






 论文提出了一种基于WiFi CSI的姿势估计方法——CSI-Former,利用5GHz WiFi的抗干扰性构建了Wi-Pose数据集。通过Performer和卷积神经网络,从CSI中学习姿态信息,提高了姿态估计的准确性。实验结果显示,与ResNet相比,CSI-Former的性能提升了2.7%的平均PCK。
论文提出了一种基于WiFi CSI的姿势估计方法——CSI-Former,利用5GHz WiFi的抗干扰性构建了Wi-Pose数据集。通过Performer和卷积神经网络,从CSI中学习姿态信息,提高了姿态估计的准确性。实验结果显示,与ResNet相比,CSI-Former的性能提升了2.7%的平均PCK。
论文概述
本文提出了一种新的基于WiFi的姿态估计方法。基于WiFi的信道状态信息(CSI),提出了一种新的结构 CSI-former。为了评估CSI-former的性能,本文建立了一个新的数据集Wi-Pose。该数据集由5GHz WiFi CSI、相应的图像的骨架点注释组成。
背景
Transformer由于其强大的多头注意力,在各种自然语言处理和计算机视觉任务中表现出强大的性能。根据Transformer的注意力机制,提出了一种新的Performer来实现基于注意力的长序列数据分析。Performer具有良好的注意力机制和更好的空间利用率,能从长序列CSI中提取更多隐藏的姿态特征。 与2.4GHz相比,5GHz信号具有较强的抗干扰性和较少的干扰源。
因此,本文认为5GHz WiFi更适合于WiFi姿态估计网络,然后收集志愿者活动的图像和CSI,构建了一个基于WiFi的姿态估计数据集,名为Wi-Pose(https://github.com/NjtechCVLab/Wi-PoseDataset)可以去GitHub下载
下载完之后的:

网络模型
CSI-former通过师生网络实现基于WiFi的姿态估计: 教师网络通过Alphapose估计视频中的人体姿态,学生网络通过Performer和卷积神经网络从CSI中学习人体姿态。 Alphabpose在许多公共数据集上表现出了优异的性能,实现了高性能的基于图像的姿态估计。可以从人类图像中识别18个骨骼关键点(鼻子、脖子、肩膀、肘部、手腕、臀部、膝盖、脚踝、眼睛、耳朵)。 通过教师网络的Alphapose对捕捉到的图像进行处理,生成人体姿势的注释信息,并进行监督。
CSI去噪
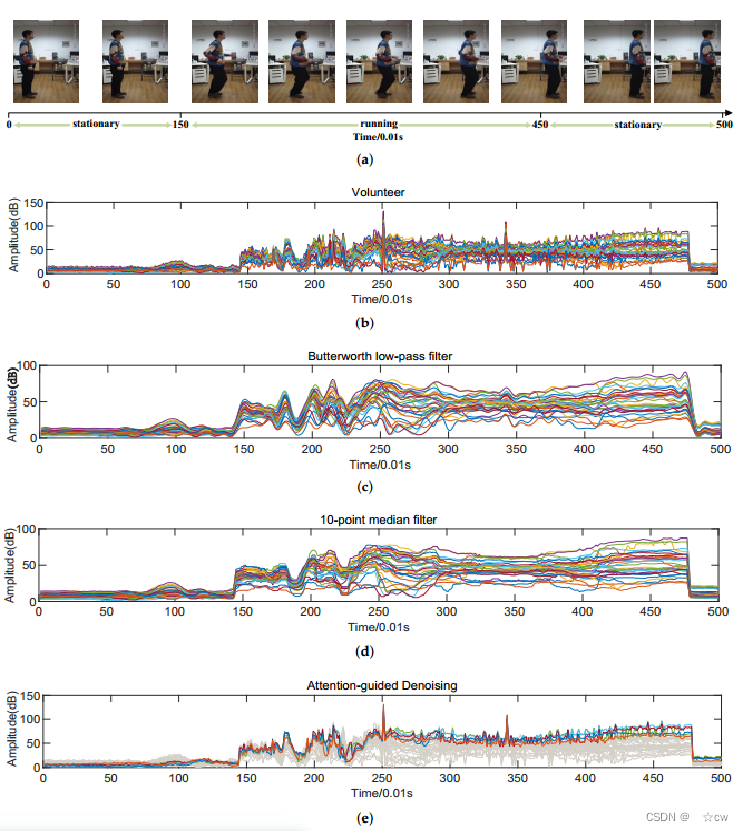
(a) 志愿者从静止到奔跑再到静止的图像。 (b) 在时间戳中记录(a)的对应CSI。 (c)巴特沃斯低通滤波器滤波之后的CSI。 (d)中值滤波器滤波之后的CSI。 (e)基于CSI-former的注意力引导去噪方法
(c)(d)的振幅变化不明显,表明CSI的隐藏姿态特征也被过滤掉了。(e)通过有效的注意力分配来稀释噪声。突出显示的部分是具有更丰富特征的子载波。灰色部分是不太关注的子载波。
简单地返回18个骨架点很容易过度拟合并失去泛化能力。因此,有必要添加骨架点邻接矩阵(SAM)作为正则项。SAM是一个3×18×18的矩阵,由3个子矩阵x′、y′和c′组成。每个子矩阵都是18×18的。
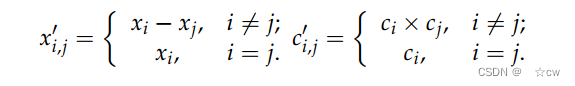
网络结构:
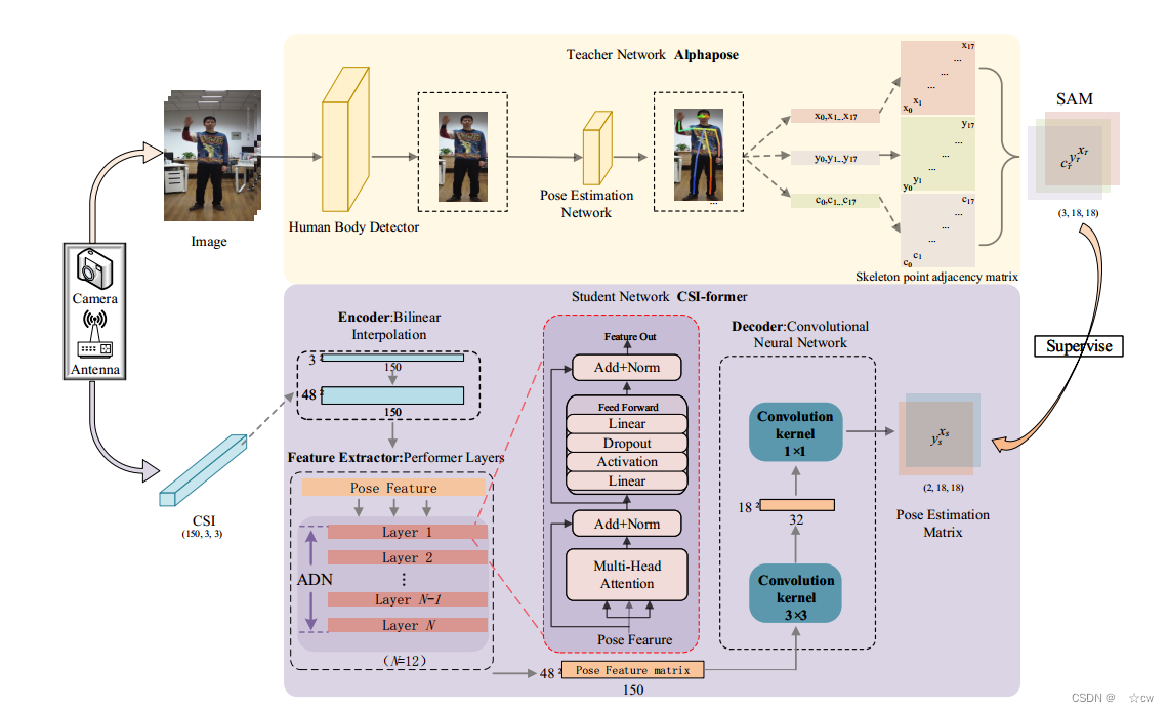
编码器:放大原始数据的特征以便于提取。 基于注意力的特征提取器:传统的特征提取器由卷积神经网络或纯ResNet组成。然而,这些架构总是对所有输入数据执行相同的分析,而不是更多地关注更有用的信息,这限制了网络的性能。本文使用基于多层复合注意力的12层的Performer作为特征提取器。 解码器:使用具有两层架构的卷积神经网络作为解码器。
损失函数:置信度表明其与真实姿态的相关性,因此要将其考虑在内。
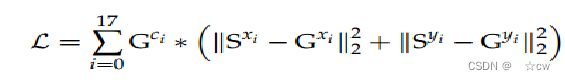
实验部分
Wi-Pose包括12个动作,总共166600个数据,每个动作的数据量大致相等。 Wi-Pose最终由筛选后剩余的清晰图像、其对应的CSI和骨架点注释组成。
正确关键点百分比(PCK)被用于评估所提出方法的性能:
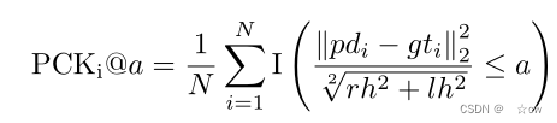
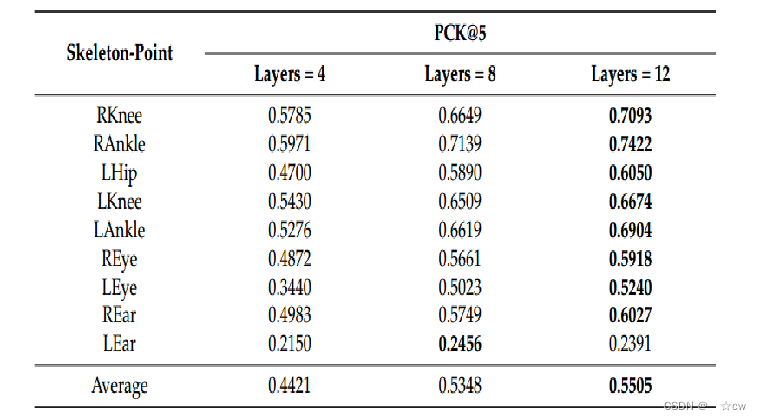
CSI-former中不同Perormer层数之间的比较
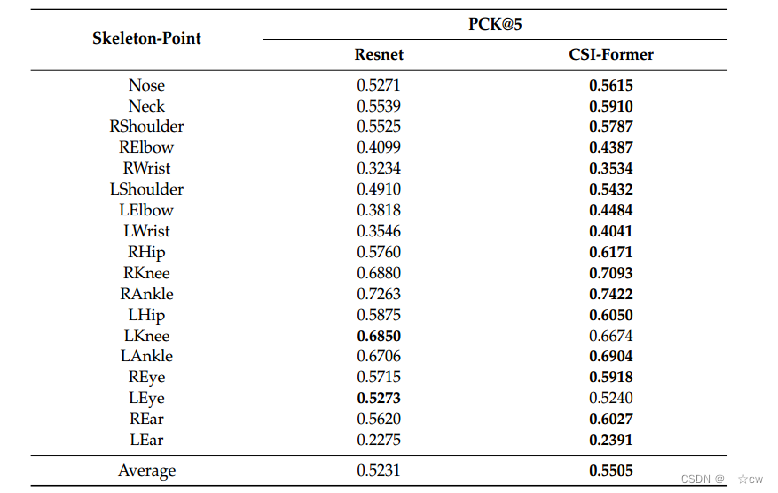
记录了pck@5分别由CSI-former和Resnet估计的测试集中的12个骨架点。
CSI-former比Resnet实现了更优越的性能,并且平均PCK增加2.7%。
结果展示

文章总结
本文通过12层具有多头注意力机制的Performer来设计CSI-former的架构,使网络更加关注包含更多姿势特征的信息。实验结果表明CSI-former比现有的基于Resnet的方法具有更好的姿态估计性能。同时建立了一个新的基于WiFi的人体姿态估计数据集Wi-pose,并发表了Wi-pose以促进未来的研究。
导入数据的代码
def load_data(folder_path):
data = []
label = []
# 遍历文件夹,得到所有mat文件
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
if file.endswith('.mat'):
with h5py.File(file_path, 'r') as mat_file:
dataset_name = 'CSI'
label_name = 'SkeletonPoints'
if dataset_name in mat_file:
data.append(mat_file[dataset_name][:])
if label_name in mat_file:
label.append(mat_file[label_name][:])
return data, label
# 加载训练数据
train_folder = 'data/Train'
train_data, train_label = load_data(train_folder)
train_data_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
train_label_loader = DataLoader(dataset=train_label, batch_size=batch_size, shuffle=True)然后引入模型进行训练。



















 3290
3290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











