






1机器学习
简单来说,机器学习就是通过算法,使得机器能从大量历史数据中学习规律,并利用规律对新的样本做智能识别或对未来做预测。
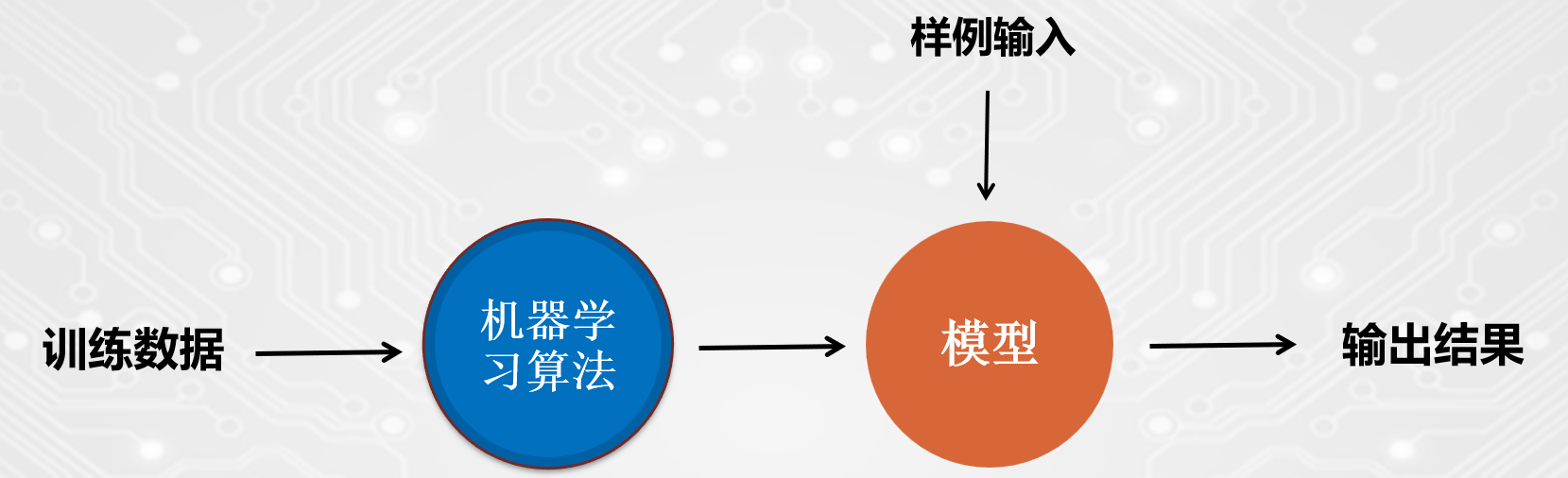
与传统的为解决特定任务而实现的各种软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
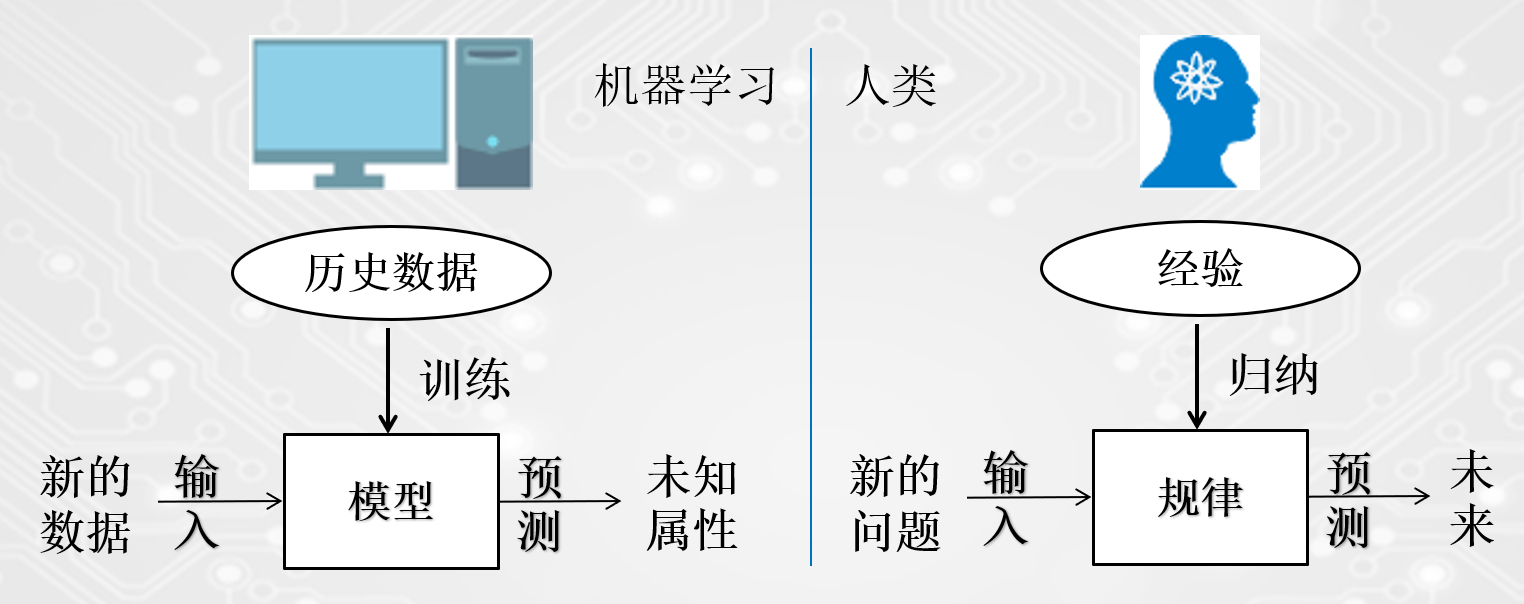
机器学习中的“训练”与“预测”过程可以可以对应到人类的“归纳”与“预测”过程。通过这样的对应,我们可以发现机器学习是对人类在生活中学习成长的一个模拟。
基本上,机器学习是人工智能的一个子集,深度学习则是机器学习的一个分支。
人工智能是目标 机器学习是手段 深度学习是方法
如果把三者的关系用图来表明的话,则是下图:

人工智能> 机器学习> 深度学习
2应用场景
(1)数据分析与挖掘
数据分析与挖掘技术是机器学习算法和数据存取技术的结合,利用机器学习提供的统计分析、知识发现等手段分析海量数据,同时利用数据存取机制实现数据的高效读写。
(2)计算机视觉
计算机视觉的主要基础是图像处理和机器学习。图像处理技术用于将图像处理为适合进入机器学习模型的输入,机器学习则负责从图像中识别出相关的模式。
手写字识别、车牌识别、人脸识别、目标检测与追踪、图像滤波与增强等都是计算机视觉的应用场景。
(3)自然语言处理
自然语言处理是让机器理解人类语言的一门技术。垃圾邮件过滤、用户评论情感分类、信息检索等都是自然语言的应用场景。
(4)语音识别
语音识别是利用自然语言处理、机器学习等相关技术实现对人类语言识别的技术。Siri等智能助手、智能聊天机器人都是语音识别的应用。

3流程
1.问题定义
对现实问题进行分析,确定好问题的类型,这将直接影响算法的选择、模型评估标准。
2.数据准备
(1)数据收集
根据问题的需要,下载、爬取相应的数据。
(2)数据预处理
数据集或多或少都会存在数据缺失、分布不均衡、存在异常数据、混有无关紧要的数据等诸多数据不规范的问题,这就需要我们对收集到的数据进行进一步的处理,叫做“数据预处理”。
(3)数据集分割
一般需要将样本分成独立的两部分:训练集(train set)和测试集(test set)。其中训练集用来训练模型,测试集用来检验训练好的模型的准确率。
3.模型选择和开发
根据确定的问题类型,选择合适的模型,编写代码实现模型。
4分类
按学习目标的不同,机器学习可分为:
-
监督学习(SupervisedLearning)
-
无监督学习(UnsupervisedLearning)
-
强化学习(ReinforcementLearning, RL)
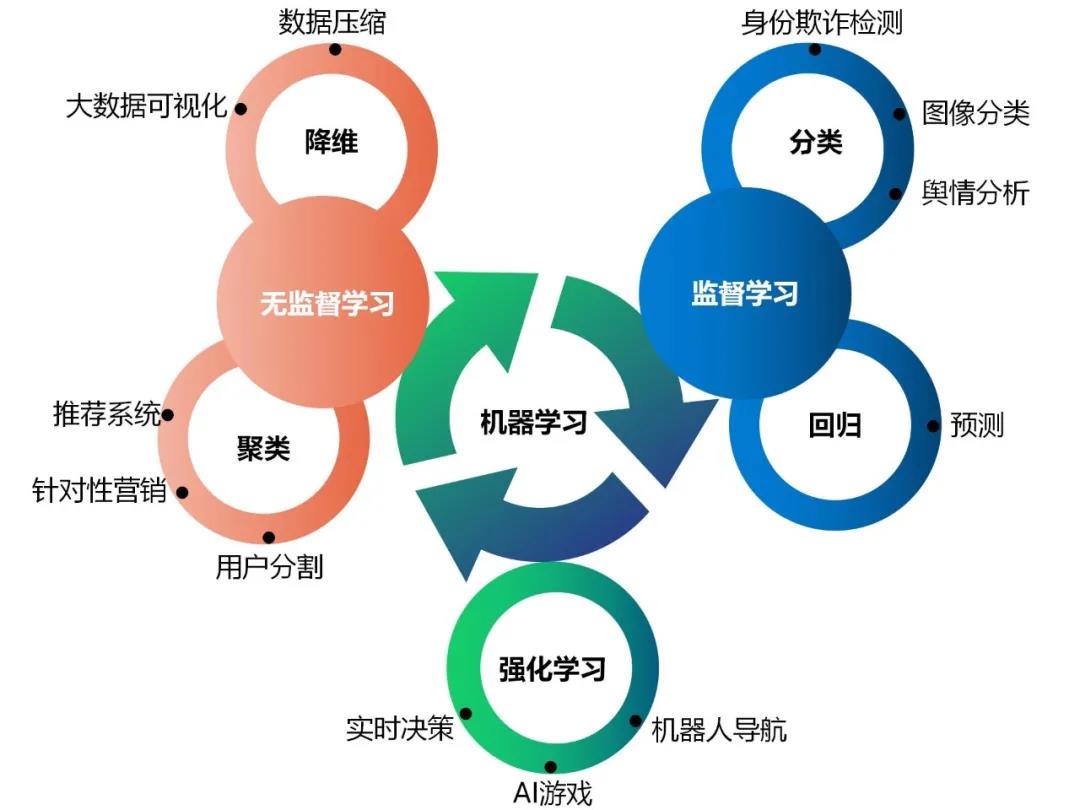
根据训练数据是否有标注,机器学习可划分为:
监督学习和无监督学习
1.监督学习
监督式学习需要使用有输入和预期输出标记的数据集。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。
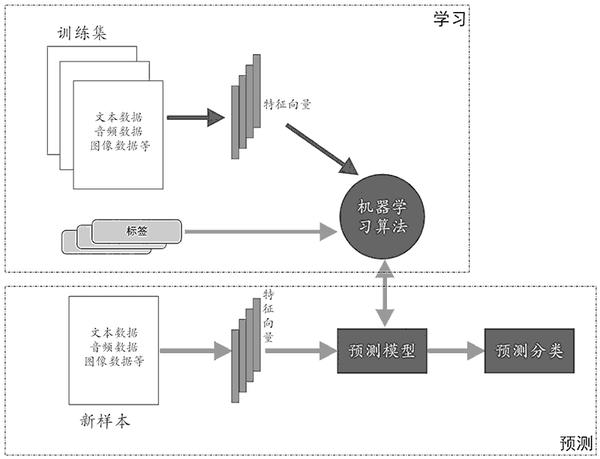
监督学习又可分为“分类”和“回归”问题。
(1)分类问题
在分类问题中,机器学习的目标是对样本的类标签进行预测,判断样本属于哪一个分类,结果是离散的数值。
例如:将图片分类为“苹果”或“橘子”,准确识别新图片上的水果是“苹果”类还是“橘子”类就是分类问题。
(2)回归问题
在回归问题中,其目标是预测一个连续的数值或者是范围。
比如:预测一套二手房的售价,给定房价的数据集,每套房子大小等特征数据对应的标签就是房价,如果你有一套房子想知道能卖多少钱,机器学习算法就根据输入的房子大小数据,预测出房子对应的市场价。
2.无监督学习
在无监督学习中给定的数据没有标签。无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构,这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。
聚类是典型的无监督学习,事先不知道样本的类别,通过某种办法,把相似的样本放在一起归位一类。

例如,餐馆拥有大量顾客的消费数据,想对顾客进行分组,以提供针对性优质服务。一开始不大可能告诉聚类算法每个顾客属于哪个分组,算法会自行寻找这种关联,把用餐的次数和用餐总花费较高的优质顾客分为一组,把用餐的次数和用餐总花费较低的普通顾客分为一组,把一次性顺便消费的低价值顾客分为一组。
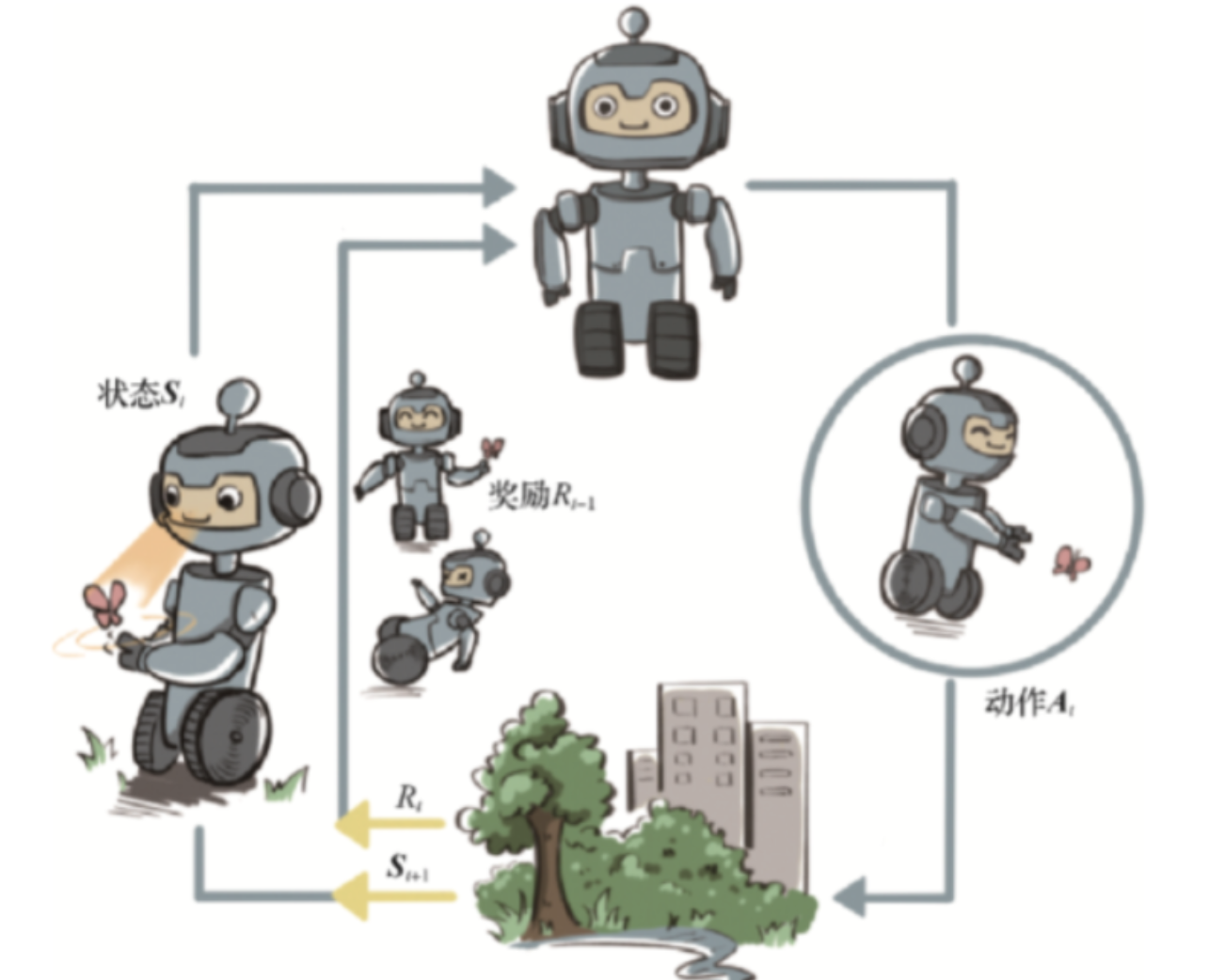
3.强化学习
定义:机器通过与环境进行交互,不断尝试,让机器从错误中学习,做出正确决策从而实现目标的方法。
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器,交互是迭代进行
5泛化和拟合
模型的泛化
在监督学习中,我们会在训练集上建立一个模型,之后会把这个模型用于新的数据中,这个过程称为模型的泛化(generalization)。
我们总是希望模型对于新数据的预测能够尽可能准确,这样才能说模型的泛化能力好,预测的误差小,是一个好模型。
我们使用什么样的标准来判断一个模型的泛化能力是好还是差呢?
我们可以使用测试数据集对模型的表现进行评估,以判定该模型的优劣。
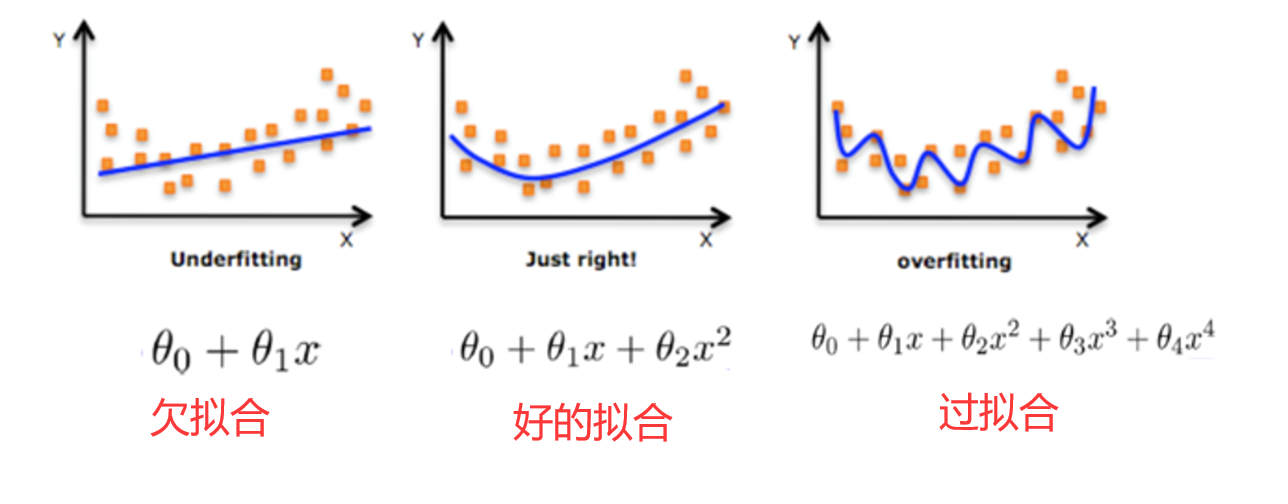
1.过拟合
过拟合是指机器学习模型在训练集中表现优秀,而在测试集中表现不佳。
出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少,可能包含了很多不必要的参数或结构,降低过拟合的方法:
(1)增加训练数据
(2)降低模型复杂度
(3)正则化
2.欠拟合
欠拟合时,机器学习模型又过于简单,学习器没有很好地学到训练样本的一般性质,所以在训练集和测试集中表现都很差。
这通常是因为模型的复杂度太低,或者训练过程没有足够的时间或资源来找到好的参数。
降低欠拟合的方法:
(1)添加新特征
(2)增加模型复杂度
(3)延长训练时间,调整学习率
例如:

最优的模型应该是过拟合和欠拟合的折中,它既较好拟合了训练集,又具有很好的泛化能力,在测试数据集上也有很好的表现。
6必须库
1.Numpy——基础科学计算库

Numpy是一个Python中非常基础的用于科学计算的库,它的功能包括高维数组(array)计算、线性代数计算、傅里叶变换以及生产伪随机数等
打开命令行输入pip install numpy进行安装
2.Pandas——数据分析的利器

Pandas是一个Python中用于进行数据分析的库,它可以生成类似Excel表格式的数据表,而且可以对数据表进行修改操作。它还可以从很多不同种类的数据库中提取数据,如SQL数据库、Excel或者CSV文件。
打开命令行输入pip install pandas进行安装
3.matplotlib——数据可视化
matplotlib是一个Python的绘图库,它能够绘制折线图、散点图、直方图等,其强悍的绘图能力能够帮我们对数据形成非常直观的认知。

打开命令行输入pip install matplotlib进行安装
4.scikit-learn——Python机器学习库
scikit-learn包含众多顶级机器学习算法,主要有六大类的基本功能:分类、回归、聚类、数据降维、模型选择和数据预处理。
打开命令行输入pip install scikit-learn进行安装

















 3037
3037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









