






目录
2. 数据读取,检查数据的特征,查看有无缺失值,重复值,异常值
项目工具介绍
演示工具:Python3.8, Windows11,Anaconda,Jupyter notebook
Requirements:scikit-learn,pandas
演示数据集:Kaggle开源Titanic数据集,下载地址Titanic
前置操作
Python安装及配置
前往官网Python.org下载,推荐版本为3.6 - 3.10,对某些库兼容性更好一些,例如TensorFlow
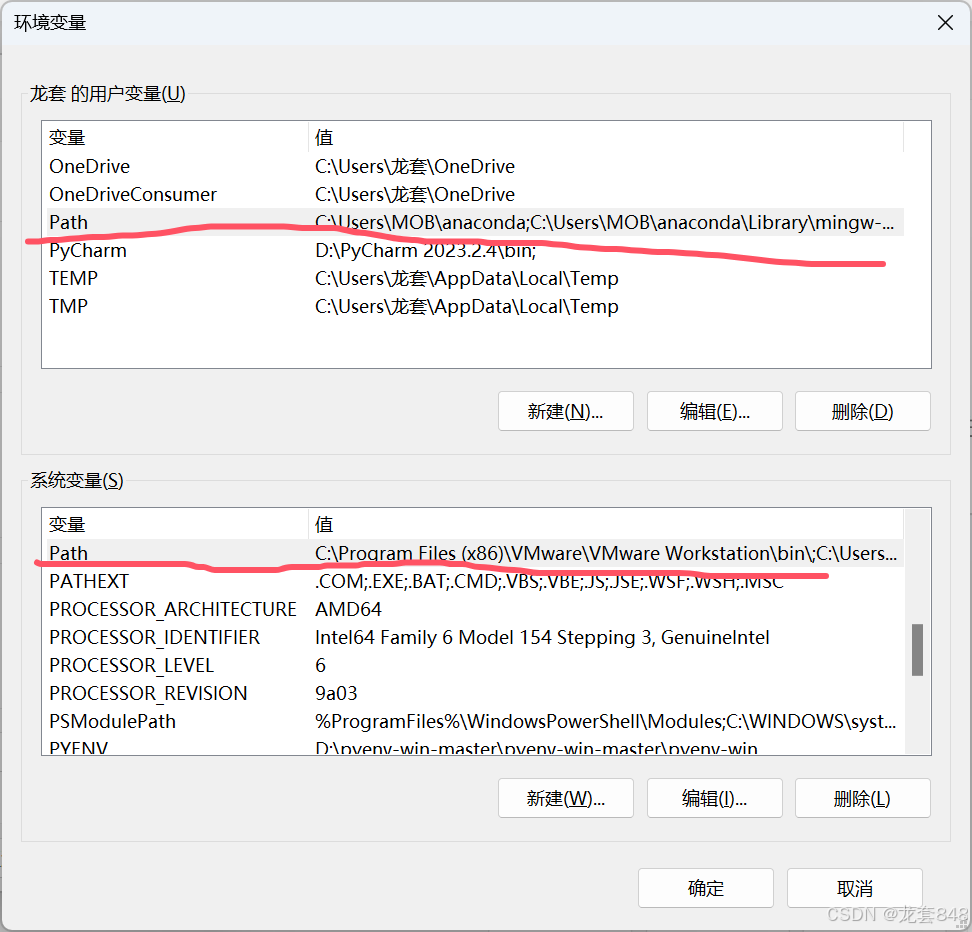
安装完进行添加Python环境变量,以便今后可以在cmd中直接使用Python。以win11系统为例,右击“此电脑”,点击属性,在设置中点击高级系统设置--->高级--->环境变量--->Path,在Path里新建两个变量,两个path里都添加:
第一个添加Python文件中的scripts文件夹,默认Python安装路径在C:\Users\此处是你电脑的用户名\AppData\Local\Programs\Python\你的Python版本\Scripts\
第二个添加Python主文件夹,即C:\Users\此处是你电脑的用户名\AppData\Local\Programs\Python\你的Python版本\
添加所需要的库函数
在进行建模之前,我们要先将建模时用到的库函数下载进来,以便后续直接调用。首先同时按住键盘上的win键和R键,输入cmd按回车进入到命令行。在命令行中输入以下命令进行下载,使用清华镜像源来加速下载。
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simplepip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple此处若报错,大概率是上一步Python环境变量没配置好,建议仔细检查!
机器学习建模
建模流程
一套完整的建模的具体流程大概分为10步:数据读取,数据预处理,建立标签,划分数据集,特征工程,模型实例化,模型预测,模型评估,模型调优,模型解释。
此演示中,特征工程、模型调优与模型解释部分不做演示,后续会更新相关文章进行补充。
实战代码讲解
1. 导入库函数
import pandas as pd # 数据读取
from sklearn.preprocessing import StandardScaler # 用于标准化数据
from sklearn.model_selection import train_test_split # 用于划分数据集
from sklearn.svm import SVC # 使用支持向量机进行建模预测
from sklearn.metrics import (accuracy_score, recall_score, precision_score,
f1_score, confusion_matrix) # 模型评价指标
import warnings
warnings.filterwarnings('ignore')2. 数据读取,检查数据的特征,查看有无缺失值,重复值,异常值
df = pd.read_csv('单引号里替换为数据集的路径', encoding='utf-8')
print(df.head(5))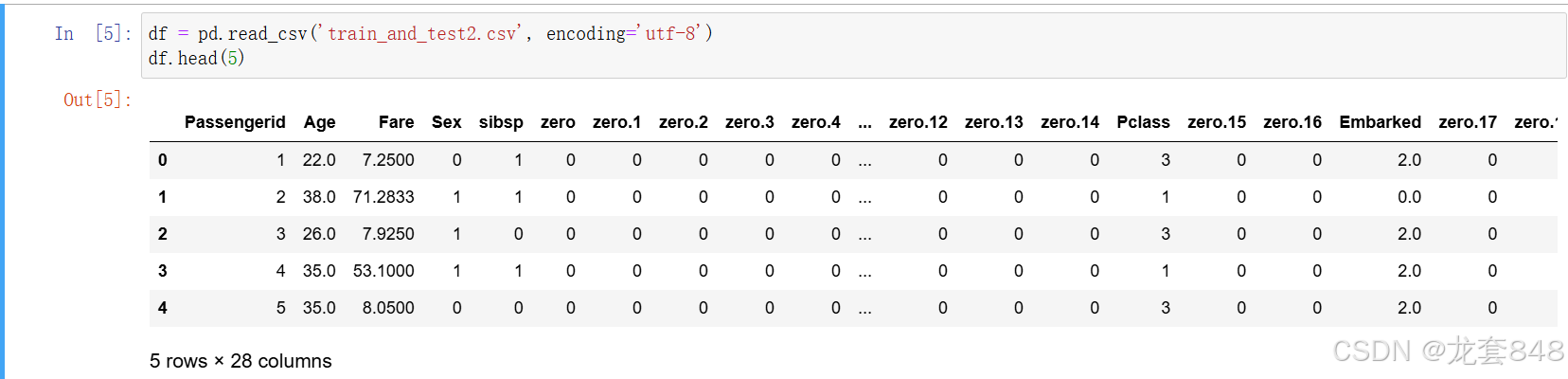
通过输出数据集的前五行可以看出该数据集一共有28列数据,特征有乘客id,年龄,费用,性别,以及一堆zero列。这些zero列就是异常值。
接着检查数据集是否存在重复值与缺失值,通过输出后可看出,仅Embarked列含两个缺失值。
duplicates = df.duplicated().sum() # 检查是否存在重复值
missing_value = df.isna().sum() # 检查是否存在缺失值
print(f'重复值数量为:{duplicates}\n')
print(f'缺失值数量为:\n{missing_value}')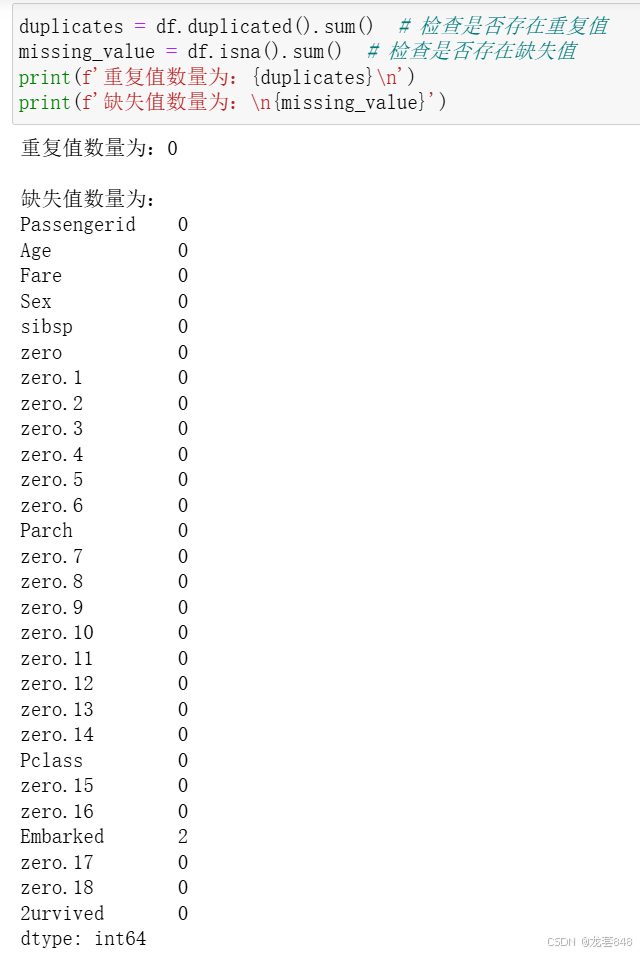
3. 数据预处理,删除无用列,处理缺失值
由第二步我们得知zero列是无用列,需要将其删去,使用DataFrame类型的drop方法执行删除操作,参数解释['zero']表示要删除的索引,inplace=True即直接在df表格中进行操作,axis=1表示按纵轴方向索引。
for i in range(0, 19):
if i == 0:
df.drop(['zero'], inplace=True, axis=1)
else:
df.drop([f'zero.{i}'], inplace=True, axis=1)
print(df.columns)
接下来处理Embarked列的缺失值,我们此处采用 'ffill' 方法,即缺少的值将由同一列中上一行的值进行填充。
df['Embarked'].fillna(method='ffill', inplace=True)
embarked_missing = df['Embarked'].isna().sum()
print(f'Embarked列的缺失值数量为:{embarked_missing}')![]()
4. 建立标签
标签的确定是根据不同的任务来选择的,特征变量(自变量)作为作为我们的输入特征X,预测变量(因变量)作为我们的标签y。此处我们的输入特征为Age, Fare, Sex, sibsp, Parch, Pclass, Embarked, 预测变量为 2urvived。
X = df.drop(['Passengerid', '2urvived'], axis=1)
y = df['2urvived']
print(X.shape)处理后X的大小为(1309, 7),表示我们有1309个样本,7个特征变量。
5. 划分数据集
我们通常将数据集按照8:2或者7:3的比例划分为训练集与测试集,或者按照6:2:2或7:2:1的比例划分为训练集、验证集与测试集。此处我们按照7:3的比例划分数据集,通过设置随机种子的值来实现模型性能的可复现。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print(f'训练集的数量为:{y_train.shape}')
print(f'测试集的数量为:{y_test.shape}')划分后训练集含916个样本,测试集样本数量为393例。
6. 数据标准化
为了减小各特征数值大小分布范围不同,造成模型偏向某些特征的情况,我们可以通过对特征变量进行标准化,将每一种特征的分布都变为0-1之间,从而获得更好的模型性能。
std = StandardScaler()
X_train = std.fit_transform(X_train)
X_test = std.transform(X_test)7. 模型实例化
经过上面这么多操作之后,现在我们可以开始构建模型了,模型的构建十分简单,先实例化模型,并设置模型的超参数,接下来就可以进行训练了。
svm = SVC(C=1, gamma=0.1, kernel='rbf')
svm.fit(X_train, y_train)8. 模型预测
y_pred = svm.predict(X_test)
print(y_pred)9. 模型评估
混淆矩阵是评估分类模型的性能的最常用指标,其表示分类任务中模型预测结果与真实标签之间的关系。混淆矩阵的格式为:
TN表示真实标签为负类且预测为负类的样本数;
FP表示真实标签为负类但预测为正类的样本数;
FN表示真实标签为正类但预测为负类的样本数;
TP表示真实标签为正类且预测为正类的样本数。
模型评价的常用指标为准确率(Accuracy),召回率(Recall),精确度(Precision)和f1分数。
准确率是分类正确的样本占总样本的比例,计算如下:
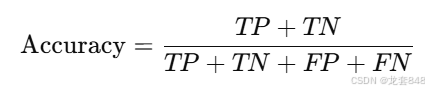
召回率是实际为正类的样本中,被正确预测为正类的比例,计算如下:
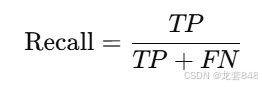
精确度是预测为正类的样本中,真实为正类的比例,计算如下:
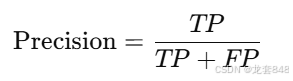
F1 分数是精确率和召回率的调和平均,反映recall和precision的综合性能,计算如下:
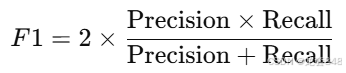
代码实现如下:
# 混淆矩阵计算
confusion = confusion_matrix(y_test, y_pred)
print(confusion)
# 指标计算
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'accuracy={accuracy}, recall={recall},precision={precision}, f1={f1}')小结
对初学机器学习的萌新,千万不要硬啃模型处理的具体算法,只用掌握模型的应用方法和各模型的超参数设置,学会应用即可。想入门机器学习的话,其相关的库函数的使用方法也很重要,例如pandas,numpy和matplotlib,pandas用于进行数据集操作,numpy用于进行矩阵转换和运算,matplotlib用于可视化模型性能,制作出各种漂亮好看的图。
本文进行的是二分类任务,关于回归和多分类任务的讲解,如果反响的人多的话笔者会考虑再写一篇补充。
机器学习实战项目也可以到Kaggle网站上,下载数据集进行自己建模分析,想要学好的话一定要多动手实操,干看理论知识的话不推荐哦~
完整代码
# coding=utf-8
import pandas as pd # 数据读取
from sklearn.preprocessing import StandardScaler # 用于标准化数据
from sklearn.model_selection import train_test_split # 用于划分数据集
from sklearn.svm import SVC # 使用支持向量机进行建模预测
from sklearn.metrics import (accuracy_score, recall_score, precision_score,
f1_score, confusion_matrix) # 模型评价指标
import warnings
warnings.filterwarnings('ignore')
# 读取数据集
df = pd.read_csv('train_and_test2.csv', encoding='utf-8')
# print(df.head(5))
# 查询缺失值、重复值、异常值
duplicates = df.duplicated().sum() # 检查是否存在重复值
missing_value = df.isna().sum() # 检查是否存在缺失值
# print(f'重复值数量为:{duplicates}\n')
# print(f'缺失值数量为:\n{missing_value}')
# 删除zero列
for i in range(0, 19):
if i == 0:
df.drop(['zero'], inplace=True, axis=1)
else:
df.drop([f'zero.{i}'], inplace=True, axis=1)
# print(df.columns)
# 对缺失值进行向前填充
df['Embarked'].fillna(method='ffill', inplace=True)
embarked_missing = df['Embarked'].isna().sum()
# print(f'Embarked列的缺失值数量为:{embarked_missing}')
# 建立标签
X = df.drop(['Passengerid', '2urvived'], axis=1)
y = df['2urvived']
# print(X.shape)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# print(f'训练集的数量为:{y_train.shape}')
# print(f'测试集的数量为:{y_test.shape}')
# 数据标准化
std = StandardScaler()
X_train = std.fit_transform(X_train)
X_test = std.transform(X_test)
# 实例化SVM
svm = SVC(C=1, gamma=0.1, kernel='rbf')
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test) # 模型预测
# 计算混淆矩阵
confusion = confusion_matrix(y_test, y_pred)
print(confusion)
# 计算模型评价指标
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'accuracy={accuracy}, recall={recall},precision={precision}, f1={f1}')
有任何问题,欢迎评论区留言讨论~

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









