



11.Transformer原理
11.1概述
基础神经网络:CNN、RNN、
seq2seq模型(encoder+attention+decoder)的基础模块,可以用CNN、RNN、Transformer等进行做
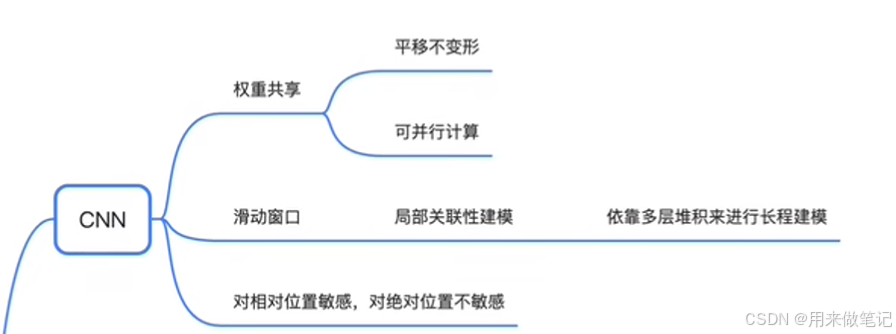
CNN权重共享体现在滑动窗口上,正着计算和反着计算是相同的
多层卷积进行长程建模,对相对位置敏感,对绝对位置不敏感
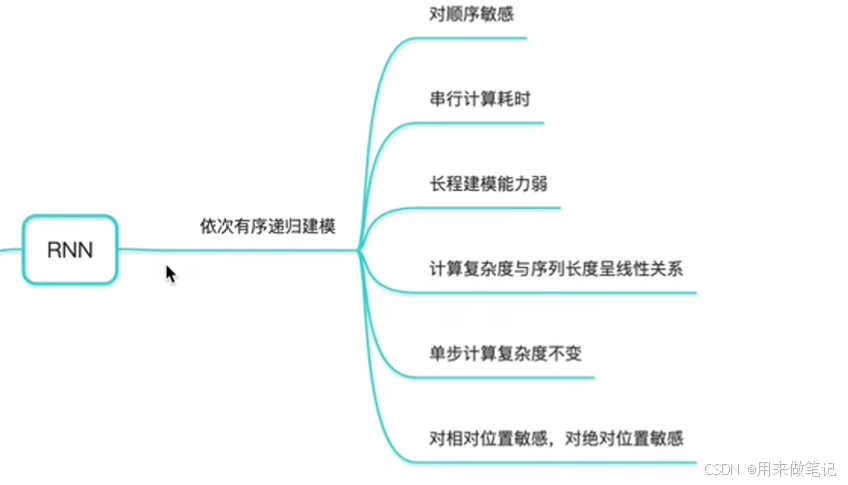
RNN循环神经网络,当前时刻的输出依赖于上一时刻的运算,对位置和顺序非常的敏感,运算也非常的耗时。
对于相对位置敏感,对于绝对位置也敏感
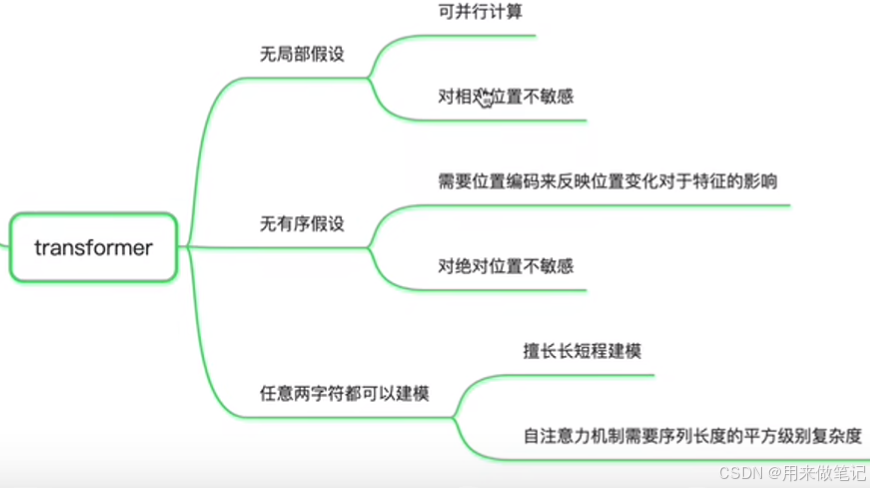
transformer没有序假设,序列建模问题相当于是这样。
任意两字符之间都可以建模,需要依靠自注意力机制,计算复杂度非常大
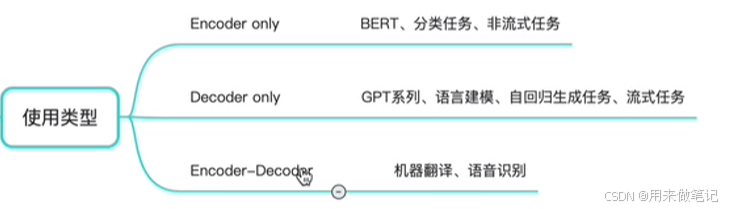
encoder是由n层构成的
input word embedding 由稀疏的one_hot进入一个不带bias的FFN得到一个稠密的连续向量
position encoding每个位置上面的都是确定的,通过残差链接将位置信息流入深层
mult-head self-attention多头自注意力机制,是模型捕捉到更多的位置与位置之间的联系。
feed-forward network
enbedding每一个维度的融合。
Decoder
class Transformer(MOdule): transformer_model = nn.Transformer(nhead=16,num_encoder_layers=12) src = torch.rand((10,32,512)) tgt = torch.rand((20,32,512)) out = transformer_model(src,tgt) def __init__():
TransformerDecoder 实现encoder,把解码层给串起来,
TransformerEncoderLayer 编码层
TransformerEencoder 把编码层给串起来
TransformerDecoderLayer
softmax出来每一个位置上的概率。
11.2Encoder
import torch import numpy import torch.nn as nn import torch.nn.functional as F ##关于word emdding 以序列建模为例 ##考虑source sentence 和 target sentence ##构建序列、序列字符以索引形式 batch_size=2 #单词表大小 max_num_src_words=8 max_num_tgt_words=8 model_dim=8 max_src_seq_len_words=5 max_src_tgt_len_words=5 #src_len=torch.randint(2,5,(batch_size,)) #tgt_len=torch.randint(2,5,(batch_size,)) ##最大序列长度 src_len=torch.Tensor([2,4]).to(torch.int32) tgt_len=torch.Tensor([4,3]).to(torch.int32) ##单词索引构成源句子和目标句子,并且做了padding,默认值为0 src_seq=torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_src_words,(L,)),(0,max_src_seq_len_words-L)),0) for L in src_len ]) tgt_seq=torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_tgt_words,(L,)),(0,max_tgt_seq_len_words-L)),0) for L in tgt_len ]) ##构造embedding src_embedding_table=nn.Embedding(max_num_src_words+1,model_dim) ##model_dim 模型特征大小 tgt_embedding_table=nn.Embedding(max_num_tgt_words+1,model_dim)
11.3Decoder
12.Pytorch nn.Conv2d卷积网络
Conv2d可以自己创建参数
torch.nn.functional.conv2d,手动传入weight,api
通常将一个向量作为全连接网络的输入。
更复杂的如卷积更复杂。
卷积的滑动窗口原理,stride=1滑动步长为1
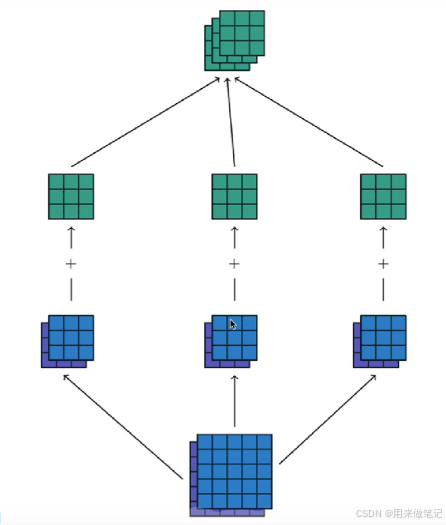
如果是channel=2则有两个kernel 将输出的两个结果点对点相乘
如果有多个输出通道,将不同的kernel得到的输出分别多通道输出
二维卷积演示:
import torch import torch.nn as nn import torch.nn.functional as F in_channels =1 out_channels = 1 kernerl_size =3 batch_size=1 ##样本数量 bias=False input_size=[batch_size,in_channels,4,4] ##通道数、长度、宽度 conv_layer = torch.nn.Conv2d(in_channels,out_channels ,kernerl_size,bias=bias) input_feature_map = torch.randn(input_size) ##产生input output_feature_map=conv_layer(input_feature_map) ## print(input_feature_map) print(conv_layer.weight) ##相当于权重,kernel 1*1*1*3=out_channels*in_channels*height*width print(output_feature_map) ##函数形式的卷积 output_feature_map1=F.conv2d(input_feature_map,conv_layer.weight)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
in_channels =1
out_channels = 1
kernerl_size =3
batch_size=1 ##样本数量
bias=torch.randn(1) ##默认通道数1
input_size=[batch_size,in_channels,4,4] ##通道数、长度、宽度
conv_layer = torch.nn.Conv2d(in_channels,out_channels ,kernerl_size,bias=bias)
input_feature_map = torch.randn(input_size) ##产生input
output_feature_map=conv_layer(input_feature_map) ##
print(input_feature_map)
print(conv_layer.weight) ##相当于权重,kernel 1*1*1*3=out_channels*in_channels*height*width
print(output_feature_map)
##函数形式的卷积
output_feature_map1=F.conv2d(input_feature_map,conv_layer.weight)
input = torch.radn(5,5)
kernel=torch.randn(3,3)
input=input_feature_map ##卷积输入特征图
kernel = conv_layer.weight.data ##卷积核
##1.原始矩阵运算实现二维卷积
def matix_multiplation_for_conv2d(input,kernel,bias=0,stride=1,padding=0):
if padding>0:
input=F.pad(input,(padding,padding,padding,padding))
input_h,input_w=input.shape
kernel_h,kernel_w=kernel.shape
##卷积输出的宽度和高度
output_h=(math.floor(input_h-kernel_h)/stride+1)
output_w=(math.floor(input_w-kernel_w)/stride+1)
output = torch.zeros(output_h,output_w)
for i in range(0,input_h-kernel+1,stride): ##对高度维度便利
for j in range(0,input_w-kernel_w+1,stride): ##对宽度维度便利
region=input(i:i+kernel_h,j:j+kernel_w) ##取出被核滑动到的区域
output[int(i/stride),int(j/stride)]torch.sum(region*kernel)+bias
return ouptput
mat_mul_conv_output=matix_multiplation_for_conv2d(input,kernel,padding=1)
print(mat_mul_conv_output)
pytorch_mul_conv_output=F.conv2d(input.reshape((1,1,input.shape[0])),kernel.reshape((1,1,kernel.shape[0],kernel.shape[1])))
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
in_channels =1
out_channels = 1
kernerl_size =3
batch_size=1 ##样本数量
bias=torch.randn(1) ##默认通道数1
input_size=[batch_size,in_channels,4,4] ##通道数、长度、宽度
conv_layer = torch.nn.Conv2d(in_channels,out_channels ,kernerl_size,bias=bias)
input_feature_map = torch.randn(input_size) ##产生input
output_feature_map=conv_layer(input_feature_map) ##
print(input_feature_map)
print(conv_layer.weight) ##相当于权重,kernel 1*1*1*3=out_channels*in_channels*height*width
print(output_feature_map)
##函数形式的卷积
output_feature_map1=F.conv2d(input_feature_map,conv_layer.weight)
input = torch.radn(5,5)
kernel=torch.randn(3,3)
input=input_feature_map ##卷积输入特征图
kernel = conv_layer.weight.data ##卷积核
##1.原始矩阵运算实现二维卷积
def matix_multiplation_for_conv2d(input,kernel,bias=0,stride=1,padding=0):
if padding>0:
input=F.pad(input,(padding,padding,padding,padding))
input_h,input_w=input.shape
kernel_h,kernel_w=kernel.shape
##卷积输出的宽度和高度
output_h=(math.floor(input_h-kernel_h)/stride+1)
output_w=(math.floor(input_w-kernel_w)/stride+1)
output = torch.zeros(output_h,output_w)
for i in range(0,input_h-kernel+1,stride): ##对高度维度便利
for j in range(0,input_w-kernel_w+1,stride): ##对宽度维度便利
region=input(i:i+kernel_h,j:j+kernel_w) ##取出被核滑动到的区域
output[int(i/stride),int(j/stride)]torch.sum(region*kernel)+bias
return ouptput
mat_mul_conv_output=matix_multiplation_for_conv2d(input,kernel,padding=1)
print(mat_mul_conv_output)
pytorch_mul_conv_output=F.conv2d(input.reshape((1,1,input.shape[0])),kernel.reshape((1,1,kernel.shape[0],kernel.shape[1])))

















 2545
2545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









