






目录
一、概述
在机器学习模型搭建好之后,需要对模型进行评估,针对不同的算法模型有不同的评估方法,比如:分类算法、回归算法、聚类算法等,本文主要是针对分类算法的模型评估方法进行总结整理,便于自己对评估方法的进一步理解和随时查阅。
二、常见的分类模型评估指标
在介绍分类评估方法之前,首先介绍一个比较重要的概念:混淆矩阵,后续的评估方法都是在此基础之上定义的,对于分类模型而言(这里仅以最简单的二分类为例,假设只有0和1两类),其结果主要有以下四种:
- 实际为正、结果为正,预测正确
- 实际为正、结果为负,预测错误
- 实际为负、结果为正,预测错误
- 实际为负、结果为负,预测正确
介绍完混淆矩阵,接下来我们介绍常用的评价标准,主要包括:准确率、精确率、召回率、F1值、ROC曲线、AUC、P-R、KS曲线等
准确率
准确率很好理解,就是预测正确的占比,其公式为:
accuracy = (TP+TN)/(TP+FP+FN+TN)
精确率
也称为查准率,在真实值为正的样本中,预测正确的样本占比,其计算公式表示为:
precision = TP/(TP+FP)
召回率
也称为查全率,在预测值为正的样本中,预测为正的样本占比,其计算公式表示为:
recall =TP/(TP+FP)
F1-Score
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0,其公式为:
F1 = 2*precision*recall/(precision+recall)
ROC曲线
对于ROC曲线,其横、纵坐标分别为:伪正率(FPR)、真正率(TPR)。其中:
真正率为实际为正的样本中,被判断为正的比例,公式如下:
TPR = TP/(TP+FN)
可以看到真正率的计算公式和召回率的计算公式是一样的
假正率为实际为负,被错误判断为正的比例,公式如下:
FPR = FP/(FP+TN)
ROC曲线的绘制主要我们根据多个阈值来计算出多组FPR和TPR(比如在逻辑回归中我们可以调整阈值如0.25、0.5、0.75等,这样我们就可以绘制出多组值绘制出ROC曲线。
ROC的计算方法同时考虑了学习器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器做出合理的评价。ROC对样本类别是否均衡并不敏感,这也是不均衡样本通常用ROC评价学习器性能的一个原因,其中ROC曲线越往上靠近模型性能越好(为啥越考上越好,纵坐标为真正率越大越好),
AUC
AUC是一个模型评价指标,只能用于二分类模型的评价,对于AUC我们记住,其就是ROC曲线下面的面积,AUC=1.0时表示模型最好,随机猜测的为0.5,其值越高,模型性能越好。
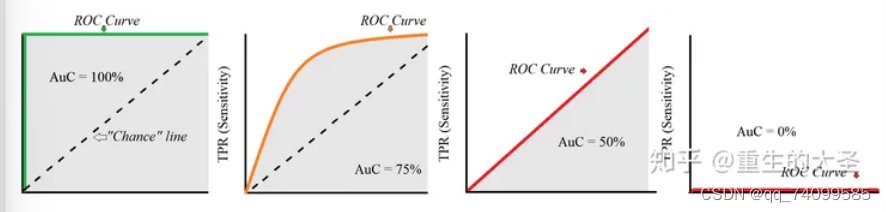
(来自于网络,侵权删)
三. ROC与PR曲线的对比
1.在正负样本极度不平衡时,关注PR曲线,ROC可能掩盖模型的差异
首先,我们先来比较一下两个模型分别利用ROC和PR曲线进行评估的结果,如下图所示:
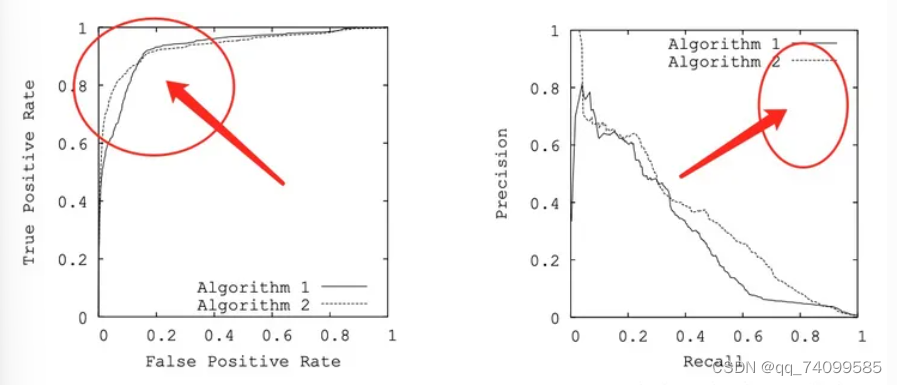
从图中我们可以得出两个相反的结论:
从ROC曲线上,两个模型表现都很不错,在FPR比较低的情况,TPR能够快速地靠近左上角区域,这样对应的AUC会较高;
从PRC曲线上,就会觉得模型性能比较差,远离了右上角区域,这意味着在召回率高的情况下,精确率差的一塌糊涂
有了上述比较直观的比较之后,我们心里会倾向于认为这两个模型都有很大的提升空间,同时我们也想弄清楚造成这一现象的原因。根据其他网友的描点,图a中TPR=0.8时,FPR约为0.1, 由于TPR=Recall, 因此可以大约认为图b中,Recall=0.8, Precision=0.05, 同时假定数据集中仅有100个正样本, 有了上述假设,我们就可以根据公式,推导出混淆矩阵上的各个指标了:
1.TPR = TP/真实正样本数目 = TP/100 = 0.8,=>TP = 80;
2.Precision = TP/(TP+FP) = 80/(80+FP) = 0.05,=>FP = 1520;
3.FPR = FP/真实负样本数目 = 0.1,=>真实负样本个数 = 15200;
4.正负样本比例可以得出:100/15200 = 0.00658
对于上述千6的正负样本比,还不是特别悬殊,我们可以再举另外一个例子(来源于Kaggle),假设真实样本中有100个正样本,(1000000-10)个负样本,设置不同的阈值,得到前100, 前2000个样本预测为正样本。
根据计算结果,我们可以发现:
- 两个模型在TPR,FPR上相比差异不大,尤其是FPR上,由于负样本占主导地位,即使将预测正样本的个数从100调到2000,两者之间的差异也是很小的;
- 而在Precision和Recall上, Precision显示出了明显的差异,0.9 VS 0.047;
- 原因在于,Precision,Recall在计算时,是不会考虑真实负样本的个数的,而ROC曲线上,FPR在计算时考虑了真实负样本的, 当负样本占据主导时(FPR的分母很大), FPR上体现不出差异来;
- 因此,在极度不平衡的情况下,优先要看PR曲线;
四. 分析不同k值下的ROC曲线
1,绘制ROC曲线
要分析不同k值下的ROC曲线,我们首先需要绘制出来不同k值下的ROC曲线。
第一步,我们需要准备一个数据集,这里我选取了,skearn自带的鸢尾花数据集。
# 准备数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只使用前两个特征进行简化
y = (iris.target == 2).astype(np.int) # 将问题转化为二分类问题,只关注类别2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) 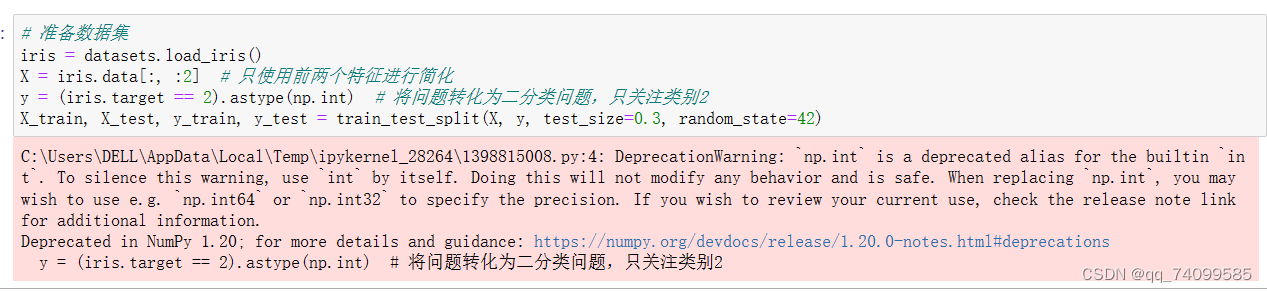
然后我们选择k值的范围,然后定义三个变量,用来存储不同k值下的TPR和FPR。
# 选择k值范围
k_values = [1, 3, 5, 7, 9]
# 存储不同k值下的TPR和FPR
tprs = []
fprs = []
aucs = [] 对于每个k值,训练模型并计算ROC曲线相关指标
# 对于每个k值,训练模型并计算ROC曲线相关指标
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_score = knn.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_score)
tprs.append(tpr)
fprs.append(fpr)
sauc = auc(fpr, tpr)
aucs.append(sauc) 最后一步,就是绘图
# 绘制ROC曲线
plt.figure()
lw = 2
colors = 'r', 'g', 'b', 'c', 'm'
for i, (fpr, tpr, auc) in enumerate(zip(fprs, tprs, aucs)):
plt.plot(fpr, tpr, color=colors[i], lw=lw, label='k={:.0f}, AUC={:.2f}'.format(k_values[i], auc))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve Analysis for Different k Values')
plt.legend(loc="lower right")
plt.show() 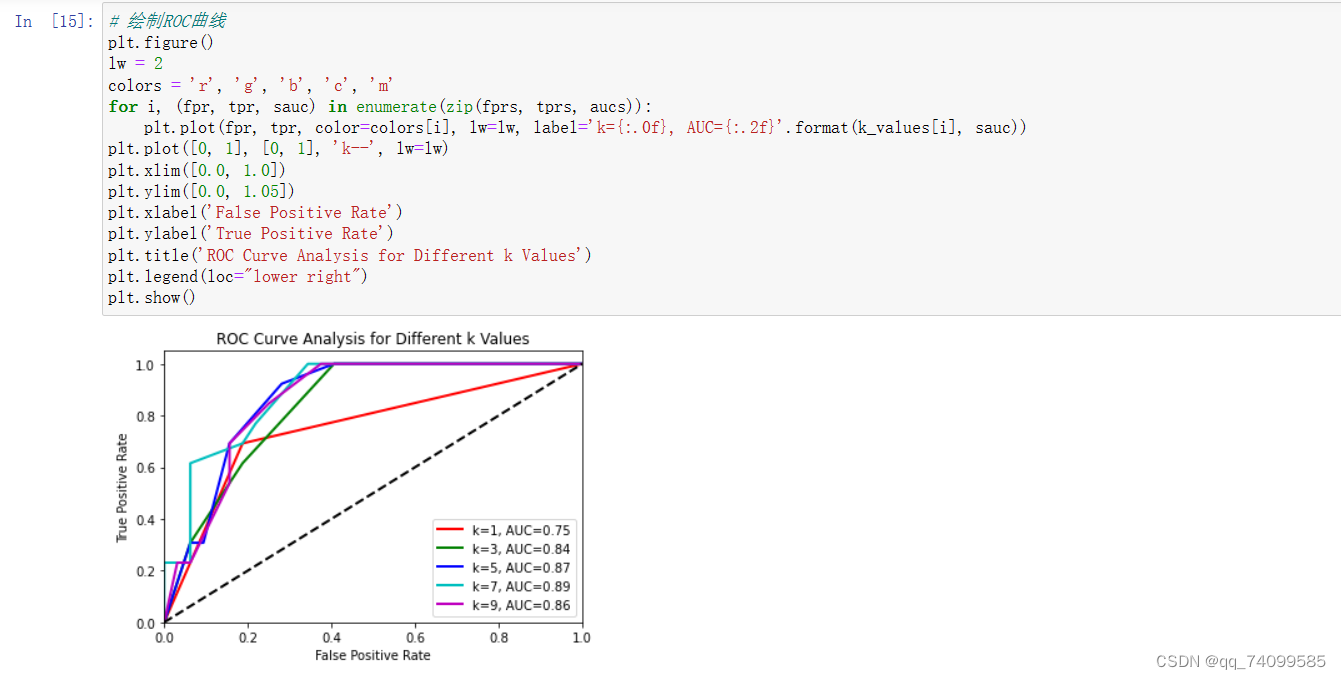
2.结果分析
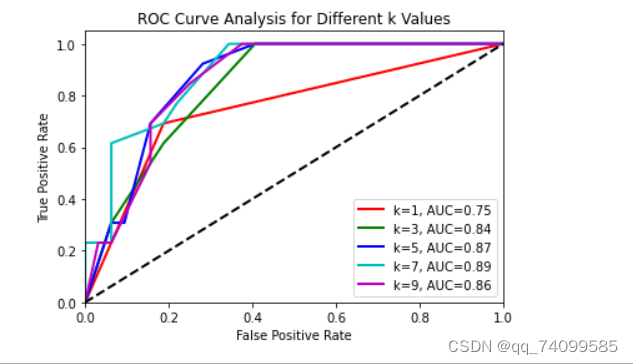
我们对这个图进行分析,首先从k值的角度来进行分析, 一般来说,较小的k值可能导致分类器对噪声和局部异常值更加敏感,而较大的k值可能使分类器过于平滑,忽略数据的局部结构。因此,选择一个中间的k值。其次就是AUC值,AUC(Area Under the Curve)值衡量了分类器在所有可能分类阈值下的平均性能。AUC值越接近1,说明分类器的性能越好,即其正确地将正例排在负例之前的概率越高。通过观察不同k值下的AUC值,我们可以比较各个k值对应的分类器性能。如果某个k值的AUC值明显高于其他k值,那么这个k值可能是较为合适的。
综上所述,我认为在这个模型中,应该选取k=7.
五.问题和解决办法
1.在我对于每个k值,训练模型并计算ROC曲线相关指标时,出现了如下报错:
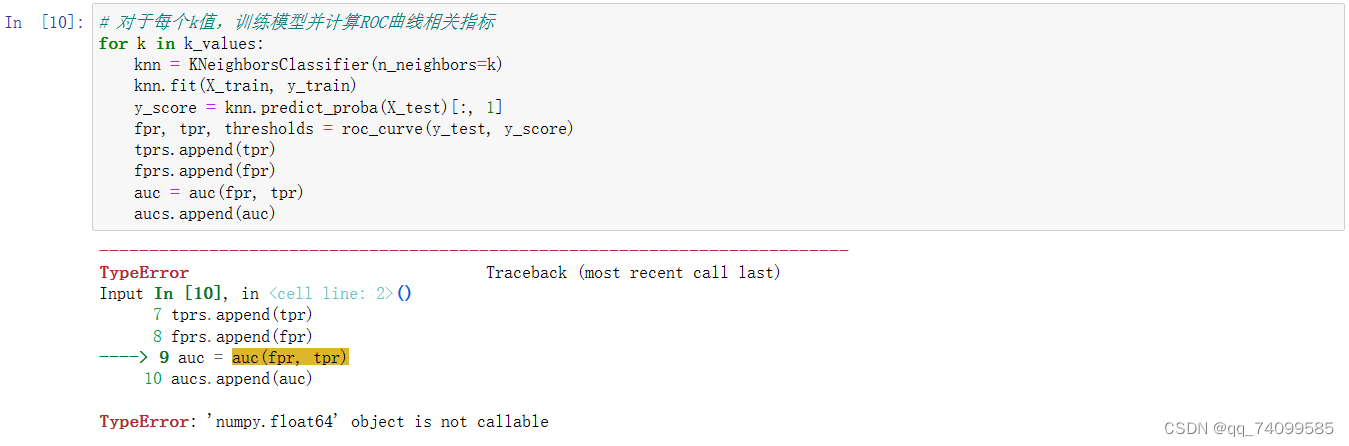
这是因为,我把函数的名字用来定义了一个变量,所以才出现了这样的报错,所以,对变量名修改后,就可以正常运行了。

















 2254
2254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









