






目录
简介
朴素贝叶斯(naive Bayes)算法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布。然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。不同于其他分类器,朴素贝叶斯是一种基于概率理论的分类算法;总体来说,朴素贝叶斯原理和实现都比较简单,学习和预测效率较高,是一种经典而常用的分类算法。其中的朴素(naive)是指的对于数据集中的各个特征(feature)都有较强的独立性假设,并未将特征之间的相关性考虑其中。
贝叶斯公式
贝叶斯定理:
其中,称为后验(posterior)概率;
是类先验(prior)概率;
是样本x相对于类标记c的类条件概率(class-conditional proability),或称为似然(likelihood)概率;
是用于归一化的证据(evidence)因子。对于给定样本x,证据因子
与类别标记无关,因此估计后验概率
的问题就转化为如何基于训练数据D来估计先验概率
和似然
。
先验概率: 根据以往经验或经过数据统计得到的概率。例如我们可以通过统计训练数据集来计算得到先验概率。
后验概率:事情已经发生,求这件事情发生的原因是由某个因素引起的可能性的大小。比如称为
的后验概率,即它是在观察到事件x发生之后计算得到的。
贝叶斯定义之所以有用,是因为我们通常很难直接得到后验概率,但是先验概率
和似然概率
反而比较好得到,通过这两者我们可以计算得到后验概率。实际上,机器学习所要实现的就是基于有限的训练样本集合尽可能准确地估计出后验概率
。一般来说有两种策略:给定
,直接建模
来预测
,这样得到的是“判别式模型”(discriminative models),常见的包括决策树模型、神经网络、支持向量机、逻辑回归模型等等;也可以对联合概率分布
建模,然后再由此获取
,这样得到就是“生成式模型”(generative models),比如本文介绍的朴素贝叶斯模型。
极大似然估计
贝叶斯公式确定了,现在的问题变成了如何从训练样本集合中去估计先验概率和似然
。类先验概率
表达了样本空间中各类样本所占的比例,根据大数定律,当训练集包含充足的独立同分布样本时,
可通过各类样本出现的频率来进行估计。但是对于类条件概率
来说,由于它涉及到了关于
所有属性的联合概率,实际上是无法进行估计的。比如每个样本多具有
个属性,每个属性都是二值的,那么样本空间将有
种可能的取值,在实际应用中,样本一般都具有多个特征,并且每个特征的取值也各不相同,这样组合下来的取值会远训练样本的数量。这会使得条件概率分布
具有指数级数量的参数,造成组合爆炸的问题。
朴素贝叶斯对条件概率分布做了条件独立性的假设,也正是因为这一假设,朴素贝叶斯因此得名。具体来说,条件独立性假设是:
朴素贝叶斯实际上学习到生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征在类别确定的条件下是条件独立的。这一假设使得朴素贝叶斯变得简单,但是特征实际上一般是互相有依赖的,并不完全满足这个假设,因此朴素贝叶斯也牺牲了一定的准确率。
有了上述前提之后,我们现在使用极大似然估计的方法来估计先验概率和似然
.
先验概率的极大似然估计是:
其中是样本集的总数,K是类别的总数,
表示事件。
离散特征下,条件概率的极大似然估计是:
其中,代表第
代表第
个特征;
是第
个特征可能取的第
个值。
在连续特征下,这里首先假设概率密度函数则参数
和
的极大似然估计为:
也就是说,通过极大似然估计得到的正态分布均值就是样本均值,方差就是的均值,这显然是一个符合直觉的结果。在离散特征属性下,也可以通过类似的方式来估计类条件概率。
朴素贝叶斯算法步骤
1.计算先验概率和条件概率
2.对于给定的实例,计算:
3.确定x的分类:
实例解析
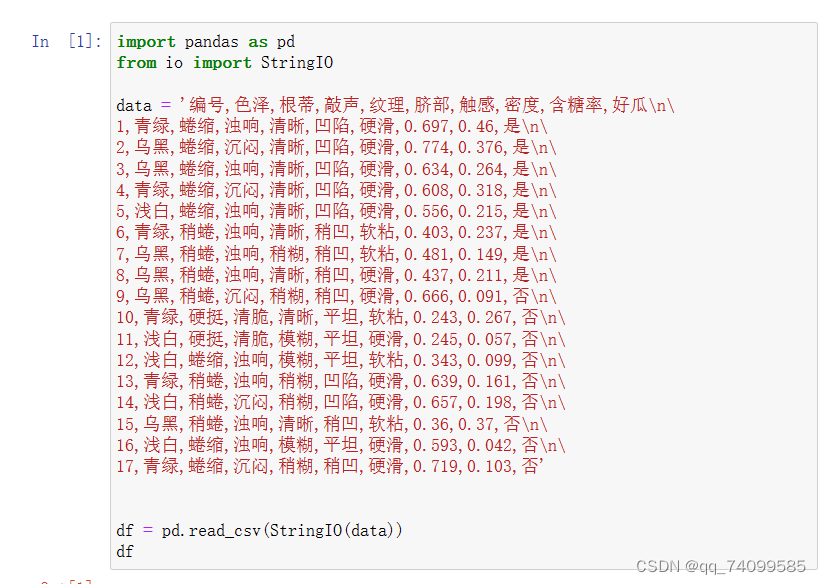
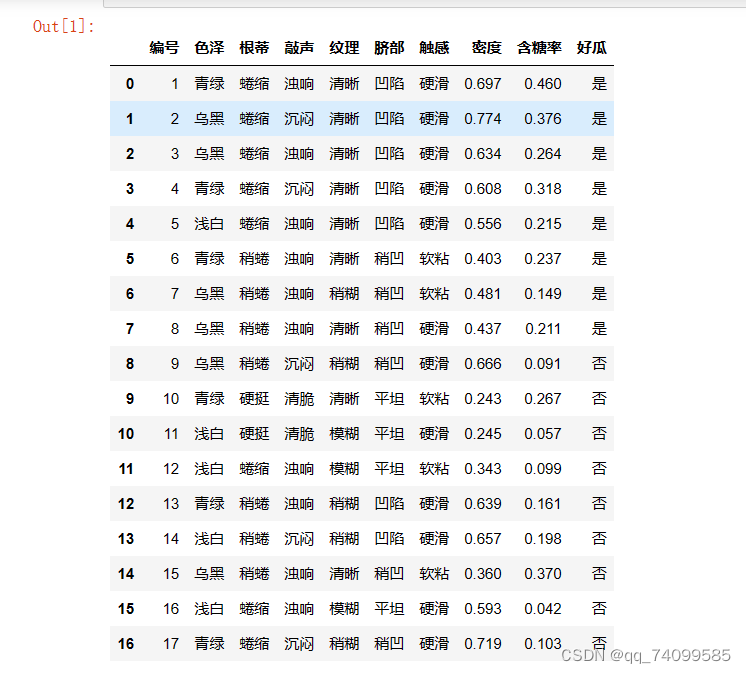
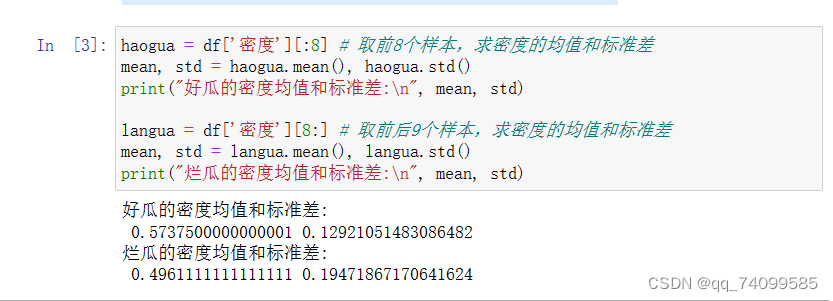
下面使用西瓜书中的西瓜数据集3.0来演示一下朴素贝叶斯的整体计算流程。训练样本数据集如下:
代码实践
本文不打算自己手写一个朴素贝叶斯的实现,sklean包中包含了各种贝叶斯算法模型,我们依旧是基于西瓜数据集3.0,来使用sklearn中集成的贝叶斯模型来预测上一节的测试样本。
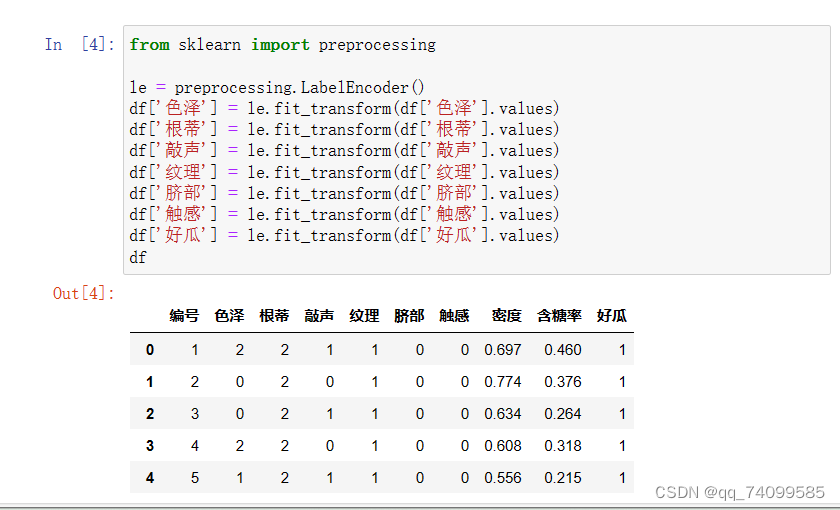
由于原始的离散特征属性是字符串型的,模型无法处理,我们首先需要进行数据预处理,使用LabelEncoder将其转换成数值类型。代码如下:
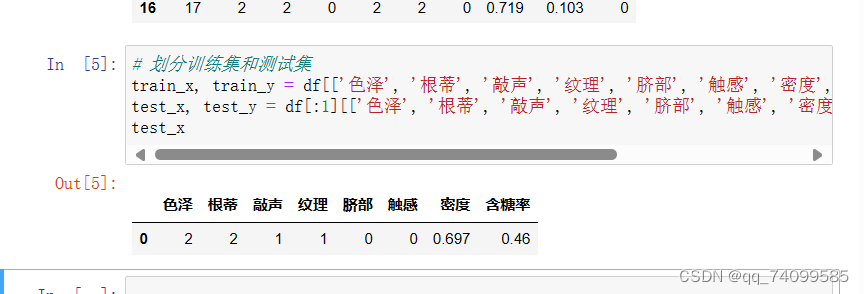
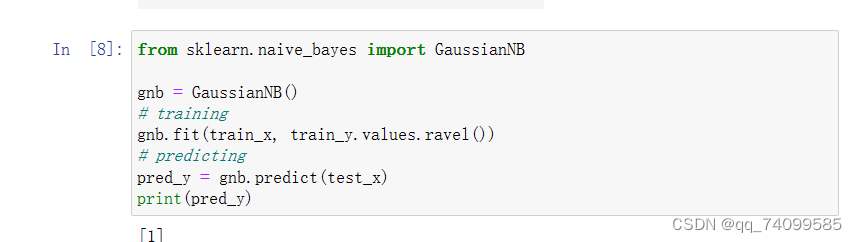 遇到的问题
遇到的问题
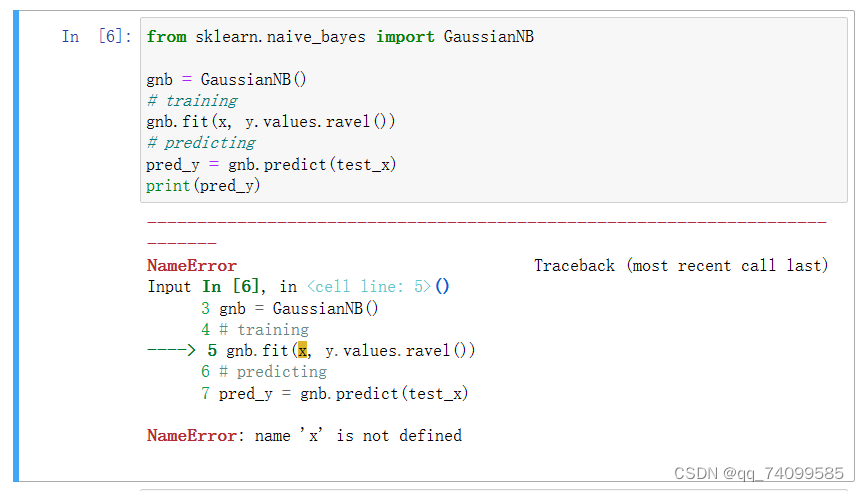
第一次进行训练的时候,把训练集的x,y变量名输错了,之后更改过来了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









