







一、实验目的
- 掌握伪分布式Hadoop环境下HBase的基本操作
- 熟练使用HBase Shell命令完成表管理、数据操作
- 实现关系型数据库到HBase表结构的转换
- 通过Java API编程完成HBase表的动态创建、数据插入与查询
二、实验坏境
| 类别 | 配置/版本 |
| 虚拟机软件 | VMware Workstation 17 |
| 操作系统 | CentOS 7.9 |
| JDK | 1.7.0_67 |
| Hadoop | 2.6.5 |
| IDE | IntelliJ IDEA 2023.1.2 |
| Shell | FinalShell |
| Hbase | 1.2.6 |
| ZooKeeper | 3.6.0 |
三、实验内容
任务1:HBase集群搭建
1.上传并且使用命令:tar -xvzf hbase-1.2.6-bin.tar.gz -C export/server解压HBase安装包
2.进入conf文件夹里修改HBase配置文件:
①配置hbase-env.sh文件:
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HBASE_CLASSPATH=/export/server/hbase-1.2.6
export HBASE_MANAGES_ZK=true②配置hbase-site.xml文件:
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://l20223613-01:8020/hbase3613</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<property>
<name>hbase.zookeeper.quorum</name>
<value>l20223613-02,l20223613-03,l20223613-04,l20223613-05</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/server/apache-zookeeper-3.6.0-bin/data</value>
</property>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>③修改regionservers文件:
l20223613-01
l20223613-02
l20223613-03
l20223613-04
l20223613-053.配置Hbase环境变量:使用vim /etc/profile打开配置环境变量的文件,
添加如下环境变量:
export HBASE_HOME=/export/server/hbase-2.1.0
export PATH=$PATH:${HBASE_HOME}/bin:${HBASE_HOME}/sbin
加载环境变量命令:source /etc/profile
4.启动Hbase:先使用start-dfs.sh启动hadoop集群,再使用命令start-hbase.sh启动hbase。
5.验证Hbase是否启动成功:在终端输入指令hbase shell,进入hbase shell客户端,在输入status,若输出类似于以下的内容,则启动成功:
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
Took 0.4562 seconds
任务2:HBase Shell命令操作
(1)列出所有表的相关信息
输入list命令即可查看当前所有表
结果实例:
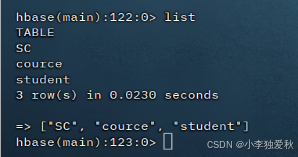
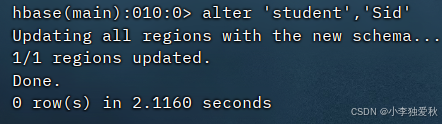
(2)向已经创建好的表添加和删除指定的列族或列
添加列族命令:alter 'student', 'Sid'
删除列族命令:alter 'student', METHOD => 'delete', NAME => 'Sid',注意要删除列族必须先得让表失效,如下图:
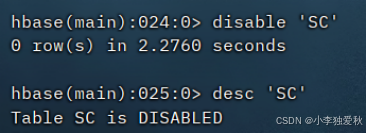
(3)清空指定表的所有记录数据
清空表数命令:truncate 'student',需先禁用表,再清空数据,如下图:
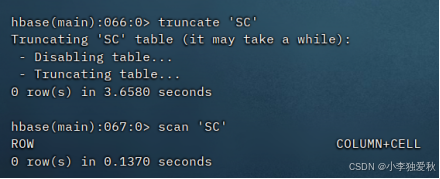
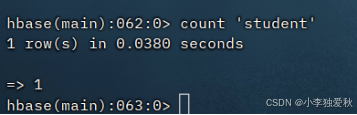
(4)统计表的行数
统计行数命令:count 'student',示例输出结果如下图:
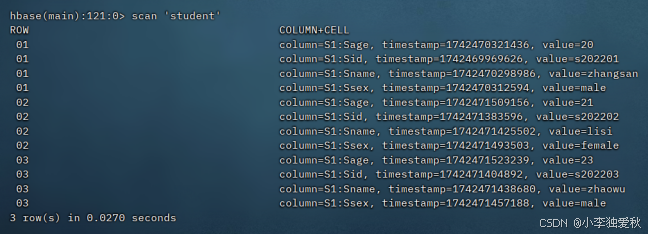
(5)输出指定表的所有记录数据
输出表所有记录数据内容命令:scan 'student',示例输出结果如下图:
任务3:关系型数据库转HBase表设计
1.原始表结构:
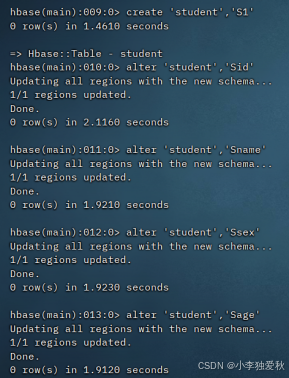
学生表(student):学号(Sid)、姓名(Sname)、性别(Ssex)、年龄(Sage)
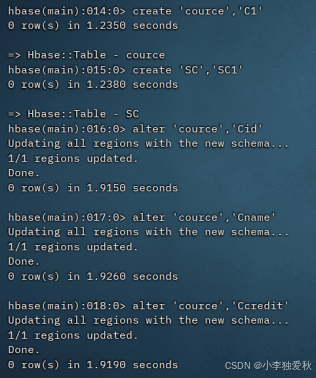
课程表(cource):课程号(Cid)、课程名(Cname)、学分(Ccredit)
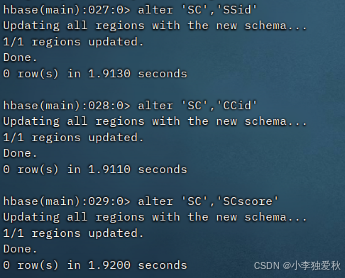
选课表(SC):学号(SSid)、课程号(CCid)、成绩(SCscore)
2.创建表:使用命令:create '表名称',‘列蔟名’
3.插入数据:使用命令: put '表名称','rowkey','列蔟名:列名',值’
4.查看表数据:使用命令:scan '表名称'
上述2,3,4具体运行结果在五、实验结果中
任务4:HBase编程实践
步骤:
(1)配置IDEA编程环境
1.导入新的pom依赖:打开软件IntelliJ IDEA 2023.1.2,配置之前配置过的pom.xml文件,用来添加新的依赖,在文件里面添加以下内容:
<repositories><!-- 代码库 -->
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies> <!-- 依赖项 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
<exclusions>
<exclusion>
<groupId>jdk.tools </groupId>
<artifactId>jdk.tools </artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies>
<build> <!-- 项目构建 -->
<plugins> <!-- 插件配置 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>接着重新加载一下maven项目,没有出问题则配置成功。
2.复制HBase和Hadoop配置文件:将以下三个配置文件复制到resource目录中:
①lhbase-site.xml:任务一中配置好的hbase-1.2.6/conf/hbase-site.xml
②lcore-site.xml:实验一中配置好的hadoop/core-site.xml
③llog4j.properties:在hbase-1.2.6/conf/下
3.创建Hbase连接:在项目中src/main/java下创建包cn.l20223613.hbase,接着创建类TableAmdinTest,我们接下来的代码都在这个文件里面编程。
(2)编写初始化方法,用于和hbase集群建立连接,源代码如下:
public static Connection connection=null;
public static Admin admin=null;
HTable htable;
static {
try {
//1、获取配置信息
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir", "hdfs://192.168.88.101:8020/hbase3613");
configuration.set("hbase.zookeeper.quorum","l20223613-01,l20223613-02,l20223613-03,l20223613-04,l20223613-05");
//2、创建连接对象
connection= ConnectionFactory.createConnection(configuration);
//3、创建Admin对象
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}(3)编写关闭客户端和hbase连接的代码,源代码如下:
public static void close(){
if (admin!=null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection!=null){
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}(4)测试一下能不能判断表是否存在,测试代码如下:
public static boolean isTableExist(String tableName) throws IOException {
boolean exists = admin.tableExists(TableName.valueOf(tableName));
return exists;
}
public static void main(String[] args) throws IOException {
System.out.println(isTableExist("student"));
//关闭资源
close();
}(5)实现以下功能:
①createTable(String tableName,String[] fields)
创建表,要求当hbase已经存在名为tableName的表的时候,先删除原有的表再创建新表
②addRecord(String tableName,String row,String[] fields,String[] values)
向表tableName,行row和字符串数组fields指定的单元格中添加对应的数据values。
③scanColumn(String tableName,String column)
浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null.
实现源代码和运行结果截图在五、实验结果中
四、出现的问题及解决方案
| 问题现象 | 解决方案 | 原理说明 |
| HBase Shell删除表失败 | 先disable '表名'再删除 | 需先禁用表,再清空数据 |
| Java API连接超时 | config.set("hbase.zookeeper.quorum", "localhost"); | ZooKeeper地址配置错误 |
| 执行hbase shell时提示"command not found"或无法进入交互界面 | ①在相应的文件中添加环境变量: export HBASE_HOME=.../hbase-1.2.6 export PATH=$PATH:$HBASE_HOME/bin 解决方法②:检查HDFS和ZooKeeper状态,确保start-dfs.sh和zkServer.sh start已执行。 | ①系统未正确配置HBase环境变量(如PATH未包含$HBASE_HOME/bin)。 ②伪分布式环境下未正确启动HDFS或ZooKeeper服务 |
| 创建表时报"TableAlreadyExistsException" | ①强制覆盖:编程时通过admin.deleteTable()先删除旧表再创建。 ②清理残留数据:删除HDFS上/hbase/data/default/表名目录 。 | HBase不允许重复创建同名表,且旧表可能残留元数据。 |
| 执行scan命令报"TableNotEnabledException" | 输入命令enable '表名' | 表处于禁用状态(如被disable后未重新启用)。 |
| HBase Shell连接超时或ZooKeeper错误 | ①检查hbase-site.xml配置: <property> <name>hbase.zookeeper.quorum</name> <value>本地节点</value> </property> ②使用telnet localhost 2181验证端口连通性。 | ①ZooKeeper地址配置错误: hbase.zookeeper.quorum未指定正确节点)。 ②防火墙阻塞2181端口(伪分布式需开放本地端口)。 |
| count命令统计行数不准确 | # 增加扫描缓存大小 count '表名', {INTERVAL => 100000, CACHE => 1000} | HBase的count命令默认单次扫描1000行,大表需多次扫描。 |
| 修改表结构时报"Procedure Still Running" | ①在hbase-site.xml中增加超时配置: <property> <name>hbase.client.sync.wait.timeout.msec</name> <value>600000</value> </property> ②重启HBase服务使配置生效。 | HBase元数据操作超时(默认超时时间过短)。 |
| 执行create或put时提示: | ①修改HDFS目录权限: hdfs dfs -chown -R hadoop:hadoop /hbase ②在HBase Shell中授予用户权限: hbase> grant 'hadoop', 'RW' # 授予读写权限 | 当前用户无HDFS目录权限(如HBase数据目录/hbase属主为hbase用户)。 |
| RegionServer频繁宕机导致命令失败操作过程中出现"NotServingRegionException" | ①检查RegionServer日志: (logs/hbase-hadoop-regionserver-*.log)定位OOM或HDFS连接问题。 ②调整JVM堆内存:在hbase-env.sh中设置: export HBASE_HEAPSIZE=4G # 根据物理内存调整 | RegionServer进程崩溃或与HDFS通信失败。 |
| 执行describe或list时提示无效语法 | ①查询官方文档确认命令格式(如describe在2.x需指定表名)。 ②升级HBase版本或使用兼容模式运行Shell。 | HBase版本与Shell命令语法不兼容(如2.x与1.x命令差异)。 |
| 启动日志报ConnectionLoss或Session expired,HMaster无法选举成功 | # 检查端口连通性 telnet zk-node 2181 # 清理ZooKeeper旧数据(谨慎操作) rm -rf /data/zookeeper/version-2/* # 调整最大连接数(zoo.cfg) maxClientCnxns=1000 | ①ZooKeeper数据目录权限不足或磁盘空间耗尽。 ②hbase-site.xml中hbase.zookeeper.quorum配置错误。 |
| RegionServer日志报UnknownHostException,或节点进程无法识别其他主机名 | # 统一所有节点的/etc/hosts配置 192.168.1.101 hadoop-master 192.168.1.102 hadoop-slave1 # 验证反向解析 host 192.168.1.101 | /etc/hosts未正确配置所有节点IP与主机名映射。 |
| ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet | 解决方法: hdfs dfsadmin -safemode leave 再重新启动HBase就可以了 | 在于使用虚拟机时不正常关闭了Hadoop,导致Hadoop进入了安全模式 |
| ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing | 方案1:删除zookeeper中的所有的/hbase目录 方案2:删除HDFS下的所有HBase目录 | HDFS中和Zookeeper中的HBase没有删除,所以这里需要将其进行删除 |
| MasterNotRunningException或PleaseHoldException: Master is initializing,RegionServer频繁下线。 | ①所有节点执行时钟同步 sudo ntpdate pool.ntp.org ②调整HBase容忍阈值(hbase-site.xml) <property> <name>hbase.master.maxclockskew</name> <value>180000</value> </property> | ①集群节点间系统时钟偏差超过HBase阈值(默认30秒)。 ②NTP服务未启用,虚拟机休眠后时钟未同步。 |
| 启动时报SLF4J: Class path contains multiple SLF4J bindings,日志功能异常。 | 在Maven中排除冲突依赖:<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> | HBase客户端依赖的slf4j-log4j12与其他库(如Hadoop)的日志实现冲突。 |
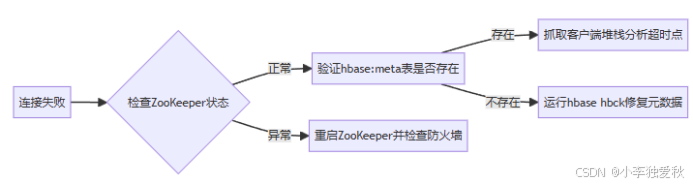
故障快速定位流程:
五、实验结果
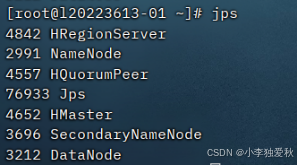
1.配置好hbase后,启动集权,然后输入jps指令运行结果:
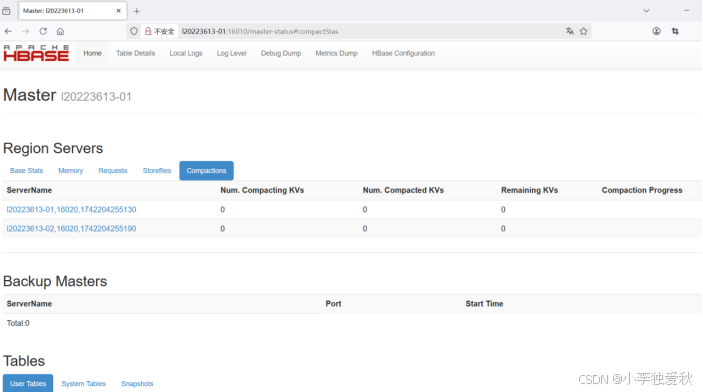
2.接着查看Hbase浏览器的结果截图:
3.创建stduent,cource,SC表结果截图:
4.向表中插入数据(图示插入一条数据的例子):
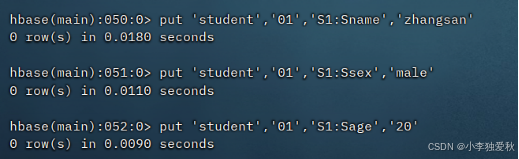
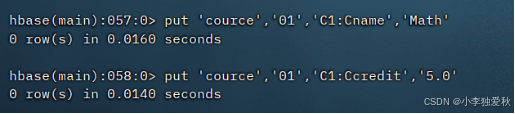
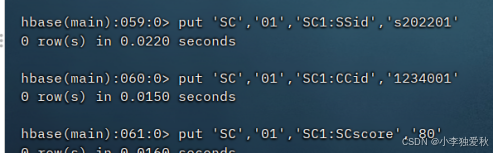
5.查看表中所有数据(以查看student为例子):
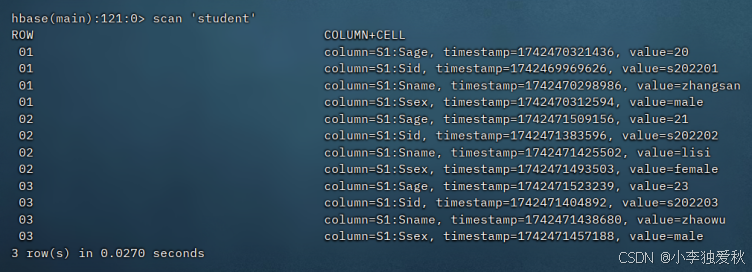
6.createTable(String tableName,String[] fields)
创建表,要求当hbase已经存在名为tableName的表的时候,先删除原有的表再创建新表,源代码如下:
@Test
public void creatTable() throws IOException{
//删除已存在的同名表
if(admin.tableExists(TableName.valueOf("test-connect"))){
admin.disableTable(TableName.valueOf("test-connect"));
admin.deleteTable(TableName.valueOf("test-connect"));
}
//表描述
HTableDescriptor desc=new HTableDescriptor(TableName.valueOf("test-connect"));
HColumnDescriptor cf=new HColumnDescriptor("test-connect".getBytes());
desc.addFamily(cf);
admin.createTable(desc);
}
代码运行结果截图:
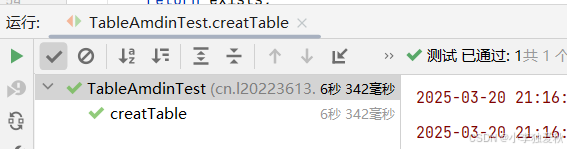
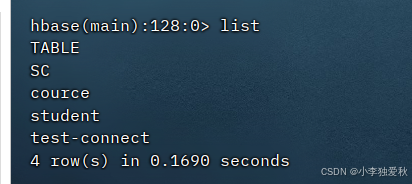
打开hbase shell客户端,输入list查看所有表,验证是否创建成功:
7.addRecord(String tableName,String row,String[] fields,String[] values)
向表tableName,行row和字符串数组fields指定的单元格中添加对应的数据values。源代码如下:
@Test
public void addRecord() throws RetriesExhaustedWithDetailsException, InterruptedIOException {
TableName studentTableName = TableName.valueOf("student");
Table studentTable = null;
try {
studentTable = connection.getTable(studentTableName);
} catch (IOException e) {
throw new RuntimeException(e);
}
// 构建ROWKEY、列蔟名、列名
String rowkey = "04";
Put put=new Put(rowkey.getBytes());
put.add("S1".getBytes(), "Sid".getBytes(), "202204".getBytes());
put.add("S1".getBytes(),"Sname".getBytes(),"yiyi".getBytes());
put.add("S1".getBytes(),"Ssex".getBytes(),"female".getBytes());
put.add("S1".getBytes(),"Sage".getBytes(),"22".getBytes());
// 使用Htable表对象执行put操作
try {
studentTable.put(put);
} catch (IOException e) {
throw new RuntimeException(e);
}
// 关闭表
try {
studentTable.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}代码运行结果截图:
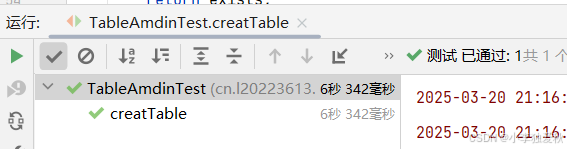
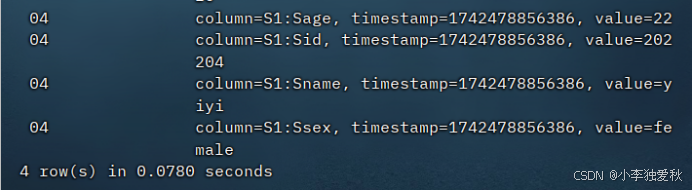
打开hbase shell客户端,输入scan ‘student’查看student表的所有信息,验证是否添加数据成功:
8.scanColumn(String tableName,String column)
浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null.源代码如下:
@Test
public void scanColumn() {
try {
htable=new HTable(admin.getConfiguration(),"student".getBytes());
} catch (IOException e) {
throw new RuntimeException(e);
}
String rowkey="04";
Get get=new Get(rowkey.getBytes());
Result rs= null;
try {
rs = htable.get(get);
} catch (IOException e) {
throw new RuntimeException(e);
}
Cell cell1=rs.getColumnLatestCell("S1".getBytes(), "Sid".getBytes());
Cell cell2=rs.getColumnLatestCell("S1".getBytes(), "Sname".getBytes());
Cell cell3=rs.getColumnLatestCell("S1".getBytes(), "Sage".getBytes());
Cell cell4=rs.getColumnLatestCell("S1".getBytes(), "Ssex".getBytes());
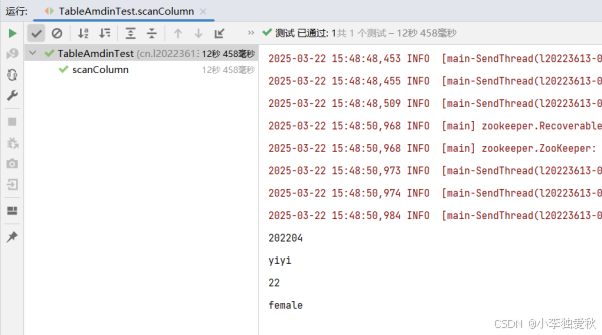
System.out.println(new String(CellUtil.cloneValue(cell1)));
System.out.println(new String(CellUtil.cloneValue(cell2)));
System.out.println(new String(CellUtil.cloneValue(cell3)));
System.out.println(new String(CellUtil.cloneValue(cell4)));
}代码运行结果截图:
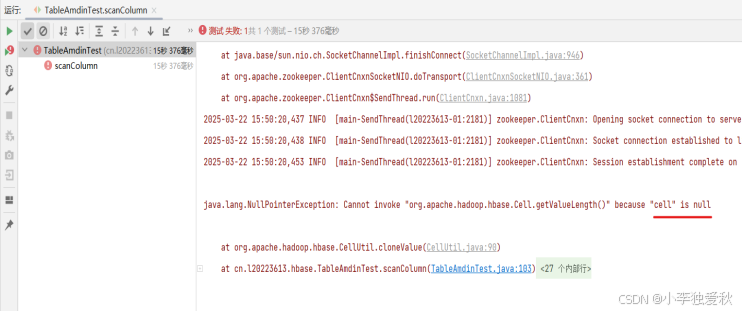
若将rowkey改成没有数据的“05”再运行代码,则报出java.lang.NullPointerException错误,结果如下图:
六、实验思考题
1. 请以实例说明HBase数据类型。
HBase作为分布式列式数据库,其数据类型的设计遵循“一切皆字节”的理念,核心存储基于二进制,但通过应用层序列化支持多种逻辑类型。以下是其数据类型分类、实例及典型应用场景的详细说明:
一、HBase原生支持的基本数据类型
1. 字符串类型(String Type)
-定义:以UTF-8或其他编码存储文本或可序列化的数据,最终转为字节数组。
-实例:用户姓名、地址、JSON字符串、URL等。
-场景:
①存储半结构化数据(如JSON对象)。
②日志文件中的文本日志记录。
③社交媒体的评论或帖子内容。
2. 二进制类型(Binary Type)
-定义:直接存储原始字节数组,无编码限制。
-实例:图片、音频、视频、序列化对象(如Protobuf消息)。
-场景:
①多媒体文件存储(如图库、视频平台)。
②加密数据的存储(如密钥、证书)。
③复杂数据结构的序列化存储(如机器学习模型参数)。
二、应用层扩展支持的数据类型
通过序列化/反序列化机制,HBase可支持以下逻辑类型:
3. 整数类(Byte, Short, Int, Long)
-定义:整数类型通过字节转换存储,范围与Java类型一致(如int占4字节,范围-2³¹~2³¹-1)。
-实例:用户年龄、订单数量、计数器。
-场景:
①实时统计(如网页访问量计数器)。
②交易系统中的金额计算(需结合高精度库避免溢出)。
4. 浮点类(Float, Double)
-定义:遵循IEEE 754标准的单/双精度浮点数。
-实例:温度传感器数据、商品价格、地理坐标。
-场景:
①物联网设备采集的测量值(如风速、湿度)。
②金融领域的实时股价波动记录。
5. 布尔类(Boolean)
-定义:1字节存储true或false的二进制表示。
-实例:用户订阅状态、开关标记。
-场景:
①标记用户是否已激活账号。
②系统配置中的开关控制(如功能是否启用)。
6.日期时间类(Date, Timestamp)
-定义:时间戳通常以长整型(毫秒数)或格式化字符串存储。
-实例:订单创建时间、日志记录时间。
-场景:
①时间序列数据分析(如日志按时间范围查询)。
②电商平台的订单生命周期追踪。
7. 字节类(Bytes)
-定义:直接操作原始字节数组,常用于自定义编码。
-实例:哈希值、二进制协议数据。
-场景:
①分布式系统中的唯一标识符(如UUID)。
②网络协议包的原始数据存储。
- 典型应用场景对比
| 数据类型 | 实例 | 典型场景 | 存储优化建议 |
| 字符串 | JSON配置文件 | 半结构化数据存储、日志文本 | 压缩编码(如Snappy)减少存储空间 |
| 二进制 | 用户头像图片 | 多媒体存储、加密数据 | 分块存储(避免大对象影响读写性能) |
| 整数类 | 商品库存量 | 计数器、统计指标 | 使用Long类型避免溢出 |
| 浮点类 | 气象站温度记录 | 科学计算、实时监控 | 双精度优先,注意精度丢失问题 |
| 布尔类 | 用户是否在线 | 状态标记、开关配置 | 结合位图(Bitmap)优化多标记存储 |
| 日期时间类 | 交易时间戳 | 时间序列分析、审计日志 | 行键设计包含时间(如YYYYMMDD_UID) |
| 字节类 | 加密的会话令牌(Token) | 安全数据存储、自定义编码 | 预计算哈希值加速查询 |
2.执行start-hbase.sh,启动了哪些进程?
(1)HMaster(主节点进程)
-角色:
集群的协调者,负责元数据管理(如表结构、Region分配)、负载均衡、故障恢复、权限控制等。
-启动条件:
所有模式均需启动主HMaster(默认在脚本指定的主节点上)。
若配置了备份HMaster(通过hbase-daemon.sh start master --backup或local-master-backup.sh),最多可启动9个备份。
-验证方式:
主节点执行jps命令,可见HMaster进程。
访问Web UI(默认端口16010)查看集群状态。
(2)HRegionServer(数据节点进程)
-角色:
存储实际数据,处理客户端读写请求,管理表的Region(分片)。
-启动条件:
在完全分布式模式下,每个数据节点(Slave)启动一个HRegionServer。
伪分布式模式下,主节点也会启动HRegionServer。
-验证方式:
数据节点执行jps,可见HRegionServer进程。
(3)ZooKeeper(协调服务进程)
-角色:
维护集群元数据(如RegionServer状态、Master选举)、分布式锁等。
启动条件:
若HBase配置为管理ZooKeeper(hbase-env.sh中HBASE_MANAGES_ZK=true),脚本会自动启动ZooKeeper进程(HQuorumPeer或QuorumPeerMain)。若使用外部ZooKeeper集群,则不会启动此进程。
验证方式:
jps命令显示HQuorumPeer或QuorumPeerMain进程。
(4)不同部署模式的进程差异:
| 部署模式 | 启动的进程 | 说明 |
| 独立模式 | 单JVM内启动:HMaster、HRegionServer、HQuorumPeer(ZooKeeper) | 所有组件运行于同一节点,适用于本地测试。 |
| 伪分布式模式 | 主节点:HMaster、HRegionServer、HQuorumPeer;无数据节点 | 模拟分布式环境,但所有进程集中在单节点。 |
| 完全分布式模式 | 主节点:HMaster;数据节点:HRegionServer;若配置备份Master,主节点可能启动多个HMaster | 生产环境标准部署,依赖外部HDFS和ZooKeeper(或由HBase管理)。 |
3. 编程中创建了哪些java对象?
一、HBase核心对象:
①Configuration configuration = HBaseConfiguration.create();
作用:用于存储HBase集群配置(如ZooKeeper地址)。
②connection = ConnectionFactory.createConnection(configuration);
作用:表示与HBase集群的长连接(线程安全,应全局共享)。
③admin = connection.getAdmin();
作用:用于管理HBase表的操作(如建表、删表)。
二、表结构定义对象
①HTableDescriptor desc = new HTableDescriptor(...);
已弃用:描述表的元数据(如表名、列族)。
②HColumnDescriptor cf = new HColumnDescriptor(...);
已弃用:描述列族的配置(如版本数、压缩格式)。
三、数据操作对象
①Put put = new Put(rowkey.getBytes());
作用:封装插入/更新操作(指定行键、列族、列、值)。
②Get get = new Get(rowkey.getBytes());
作用:封装单行查询操作(按行键获取数据)。
③htable = new HTable(...);
已弃用:表示与HBase表的连接(应改用Table接口)。
四、其他对象
Table studentTable = connection.getTable(studentTableName);
线程不安全的表操作接口(推荐通过Connection获取)。
五、完整对象列表总结:
| 对象类型 | 作用 | 是否已弃用 |
| Configuration | 存储集群配置 | 否 |
| Connection | 管理长连接 | 否 |
| Admin | 执行DDL操作 | 否 |
| HTableDescriptor | 定义表结构 | 是(2.x+) |
| HColumnDescriptor | 定义列族结构 | 是(2.x+) |
| Put | 插入/更新数据 | 否 |
| Get | 查询单行数据 | 否 |
| HTable | 表操作接口(旧版) | 是(1.0+) |
| Table | 表操作接口(新版) | 否 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











