







什么是聚类?
聚类(Clustering)是一种无监督的机器学习方法,用于将一组数据按照一定的相似性划分为多个组或类,使得同一组中的数据更为相似,而不同组之间的差异较大。聚类的主要目标是找到数据中的自然分组和模式,而不需要事先给出标签或类别。
聚类的关键概念
-
无监督学习:聚类不需要预先提供标签数据,算法会根据数据本身的特征来决定如何划分。
-
相似性度量:聚类算法依赖于一定的相似性度量(如欧氏距离、曼哈顿距离等)来判断数据点之间的关系和相似程度。
-
簇(Cluster):聚类的结果是多个簇,每个簇包含一组彼此相似的数据点。
常见的聚类算法
- K-means 聚类:将数据划分为 kkk 个簇,通过迭代优化簇内的相似性,直到收敛。
- 层次聚类(Hierarchical Clustering):通过递归地合并或分裂簇来生成层次结构的聚类结果。
- DBSCAN(基于密度的聚类):通过寻找密度较高的区域进行聚类,能够识别任意形状的簇。
- 谱聚类(Spectral Clustering):利用图论和谱分解技术进行聚类,适合复杂形状的数据。
聚类的应用
- 图像处理:图像分割和颜色量化
- 文本分析:文本聚类、主题建模
- 市场营销:客户分群
- 生物信息学:基因或蛋白质的分群
举例说明
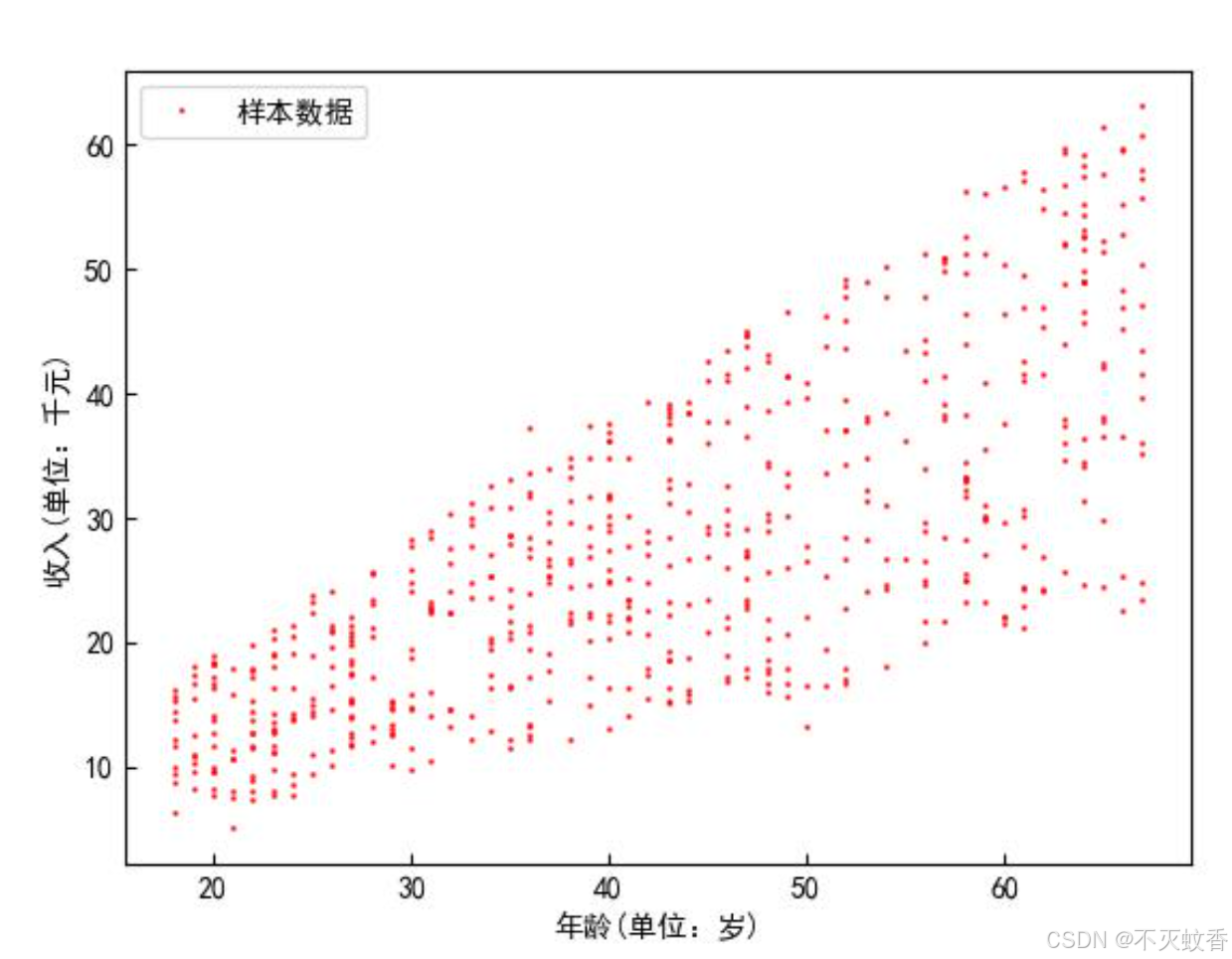
这里有一张关于年龄和收入之间关系的散点图,现在要将这个散点图分为三类。
step1:随机初始簇中心位置
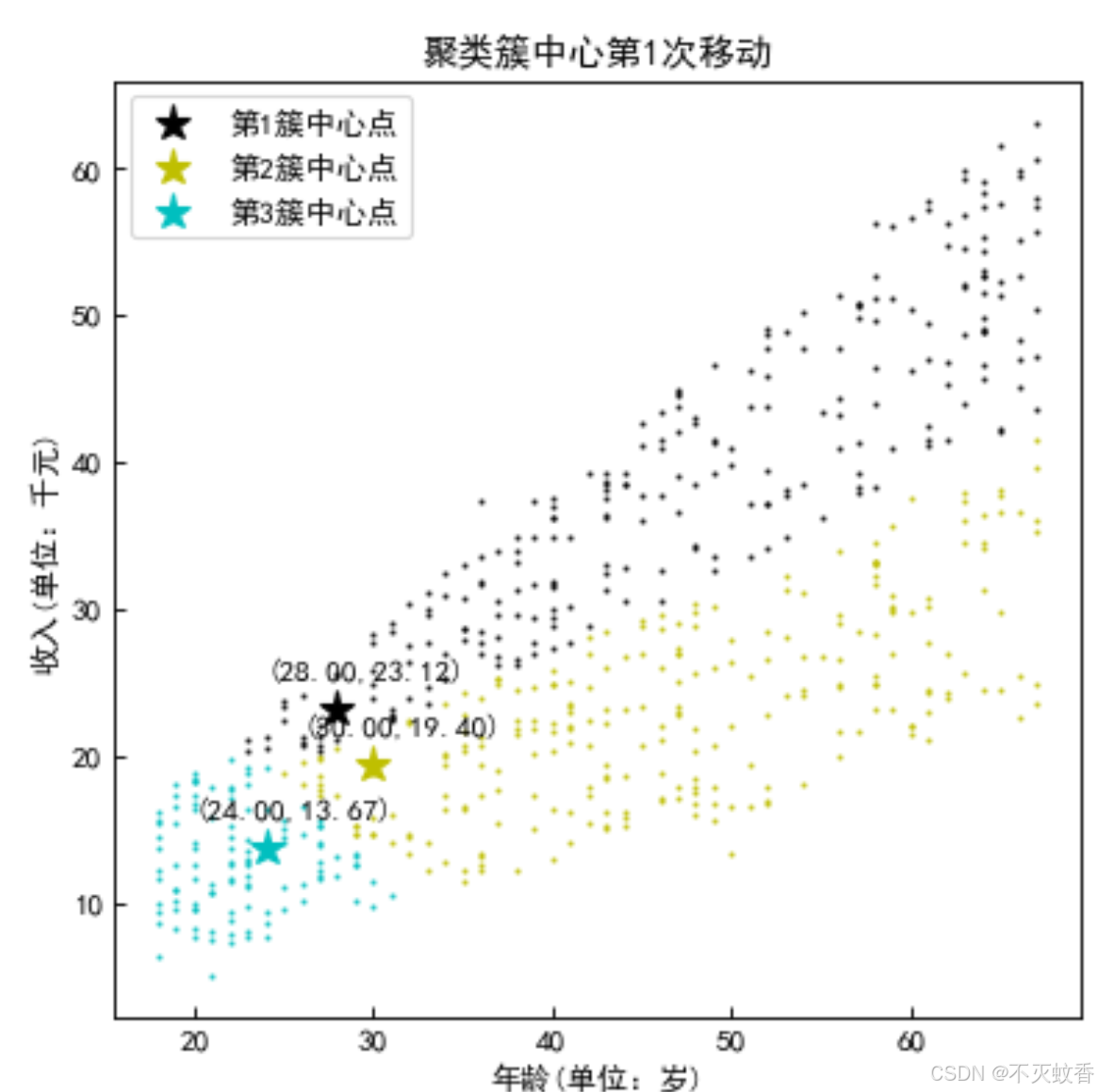
step2:将所有的数据与簇中心计算距离,将离得近的数据加入簇群中
也就是上图中把不同的点分成三种颜色。
step3:计算簇群中的平均值,获得新的簇中心点
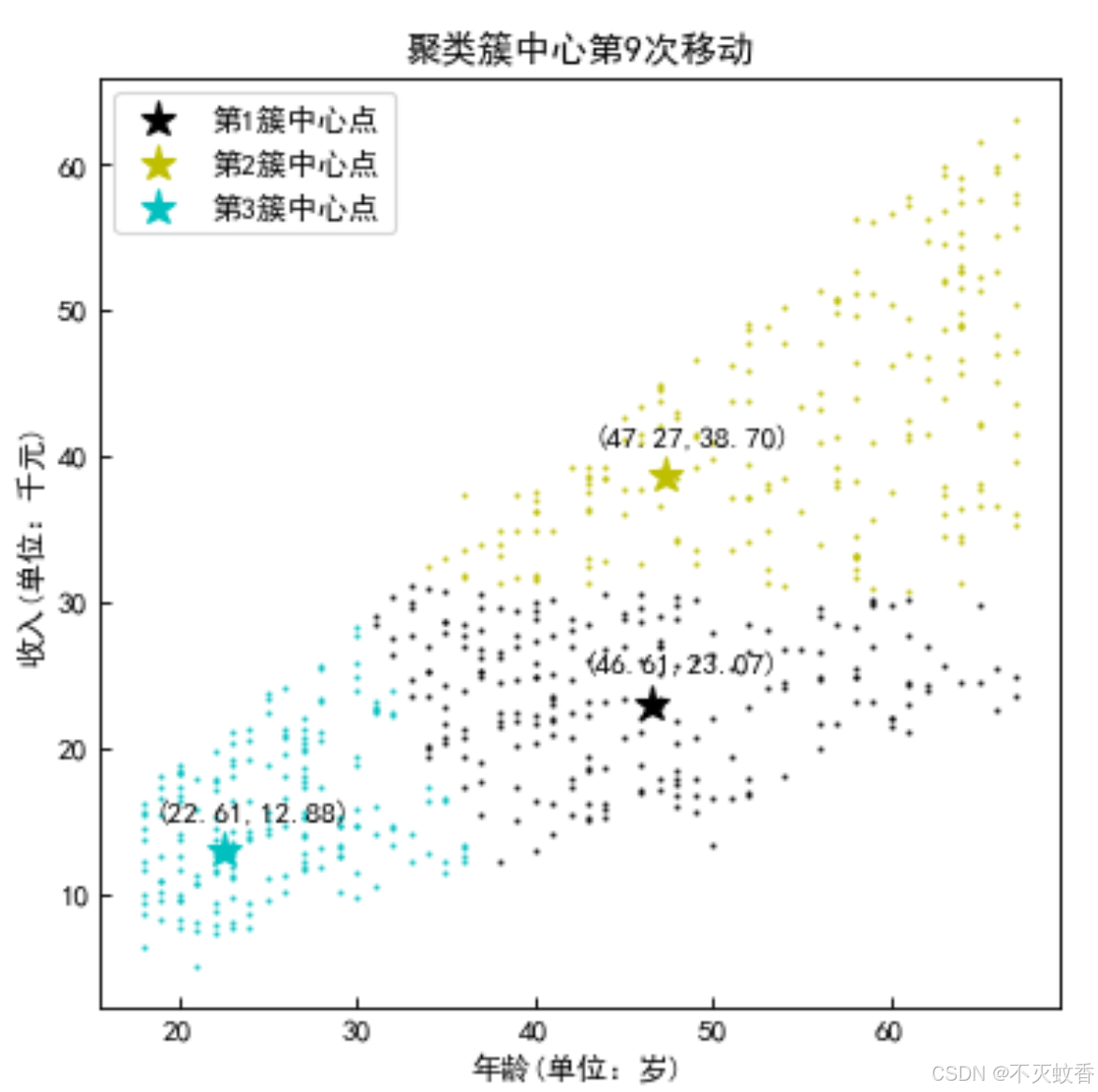
中心点随着数据的聚合而变化。
step4:循环这个过程
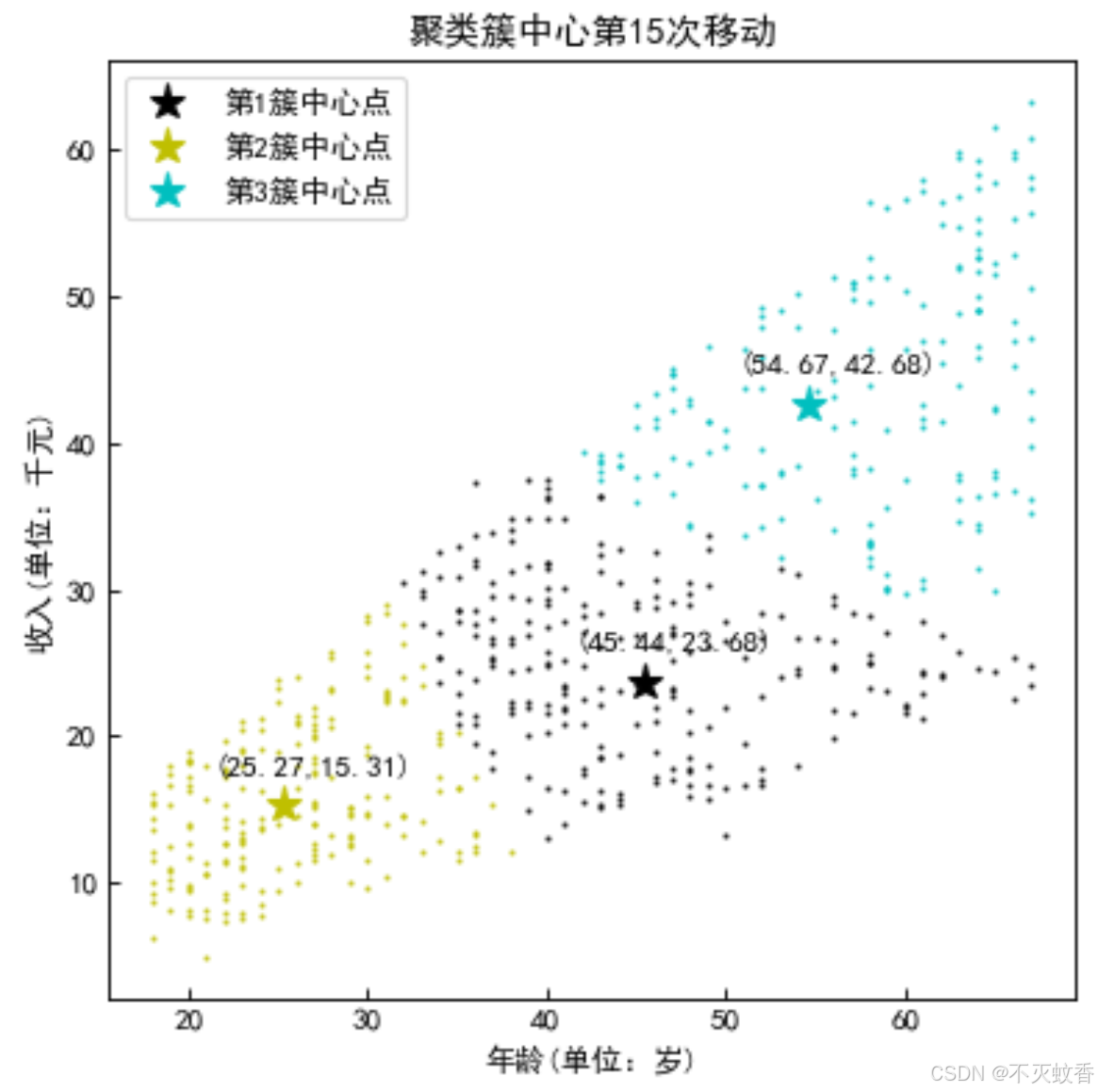
step5:直到平均中心不再有变化
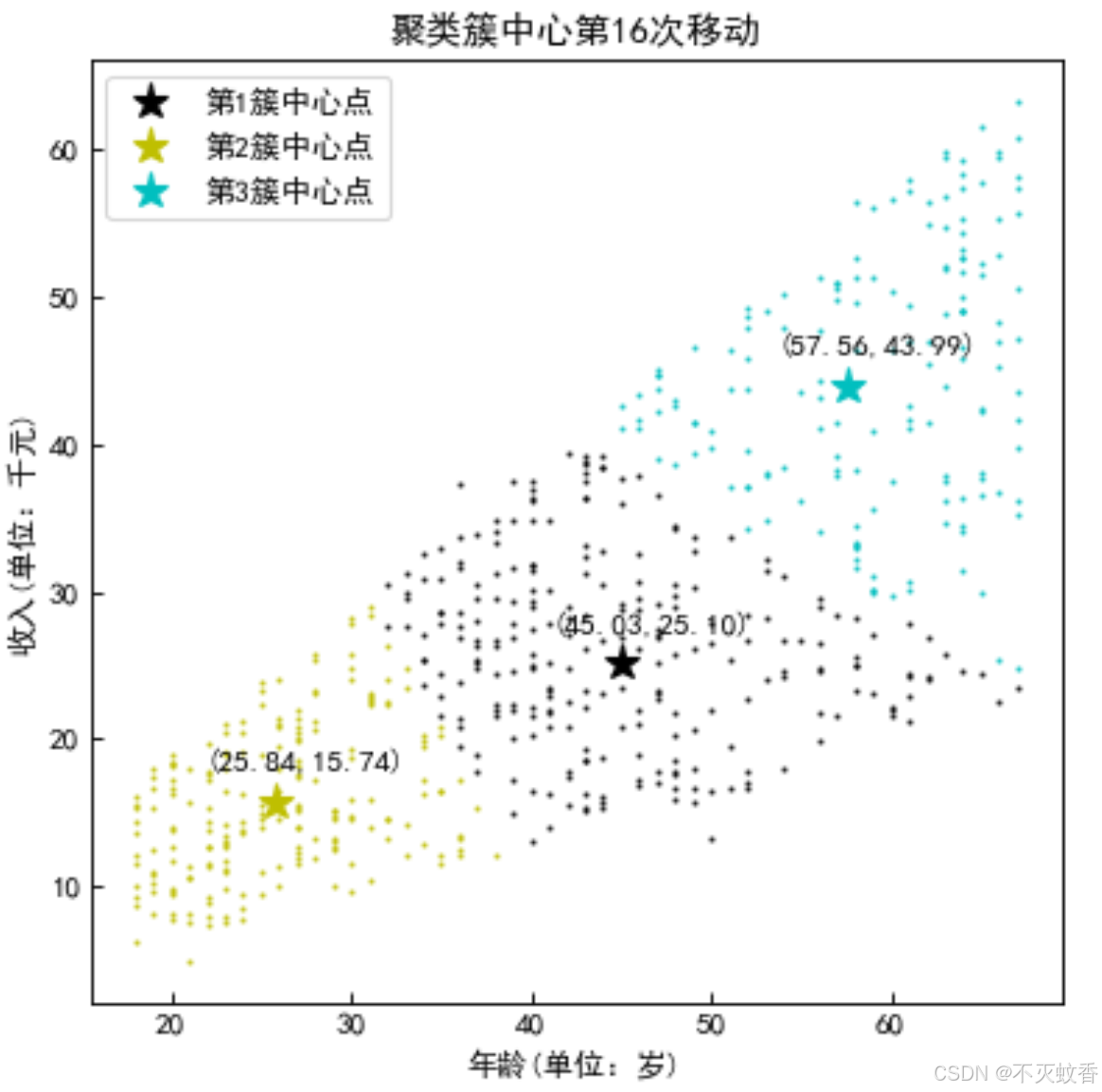
这样就将所有的数据均匀分成三份。
聚类与KNN有何区别,和共同之处?
共同点:
都是算一个距离,最近距离
不同点:
KNN:是一个分类,进行投票
算最近距离,然后进行投票
K-means:算平均距离最近,就加入簇群中
总结:
k - means: 无监督学习(最小平均距离)
1. 随机初始簇中心位置
2. 将所有的数据与簇中心计算距离,将离得近的数据加入簇群中
3. 计算簇群中的平均值,获得新的簇中心点
4. 循环这个过程,直到平均中心不再有变化



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









