







一、实验目的
- 掌握Linux虚拟机集群的安装与网络配置方法
- 完成Hadoop伪分布式环境的搭建
- 熟悉HDFS常用Shell命令操作
- 实现基于Java的HDFS文件系统编程
二、实验坏境
| 类别 | 配置/版本 |
| 虚拟机软件 | VMware Workstation 17 |
| 操作系统 | CentOS 7.9 |
| JDK | 1.7.0_67 |
| Hadoop | 2.6.5 |
| IDE | IntelliJ IDEA 2023.1.2 |
| Shell | FinalShell |
三、实验内容
任务1:安装Linux虚拟机(5台)
步骤:
- 使用VMware创建虚拟机,命名格式:姓名首字母+学号+序号(如l20223613-01)可以先创建一台然后再克隆其他四台
- 分配资源:2核CPU/4GB内存/20GB硬盘
- 网络配置选择NAT模式,配置静态IP(如192.168.88.101~105)
- 通过hostnamectl set-hostname设置主机名
任务2:Hadoop伪分布式搭建
步骤:
- 配置SSH免密登录:使用ssh-keygen -t rsa -b 4096命令创建密钥,再运行ssh-copy-id l20223613-02,可以获取另外一台虚拟机的密钥,这样可以实现ssh免密登录。
- 关闭防火墙:通过指令systemctl stop firewalld,systemctl disable firewalld两条指令关闭防火墙,接着使用vim文本编辑工具:vim /etc/sysconfig/selinux,将文件里的SELINUX设置为:disabled。
- 设置时区:通过指令date可以查看系统的时间信息,然后通过指令timedatectl set-timezone Asia/Shanghai 将时间修改为上海时区,再通过指令:ntpdate -u ntp.aliyun.com同步时间并开启ntp服务,最后通过命令:systemctl start ntpd和systemctl enable ntpd设置开机自启。
- 配置主机名映射:首先找到自己电脑下的hosts,将自己主机名和主机的ip地址填写在文件里面,hosts文件在C:\Windows\System32\drivers\etc目录下面。接着通过vim /etc/hosts命令修改虚拟机里面的hosts文件,修改内容同前面一样。
- jdk安装,配置环境变量:打开软件FinalShell,通过主机名和密码连接自己的主机,上传jdk文件到虚拟机,通过指令rpm -ivh jdk-7u67-linux-x64.rpm指令解压jdk,解压完成之后可以通过whereis java指令查看java文件夹解压到哪个位置,方便后面配置环境变量。接着运行指令:vim + /etc/profile,在文件最后加上:
export JAVA_HOME=/usr/java/jdk1.7.0_67
PATH=$PATH:$JAVA_HOME/bin
保存之后,执行命令. /etc/profile时文件生效,接着进入验证阶段,输入:以下三个指令
java -version 验证是否配置好java
javac -version 验证java编译文件是否配置好
jps 查看进程,验证jdk有没有完全配置好
6.部署hadoop坏境:打开软件FinalShell连接主机,然后上传hadoop-2.6.5.tar.gz文件到虚拟机里面,通过指令:tar -xvf hadoop-2.6.5.tar.gz -C /export/server/指令解压到export/server/目录下,通过指令:vim /etc/profile进入文件配置Hadoop环境变量,在文件后面加上:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存之后,执行命令. /etc/profile时文件生效,接着进入最重要的一步,修改配置文件(以我自己的例子为例):
①配置workers文件(把自己的虚拟机主机名写在这个文件里面:
l20223613-01
l20223613-02
l20223613-03
l20223613-04
l20223613-05②配置core-site-xml文件:
<property>
<name>fs.defaultFS</name>
<value>hdfs://l20223613-01:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>③配置dfs-site.xml文件:
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value> //nn是放namenode数据的文件夹
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>l20223613-01,l20223613-02,l20223613-03,l20223613-04,l20223613-05</value> //伪分布只要写一台主机名即可
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value> //dn是放datanodes数据的文件夹
</property>④配置hadoop-env-sh文件:
exportJAVA_HOME=/usr/java/jdk1.7.0_67
export HAD00P_HOME=/export/server/hadoop
Export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs以上四个文件配置后运行命令:hadoop namenode -format格式化namenode,接着输入命令:start-dfs.sh启动集群,输入指令jps,若显示了DataNode,NameNode,SecondaryNameNode,Jps四个则hadoop部署成功。
7.浏览器查看集群:接着在浏览器输入l20223613-01:50070即可查看HDFS浏览器。
任务3:熟悉hdfs的常用shell命令
(1)向hdfs上传文本文件
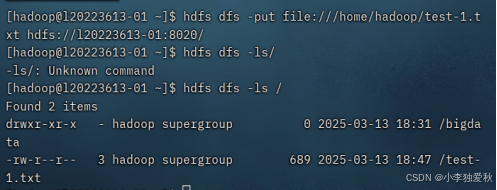
指令格式如下:
hdfs dfs -put file:///home/hadoop/test-1.txt hdfs://l20223613-01:8020/
简化版指令(不带协议头):hdfs dfs -put ./test-1.txt /实验结果截图如下:
(2)从hdfs下载文件
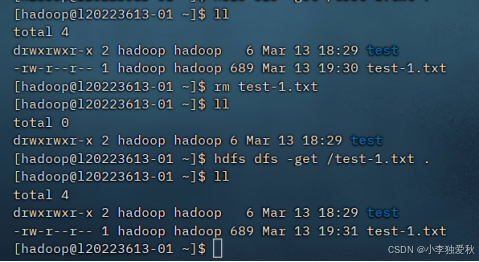
指令格式如下:
hdfs dfs -get /test-1.txt .实验结果截图如下:
(3)将hdfs指定文件的内容输出到终端
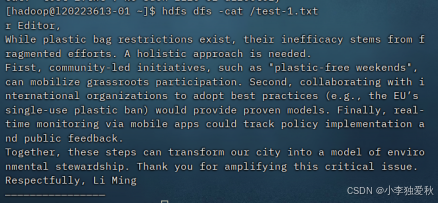
指令格式如下:
hdfs dfs -cat /test-1.txt实验结果截图如下:
(4)显示指定文件的详细信息
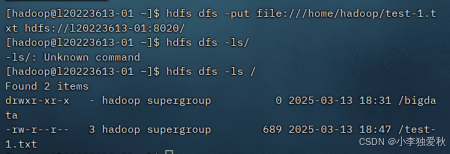
指令格式如下:
hdfs dfs -ls /实验结果截图如下:
(5)提供一个hdfs文件的路径,对该文件进行创建和删除操作
指令格式如下:
hdfs dfs -touchz /bigdata/exam1
hdfs dfs -rm /bigdata/exam1实验结果截图如下:
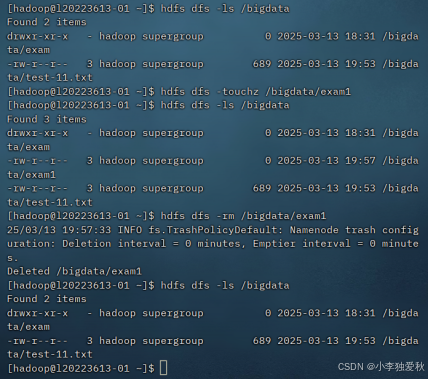
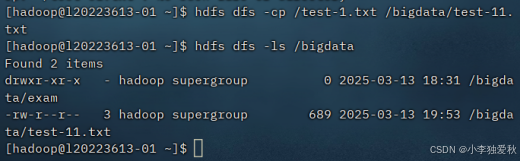
(6)将hdfs文件从源路径移动到目的路径
指令格式如下:
hdfs dfs -cp /test-1.txt /bigdata/test-11.txt(mv指令也可以)实验结果截图如下:
(7)创建一个约1.6M大小的文件(文件内容为10万行的 hello jsxy),然后设置块大小(1048576)上传文件
实验结果截图(指令在图中)如下:
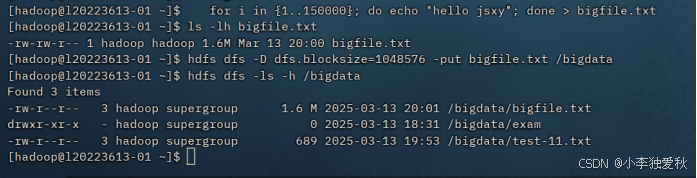
任务4:hdfs编程实践
步骤:
(1)配置IDEA编程环境
1.配置Hadoop环境变量:把前面下载的hadoop-2.6.5解压到文件夹里面,然后再本地电脑配置环境变量,例如我解压到:D:\JAVA\Hadoop\hadoop-2.6.5里面,然后在系统变量里面配置:
变量名是:HADOOP_HOME
变量值是:D:\JAVA\Hadoop\hadoop-2.6.5
2.bin文件夹文件配置:先下载两个小文件:winutils.exe和hadoop.dll,这两个文件放在D:\JAVA\Hadoop\hadoop-2.6.5\bin中,然后将bin目录的hadoop.dll文件拷贝到c:\windows\System32,可以在cmd里面输入命令:hadoop version查看windows是否配置hadoop成功。
3.配置IDEA编程环境:打开软件IntelliJ IDEA 2023.1.2,创建一个maven项目,配置pom.xml文件,用来添加依赖,在文件里面添加以下内容:
<dependencies> <!-- 依赖项 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
<exclusions>
<exclusion>
<groupId>jdk.tools </groupId>
<artifactId>jdk.tools </artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies>
<build> <!-- 项目构建 -->
<plugins> <!-- 插件配置 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
</project>接着重新加载一下maven项目,没有出问题则配置成功。
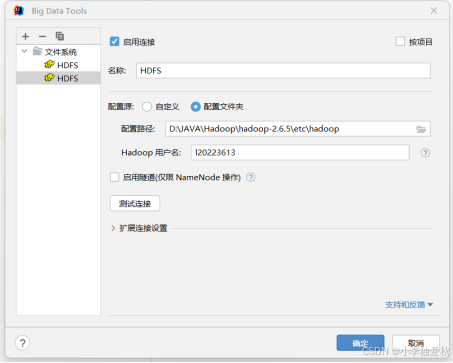
4.扩展知识(在IntelliJ IDEA 2023.1.2配置HDFS可视化工具):在文件里面的设置中找到插件,搜索插件Big Data Tools并且下载,下载成功后会出现在界面的右侧栏,如下图新建连接,配置路径选择之前伪分布式中配置的那些文件的文件夹,用户名可自己随便取,点击测试连接,成功之后即可直接操作hadoop文件系统,方便又迅速。
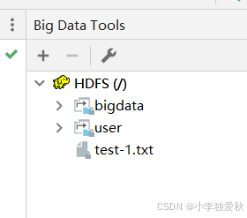
(2)编程实现创建目录、上传文件、显示文件块信息、读取文件部分内容等功能
1.在项目中src/main/java下创建包cn.l20223613.hdfs,接着创建类HDFSClient,我们接下来的代码都在这个文件里面编程。
2.编写初始化方法,用于和hdfs集权建立连接,源代码如下(有注释):
/**
* 初始化方法 用于和hdfs集权建立连接
*/
@Before
public void connect2HDFS(){
//设置客户端身份 以具备权限在hdfs上进行操作
System.setProperty("HADOOP_USER_NAME","hadoop");
//创建配置对象实例
conf = new Configuration();
//设置操作的文件系统是HDFS 并且指定HDFS操作地址
conf.set("fs.defaultFS","hdfs://l20223613-01:8020");
//创建FileSystem对象实例
try {
fs = FileSystem.get(conf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}3.编写关闭客户端和hdfs连接的代码,源代码如下:
/**
* 关闭客户端和hdfs连接
*/
@After
public void close(){
//首先判断文件系统实例是否为空,如果不为空,进行关闭
if(fs != null){
try {
fs.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}4.编程实现创建目录、上传文件、显示文件块信息、读取文件部分内容等功能的源代码和实验运行结果在 五、实验结果中。
四、出现的问题及解决方案
| 问题现象 | 解决方案 | 原理说明 |
| DataNode持续启动失败 | # 清除临时数据 rm -rf $HADOOP_HOME/tmp/dfs/data/* # 重新格式化 hdfs namenode -format start-dfs.sh | 多次格式化NameNode导致DataNode存储的旧ID不一致,临时目录残留旧元数据 |
| SSH免密登录仍需输入密码 | 检查authorized_keys权限设为600 | Linux密钥文件权限限制 |
| 浏览器无法访问50070端口 | 关闭防火墙:systemctl stop firewalld | 防火墙阻断Web UI访问 |
| 某一步配置错误 | 提前拍摄快照,出现问题的时候恢复快照 | 快照可以保留虚拟机之前的状态 |
| 运行jps出现process information unavailable 问题 | 输入指令:rm -rf /tmp/hsperfdata_* | 当主机断点或非正常关机后重启电脑,会有一些进程出现缓存没清理的情况从而导致异常 |
| HDFS上传文件时报权限拒绝 | 使用hdfs dfs -chmod 777 /目标目录修改权限 | HDFS默认权限限制非超级用户操作 |
| Java环境变量配置错误 | 在/etc/profile中补全JAVA_HOME路径并source生效 | Hadoop依赖JAVA_HOME定位JDK位置 |
| HDFS副本数警告 | 在hdfs-site.xml中设置dfs.replication=1 | 伪分布式环境下单节点无法满足默认3副本 |
| HDFS文件块大小未生效 | 上传时指定参数:-D dfs.blocksize=1048576 | Shell命令需显式覆盖配置文件参数 |
| 替换了文件winutils.exe和hadoop.dll,但是window配置hadoop还是失败 | 注意要和自己安装与hadoop版本一样的哪个文件 | 每个版本的hadoop下的bin目录的文件有区别 |
| IDEA编程报连接拒绝 | 确认core-site.xml中配置的fs.defaultFS与代码中一致 | 客户端与HDFS服务端RPC端口不匹配 |
| 主机名解析失败 | 在/etc/hosts中添加所有节点的IP与主机名映射 | Hadoop依赖主机名进行跨节点通信 |
| Java程序报ClassNotFound | 在IDEA中添加Hadoop依赖库(hadoop-common、hadoop-hdfs) | 缺少Hadoop客户端JAR包导致类加载失败 |
| HDFS文件显示大小为0字节 | 检查本地文件是否成功生成:ls -lh /path/to/file | 空文件或未完成写入导致元数据错误 |
| HDFS文件上传速度极慢 | 关闭IPv6:sysctl -w net.ipv6.conf.all.disable_ipv6=1 | IPv6协议解析延迟影响网络传输效率 |
| Permission denied错误,如:put: Access denied for user hadoop | hdfs dfs -mkdir -p /user/hadoop # 创建用户目录 hdfs dfs -chmod 777 /target_dir # 临时放宽权限 | HDFS用户权限未对齐或目录未预先创建 |
五、实验结果
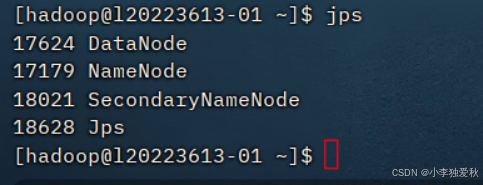
1.配置好jdk后输入jps指令运行结果:

2.部署好hadoop,输入start-dfs.sh启动集权后,输入jps指令运行结果:
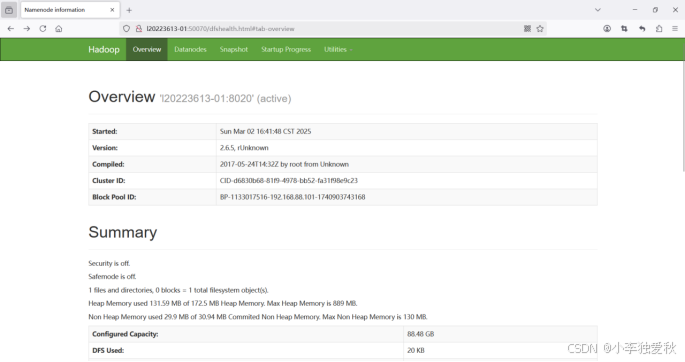
3.接着查看HDFS浏览器的结果截图:
4.编程实现创建目录源代码:
/**
* 创建文件目录
*/
@Test
public void mkdir(){
try {
if (!fs.exists(new Path("/juits_test(文件夹名称)"))){
fs.mkdirs(new Path("/juits_test"));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}代码运行结果截图:
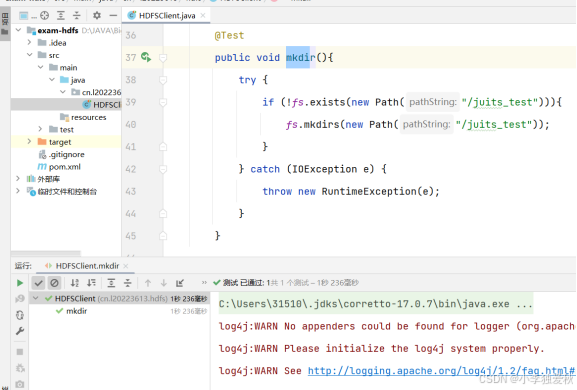
打开浏览器查看文件系统,验证是否成功:
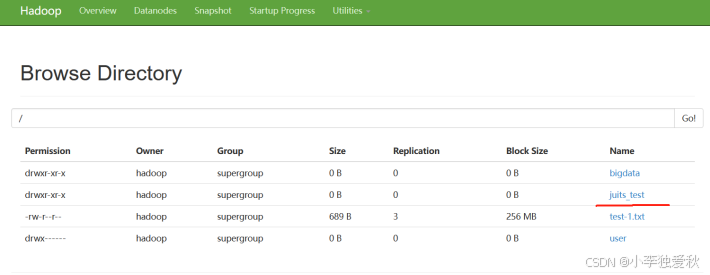
5.编程实现上传文件源代码:
/**
* 上传文件
*/
@Test
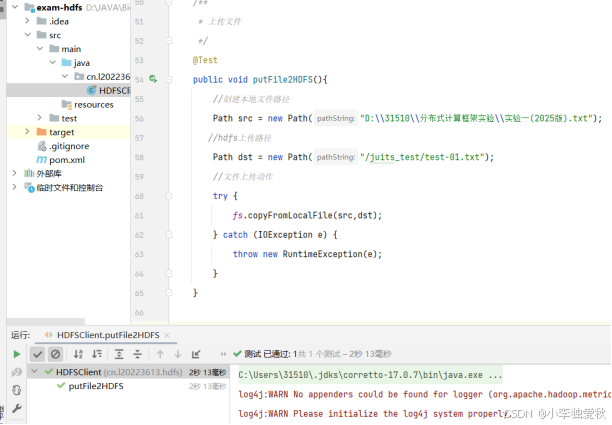
public void putFile2HDFS(){
//创建本地文件路径
Path src = new Path("D:\\31510\\分布式计算框架实验\\实验一(2025版).txt"); //里面写自己文件路径
//hdfs上传路径
Path dst = new Path("/juits_test/test-01.txt"); //上传到hdfs中对应位置
//文件上传动作
try {
fs.copyFromLocalFile(src,dst);
} catch (IOException e) {
throw new RuntimeException(e);
}
}代码运行结果截图:
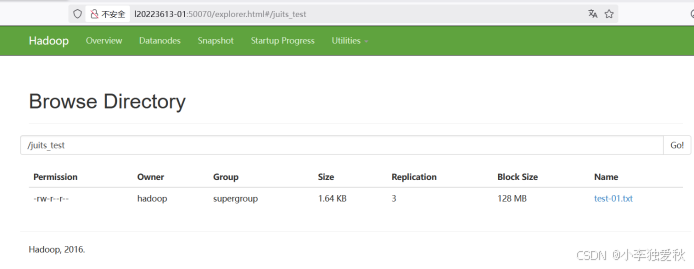
打开浏览器查看文件系统,验证是否成功:
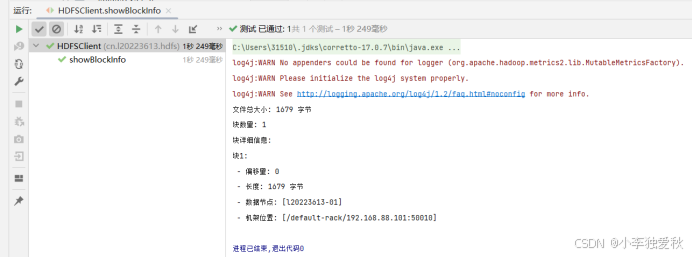
6.编程实现显示文件块信息源代码:
/**
* 显示文件块信息
*/
@Test
public void showBlockInfo() {
try {
// 指定需要查看块信息的HDFS文件路径
Path filePath = new Path("/juits_test/test-01.txt");
// 获取文件状态(含文件长度、权限等信息)
FileStatus fileStatus = fs.getFileStatus(filePath);
// 获取文件所有块的位置信息(从0偏移到文件末尾)
BlockLocation[] blocks = fs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
System.out.println("文件总大小: " + fileStatus.getLen() + " 字节");
System.out.println("块数量: " + blocks.length);
System.out.println("块详细信息:");
// 遍历每个块输出元数据
for (int i = 0; i < blocks.length; i++) {
BlockLocation block = blocks[i];
System.out.println("块" + (i+1) + ":");
System.out.println(" - 偏移量: " + block.getOffset());
System.out.println(" - 长度: " + block.getLength() + " 字节");
System.out.println(" - 数据节点: " + Arrays.toString(block.getHosts()));
System.out.println(" - 机架位置: " + Arrays.toString(block.getTopologyPaths()));
}
} catch (IOException e) {
throw new RuntimeException("获取块信息失败: " + e.getMessage(), e);
}
}代码运行结果截图:
7.编程实现读取文件部分内容源代码:
/**
* 读取文件部分内容
*/
@Test
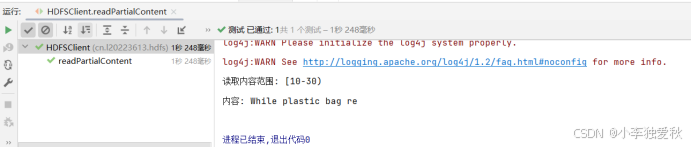
public void readPartialContent() {
Path hdfsPath = new Path("/test-1.txt");
// 定义读取范围:从第10字节开始读取20字节
long startOffset = 10;
int lengthToRead = 20;
try (FSDataInputStream in = fs.open(hdfsPath)) {
// 定位到指定偏移量
in.seek(startOffset);
byte[] buffer = new byte[lengthToRead];
int bytesRead = in.read(buffer, 0, lengthToRead);
System.out.println("读取内容范围: [" + startOffset + "-" + (startOffset + bytesRead) + ")");
System.out.println("内容: " + new String(buffer, 0, bytesRead, StandardCharsets.UTF_8));
} catch (IOException e) {
throw new RuntimeException("部分读取失败: " + e.getMessage(), e);
}
}代码运行结果截图:
六、启动过程中如果发现某个datanode出现问题,如何处理?
一、问题定位:
(1)检查DataNode日志:
DataNode日志通常位于$HADOOP_HOME/logs/或/var/log/hadoop-hdfs/目录下,文件名为hadoop-hdfs-datanode-<hostname>.log。重点关注以下错误类型:
——Incompatible namespaceIDs或Incompatible clusterIDs(namespaceID或clusterID不一致)
——java.io.IOException: Cannot lock storage(存储目录被锁定)
——java.net.NoRouteToHostException(网络连接问题)
——Permission denied(目录权限错误)
——Disk space full(磁盘空间不足)
(2)使用命令行工具验证状态
——执行jps命令确认DataNode进程是否存活。
_访问NameNode Web UI(默认端口50070),检查活跃DataNode列表是否包含问题节点。
二、问题解决:
(1)namespaceID或clusterID不一致
原因:多次执行hdfs namenode -format导致NameNode与DataNode的ID不匹配。
解决步骤:
方法一(数据可丢失时):
①停止集群:stop-all.sh
②删除所有DataNode节点的数据目录(路径由dfs.data.dir配置,默认如/tmp/dfs/data)。
③ 重新格式化NameNode:hdfs namenode -format
④ 启动集群:start-all.sh
方法二(保留数据):
① 手动同步ID:
—在NameNode的VERSION文件(路径如/tmp/dfs/name/current/VERSION)中获取clusterID。
—在问题DataNode的VERSION文件(路径如/tmp/dfs/data/current/VERSION)中修改clusterID与NameNode一致。
② 重启DataNode:hadoop-daemon.sh stop datanode → hadoop-daemon.sh start datanode
(2)存储目录权限问题
原因:DataNode本地目录权限不足或归属用户错误。
解决步骤:
① 检查目录权限:ls -l /path/to/dfs/data
② 修改权限(以Hadoop用户为例):
| chown -R hadoop:hadoop /path/to/dfs/data chmod 700 /path/to/dfs/data |
③ 重启DataNode服务。
(3)防火墙或SELinux限制
原因:防火墙阻止DataNode与NameNode通信(默认端口50010/50020)。
解决步骤:
① 关闭防火墙:
| systemctl stop firewalld |
② 禁用SELinux:
| setenforce 0 # 临时关闭 sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config # 永久关闭 |
(4) 磁盘空间不足或损坏
原因:DataNode存储目录所在磁盘写满或物理损坏。
解决步骤:
① 检查磁盘空间:df -h
② 清理临时文件或迁移数据:
—删除过期数据:hdfs dfs -rm -skipTrash <path>
—扩展磁盘或挂载新存储设备。
③ 若磁盘损坏:
—更换磁盘后,修改hdfs-site.xml中dfs.datanode.data.dir指向新路径。
—调整dfs.datanode.failed.volumes.tolerated允许容忍的磁盘故障数。
(5) 集群时间不同步
原因:节点间时间偏差超过阈值(默认5分钟)导致心跳超时。
解决步骤:
① 安装NTP服务并同步时间:
| ntpdate cn.pool.ntp.org # 手动同步 systemctl enable ntpd # 启用NTP服务 |
② 验证时间同步:ntpq -p
(6)配置文件错误
原因:配置文件(如hdfs-site.xml、core-site.xml)不一致或参数错误。
解决步骤:
① 对比正常节点与问题节点的配置文件,确保所有参数一致。
② 检查关键配置项:
| <!-- hdfs-site.xml --> <property> <name>dfs.datanode.data.dir</name> <value>/data1/hdfs/data,/data2/hdfs/data</value>//你虚拟机的主机名,伪分布式只有一个 </property> <!-- core-site.xml --> <property> <name>fs.defaultFS</name> <value>hdfs://namenode:9000</value> </property> |
③ 同步配置文件后重启服务。
三、问题预防:
(1)避免频繁格式化NameNode:仅在首次部署或灾难恢复时执行hdfs namenode -format。
(2)定期监控磁盘与日志:通过工具(如Ambari、Cloudera Manager)监控磁盘使用率和日志异常。
(3)配置自动化运维:使用Ansible或Chef同步配置文件和启动脚本。
(4)备份关键数据:定期备份NameNode元数据(fsimage和edits)至异地存储




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











