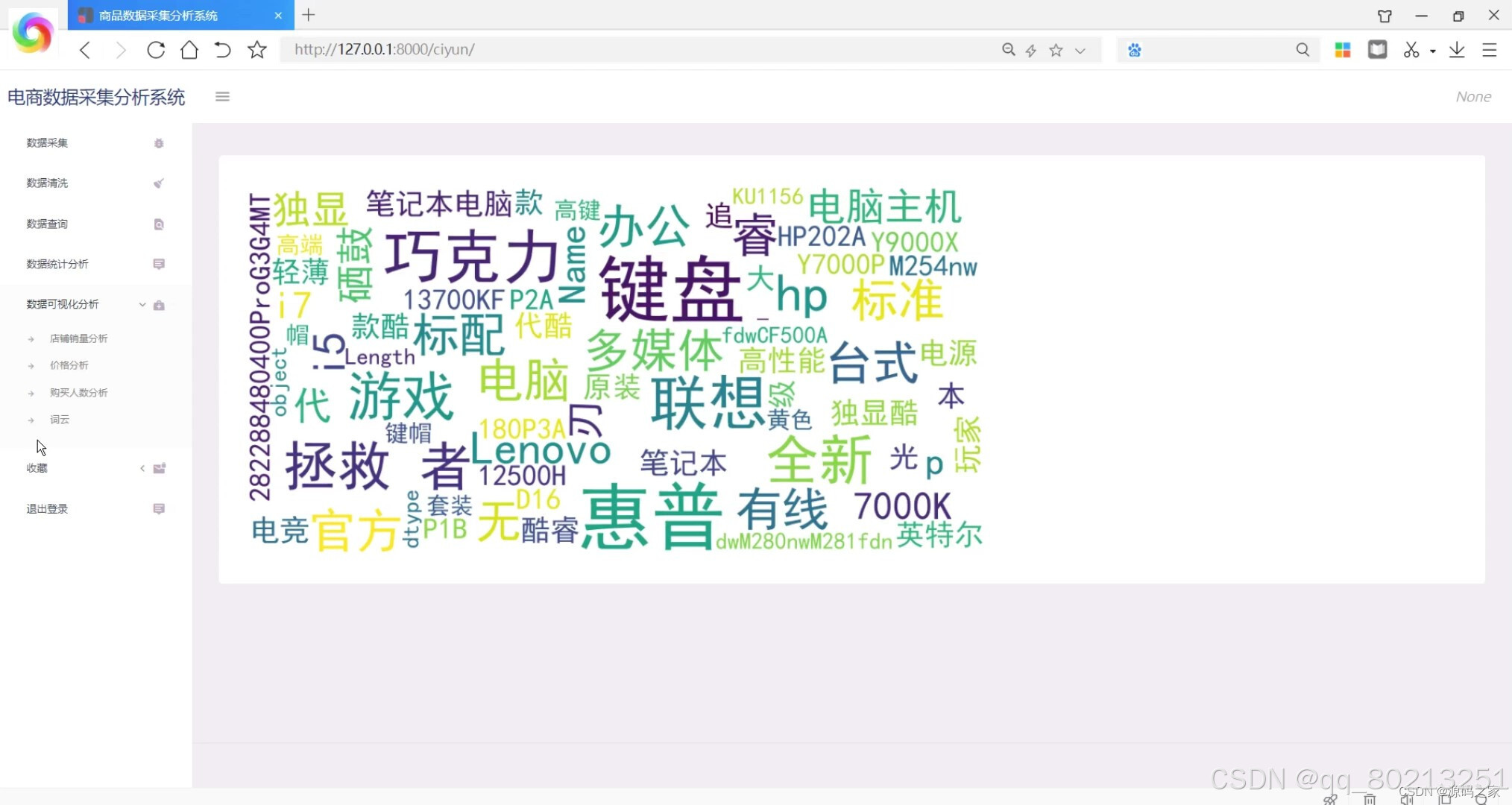
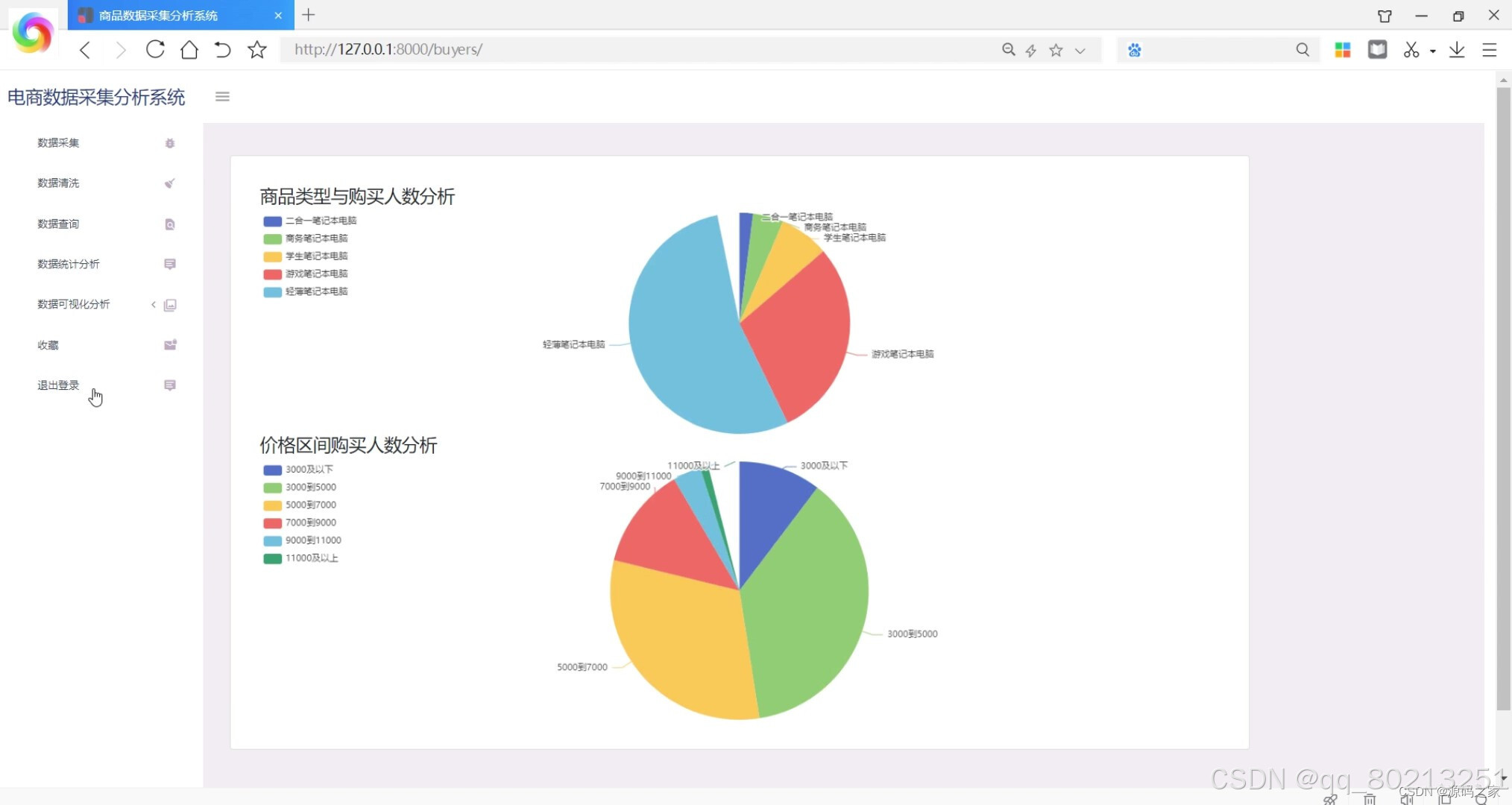
数据可视化:系统能够将分析结果以图表的形式进行可视化展示,包括折线图、柱状图、饼图等。用户可以通过系统的可视化界面直观地了解商品的销售情况和趋势,方便决策和分析。
-
数据导出:系统支持将采集到的数据和分析结果导出为Excel、CSV等常见的数据格式,方便用户进行更深入的分析和处理。
京东商品数据采集分析可视化系统可以帮助用户更好地了解京东商品的市场情况和竞争情况,提供数据支持和决策参考,对于京东商家和电商从业者具有重要的参考价值。
2、项目界面
(1)商品类型与购买人数分析

3、项目说明
京东商品数据采集分析可视化系统是一个基于京东商品数据的数据采集、分析和可视化的系统。该系统能够自动抓取京东商品的信息,并对其进行分析和可视化展示,帮助用户了解商品的销售情况、价格变化趋势、用户评价等信息。
系统的主要功能包括:
-
数据采集:系统能够自动抓取京东网站上的商品信息,包括商品名称、价格、销量、评价等。用户可以通过系统设置需要采集的商品类别或关键词,系统将自动从京东网站上抓取相关的商品信息。
-
数据分析:系统能够对采集到的商品数据进行各种统计和分析,包括销售趋势分析、价格变化分析、用户评价分析等。用户可以根据自己的需求选择不同的分析指标和时间范围,系统将生成相应的分析报告和图表。
-
数据可视化:系统能够将分析结果以图表的形式进行可视化展示,包括折线图、柱状图、饼图等。用户可以通过系统的可视化界面直观地了解商品的销售情况和趋势,方便决策和分析。
-
数据导出:系统支持将采集到的数据和分析结果导出为Excel、CSV等常见的数据格式,方便用户进行更深入的分析和处理。
京东商品数据采集分析可视化系统可以帮助用户更好地了解京东商品的市场情况和竞争情况,提供数据支持和决策参考,对于京东商家和电商从业者具有重要的参考价值。
4、核心代码
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from bs4 import BeautifulSoup
from urllib import parse
import time
import pymysql
import os
class pachong_class:
def __init__(self, B, O, word, pinpai):
self.begin=B
self.end =O
self.word=word
self.pinpai=pinpai
# 实例化一个启动对象
self.chrome_options = webdriver.ChromeOptions()
# 设置浏览器以无界面方式运行
# chrome_options.add_argument('--headless')
self.browser = webdriver.Chrome(executable_path=os.path.join(os.getcwd(), 'app_jd') + '/chromedriver.exe',
options=self.chrome_options)
self.wait = WebDriverWait(self.browser, 10)
self.db = pymysql.connect(host="127.0.0.1", user="root", password="123456", db="jd_goods")
self.cursor = self.db.cursor() # 使用cursor()方法获取操作游标
self.count = 0
def get_url(self,n, word,pinpai):
print('正在爬取第' + str(n) + '页')
time.sleep(8)
# 确定要搜索的商品
keyword = {'keyword':word}
# 页面n与参数page的关系
page = '&page=%s' % (2 * n - 1)
pinpai='&ev=exbrand_%s'%(pinpai)
url = 'https://search.jd.com/Search?' +parse.urlencode(keyword) +pinpai+'&enc=utf-8' + page
print(url)
return url
def parse_page(self,url, pinpai):
print('正在爬取信息并保存......')
self.browser.get(url)
# 滑轮下拉至底部,触发ajax
for y in range(100):
js = 'window.scrollBy(0,100)'
self.browser.execute_script(js)
time.sleep(0.1)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_goodsList .gl-item')))
html = self.browser.page_source
soup = BeautifulSoup(html, 'lxml')
# 找到所有商品标签
goods = soup.find_all('li', class_="gl-item")
# 遍历每个商品,得到每个商品的信息
for good in goods:
num = good['data-sku']
tag = good.find('div', class_="p-price").strong.em.string
money = good.find('div', class_="p-price").strong.i.string
# 因为有些商品没有店铺名,检索store时找不到对应的节点导致报错,故将其设置为“没有找到店铺名”
store = good.find('div', class_="p-shop").span
pingjia = good.find('div', class_="p-commit").strong.a.string
name = good.find('div', class_="p-name p-name-type-2").a.em
picture = good.find('div', class_="p-img").a.img.get('src')
address = good.find('div', class_="p-img").find('a')['href']
if store is not None:
new_store = store.a.string
else:
new_store = '没有找到店铺名'
new_name = ''
for item in name.strings:
new_name = new_name + item
product = (num, pinpai, new_name, money, new_store, pingjia, picture, address)
self.save_to_mysql(product)
#print(product)
def save_to_mysql(self,result):
sql = "INSERT INTO app_jd_yuanshi(sku,pinpai,miaoshu,jiage,shangdian,pingjia,tupian_url,zhuye) \
VALUES ('%d','%s', '%s','%d', '%s','%s', '%s','%s')" % \
(int(result[0]),result[1],result[2],float(result[3]),result[4],result[5],result[6],result[7])
print("sql",sql)
try:
self.cursor.execute(sql) # 执行sql语句
self.db.commit() # 提交到数据库执行
print('保存成功!')
self.count+=1
except:
self.db.rollback() # 发生错误时回滚
print('保存失败!')
def get_data(self):
try:
print(self.begin,self.end,self.word,self.pinpai)
# 京东最大页面数为100
if 1 <= self.end <= 100:
page = self.end + 1
for n in range(self.begin, page):
url = self.get_url(n, self.word, self.pinpai)
self.parse_page(url, self.pinpai)
print('爬取完毕!')
self.db.close() # 关闭数据库连接
self.browser.close()
return (self.count)
else:
print('请重新输入!')
return ('请重新输入!')
except Exception as error:
print('出现异常!', error)
return ('出现异常!', error)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









