






文章Shimin C ,Qin J .Persistent B+-trees in non-volatile main memory[J].Proceedings of the VLDB Endowment,2015,8(7):786-797.
本文为记录学习使用,如有错误,烦请指正。
本次文章内容主要围绕原文第四章内容
引言
在现代数据库系统中,B+-树是一种被广泛应用的数据结构。然而,随着非易失性内存(NVMM)的发展,传统的 B+-树设计在 NVMM 上面临性能瓶颈。具体而言,更新操作(如插入和删除)通常需要移动大量的索引条目,并且依赖于昂贵的日志(Undo-Redo Logging)或影子拷贝(Shadowing)来保障数据一致性。这些操作大幅增加了 NVMM 的写入次数,降低了系统性能,并对 NVMM 的耐久性产生不良影响。
为了解决这些问题,本文首次提出并重点介绍了wB+-Trees。通过优化数据结构和更新机制,wB+-Trees 显著减少了写入开销,同时保持了良好的查找性能和一致性保障。
由原文的前三章,可以知道用传统日志和影子拷贝保障数据结构一致性在NVMM上会对系统性能产生很大的开销。
因此本文提出的方法主要希望解决或者说优化的问题实际上就在于如何提出一种更好的兼顾保障数据一致性和系统性能的方法用于数据在NVMM的读写。
wB+-Trees 的设计目标
更新效率:
减少 NVMM 上的写入次数和缓存刷新操作。
通过间接槽数组和位图避免索引条目的大规模移动。
搜索性能:
保持非叶节点的排序结构,支持快速的二分查找。
在叶节点中灵活使用非排序存储,以提升更新效率。
一致性保障:
通过原子写操作实现数据一致性,无需依赖传统的日志或影子拷贝。
实际就是兼顾保障数据一致性和系统性能
核心结构设计
为了减少写入和移动开销,采用了带位图的无序节点。
间接槽数组和位图
为了实现以上的设计目标,本文引入了两种关键数据结构:间接槽数组和位图。
间接槽数组用于减少查询开销,位图用于减少增删开销。
是什么?
1.Slot Array(间接槽数组)
槽数组是一个记录数据条目逻辑顺序的数组,其中每个槽(slot)存储一个索引或指向实际数据条目的偏移量。
如下图所示是一个使用一个字节大小的槽的节点。(重点体现槽数组)
*Slot0标记了条目的总数:如下图Slot array中的 5 指的就是节点中一共包含 5 个条目。
*节点中数据条目: [9 2 3 1 7]
对应的偏移为: [0 2 3 5 6]
把上述数据条目按逻辑顺序
从小到大排序: [1 2 3 7 9]
对应原来的偏移为: [5 2 3 6 0]
槽数组记录的就是条目总数 5(Slot0)加上这个偏移[5 2 3 6 0],或者说索引。
最终得到的槽数组为[5 5 2 3 6 0]
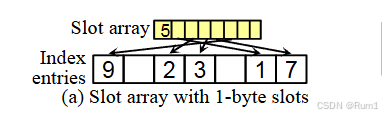
于是,如果要查找键值7,过程如下:
1.二分查找[5 2 3 6 0],找到3。
2.偏移3对应到节点中得到对应的键值3,由于3小于7,所以mid=low+1
3.然后继续再槽数组[5 2 3 6 0]中向右二分查找,找到6。
4.偏移6对应在节点中的键值为7与要查找的键值一致,返回。
由此实现了无序节点的二分查找,提高了查询的性能
2.Bitmap(位图)
位图是一个由二进制位(0 和 1)组成的数组,每一位对应节点中的一个存储位置。
1 表示该位置存储了有效数据条目,0 表示该位置空闲。
下图是一个只使用了位图(没有使用slot array)的叶节点。
bmp就是存储位图的区域。
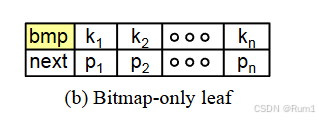
假定我们有一个节点,存储数据条目如下:
[k1, -, k2, -, k3, -, -, k4]
存储位置为: [0, 1, 2, 3, 4, 5, 6, 7]
则其对应的位图如下:
[1, 0, 1, 0, 1, 0, 0, 1]
于是,如果我们想要插入新的数据条目 k5=25,过程如下:
1.通过位图查找空闲位置:那么我们只要查找到位图中第一个值为 0 的位置,结果位置为1,
2.将新条目存储到空闲位置:在节点物理偏移为1的位置插入k5
3.更新位图:将对应的位图位置从0更新为1.
相应的,删除操作与上面所描述的插入操作十分类似,就不再赘述。
由于使用了位图,插入/删除 时就不需要移动节点中的其他条目,减少了NVMM的写入操作,从而减少了写入和刷新的开销。
作用?优势?
1.Slot Array(间接槽数组)
作用:
高效查找:通过槽数组提供逻辑顺序,实现二分查找,提升查询性能。
减少数据移动:插入和删除操作仅需更新槽数组,不移动实际数据条目,减少 NVMM 的写入开销。
优势:
插入和删除操作只需更新槽数组,无需移动实际数据。
显著减少了写入和缓存刷新操作的开销。
2.Bitmap(位图)
作用:
插入优化:通过位图快速找到空闲位置存储新数据,无需移动其他条目。
删除优化:删除操作仅需更新位图,无需物理删除数据条目。
一致性保障:位图可以记录节点的状态(如插入或删除是否完成)。
优势:
避免了索引条目的排序需求,进一步减少写入开销。
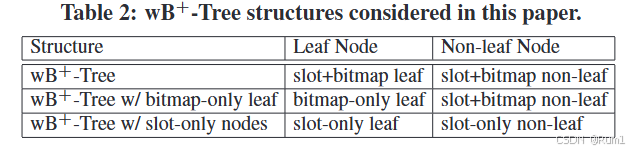
利用这两种数据结构,根据应用场景,wB+-Trees 提供了如上图所示的三种结构:
wB+-Tree:
综合场景需求:查询、插入和删除操作均较频繁的场景。
wB+-Tree with Bitmap-only Leaf:
适用于写入密集型场景,即插入和删除操作频繁,更新性能优先于查找性能的场景
wB+-Tree with Slot-only Nodes:
适用于读密集型场景,即查询操作频繁,且插入和删除操作较少的场景。
这种对于场景上的灵活性让 wB+-Trees 能够在搜索性能和更新效率之间取得平衡。
文章到此,所提出的方法已经基本上阐述完毕了。接下来的内容都是关于实验测试的内容,在第五章,文章通过实验,验证了 wB+-Tree 的性能提升,强调了其显著的查找、插入和删除优化效果,展现了其在实际应用中的可用性。随后在第六章总结了研究贡献,明确 wB+-Tree 的优越性,提出了未来研究方向,包括并发优化、动态节点调整和适配其他数据结构的可能性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









