






DataFrame最简单的索引便是df[‘列名’],同时两种主要的索引方式。
- 第一种是基于位置(整数)的索引,通过指定我们要选哪几行和哪几列,来筛选出目标数据。
df.iloc[行索引, 列索引]
df.iloc[1, 1]
其中的行索引和列索引也可以用切片、布尔掩码等索引代替。
- 第二种是基于名称(标签)的索引,既可以指定列具体的名称,又可以加上复杂的条件判断,筛选更加灵活。
实际应用过程中,第二种应用得更广泛,操作起来更加灵活,并且更方便。
df.loc[行索引, 列索引]
案例分析
布尔掩码
本文将会用具体的案例场景介绍loc的索引,如下表(部分)所示
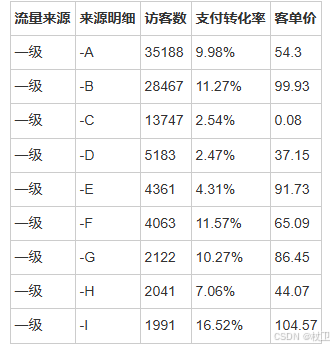
df['流量来源'] == '一级'
上述代码会返回带索引的布尔掩码
在loc方法中,我们可以把这一列判断得到的值传入行参数位置,Pandas会默认返回结果为True的行(这里是索引从0到12的行),而丢掉结果为False的行:
df.loc[df['流量来源'] == '一级',:]
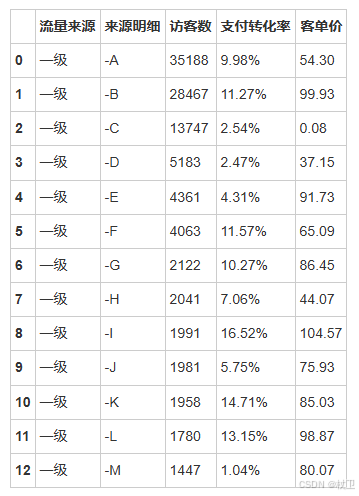
df[‘流量来源’].isin([‘二级’, ‘三级’])函数可用于提取二级、三级流量来源
df.loc[df['流量来源'].isin(['二级','三级']),['流量来源','来源明细','访客数','支付转化率']]
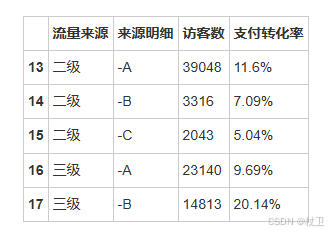
isin函数能够帮助我们快速判断源数据中某一列(Series)的值是否等于列表中的值。拿案例来说,df[‘流量来源’].isin([‘二级’,‘三级’]),判断的是流量来源这一列的值,是否等于“二级”或者“三级”,如果等于(等于任意一个)就返回True,否则返回False。我们再把这个布尔型判断结果传入行参数,就能够很容易的得到流量来源等于二级或者三级的渠道。
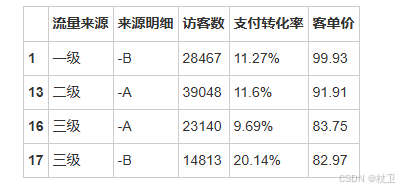
位与运算符(&|~)实现多条件索引
df.loc[(df['访客数'] > df['访客数'].mean()) &
(df['客单价'] > df['客单价'].mean()),:]
总结:
两个函数参数其实差不多,但iloc更适合用于数字索引,loc则是更适合复合条件式索引,这是因为loc函数可以直接识别带索引的布尔掩码而iloc往往不能识别带有index的DataFrame or Series,需要用values获得没有索引的数组,即df.iloc[df[‘列名’].values == 0。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









