 YOLO计算COCO大中小目标指标
YOLO计算COCO大中小目标指标




在目标检测任务中,我们经常看到模型评估指标如precision 、recall、 mAP@0.5、mAP@0.5:0.95,但很多人像要再论文中添加 小目标(small)、中目标(medium)、大目标(large) 的指标,让审稿人知道我们在小目标上面的精度或者多尺度的效果。
视频教程:
YOLO11|YOLO12|改进| 计算COCO指标,叫你如何在论文中体现大、中、小目标的检测精度_哔哩哔哩_bilibili
本文通过一个完整的实践流程,从YOLO训练好的模型出发,手把手带你走完:
1️⃣ 模型验证与结果导出
2️⃣ YOLO → COCO 格式转换
3️⃣ 使用 COCO API 计算大中小目标的mAP和AR指标
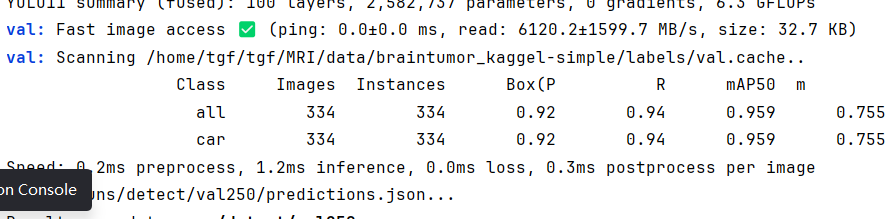
🧩 Step 1:使用YOLO验证模型并生成预测结果
我们首先需要得到模型在验证集上的预测结果,这里使用Ultralytics的YOLO(支持YOLOv8、YOLOv11等版本)进行评估。下面的代码就是我们经常用的评估代码 主要的就是save_json=True,这个参数,将这个打开他在验证的时候会保存一个coco格式的预测的结果,方便下面和标签的coco做对比。
from ultralytics import YOLO,RTDETR
if __name__ == "__main__":
# Load a model
pth_path = "/home/tgf/tgf/MRI/model/YOLO11_MRI/runs/detect/300_base_0.959/weights/best.pt"
# model = YOLO('yolov8n.pt') # load an official model
model = YOLO(pth_path) # load a custom model
# Validate the model
metrics = model.val(data='/home/tgf/tgf/MRI/model/YOLO11_MRI/ultralytics/cfg/datasets/VOC_my.yaml',save_json=True) # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category 这一步运行后,YOLO会在 runs/detect/.../ 文件夹中生成一个 predictions.json 文件。
👉 它保存了每个预测框的坐标、置信度与类别信息,是后续进行COCO评估的关键输入。
🧠 Step 2:YOLO标签 → COCO格式转换
而YOLO原始的标签是每张图片一个 .txt 文件(格式:cls x_center y_center w h)。
因此,我们需要写一个脚本将这些YOLO标签批量转换为标准的COCO JSON。
主要是修改下面这三个部分:
1.类别修改
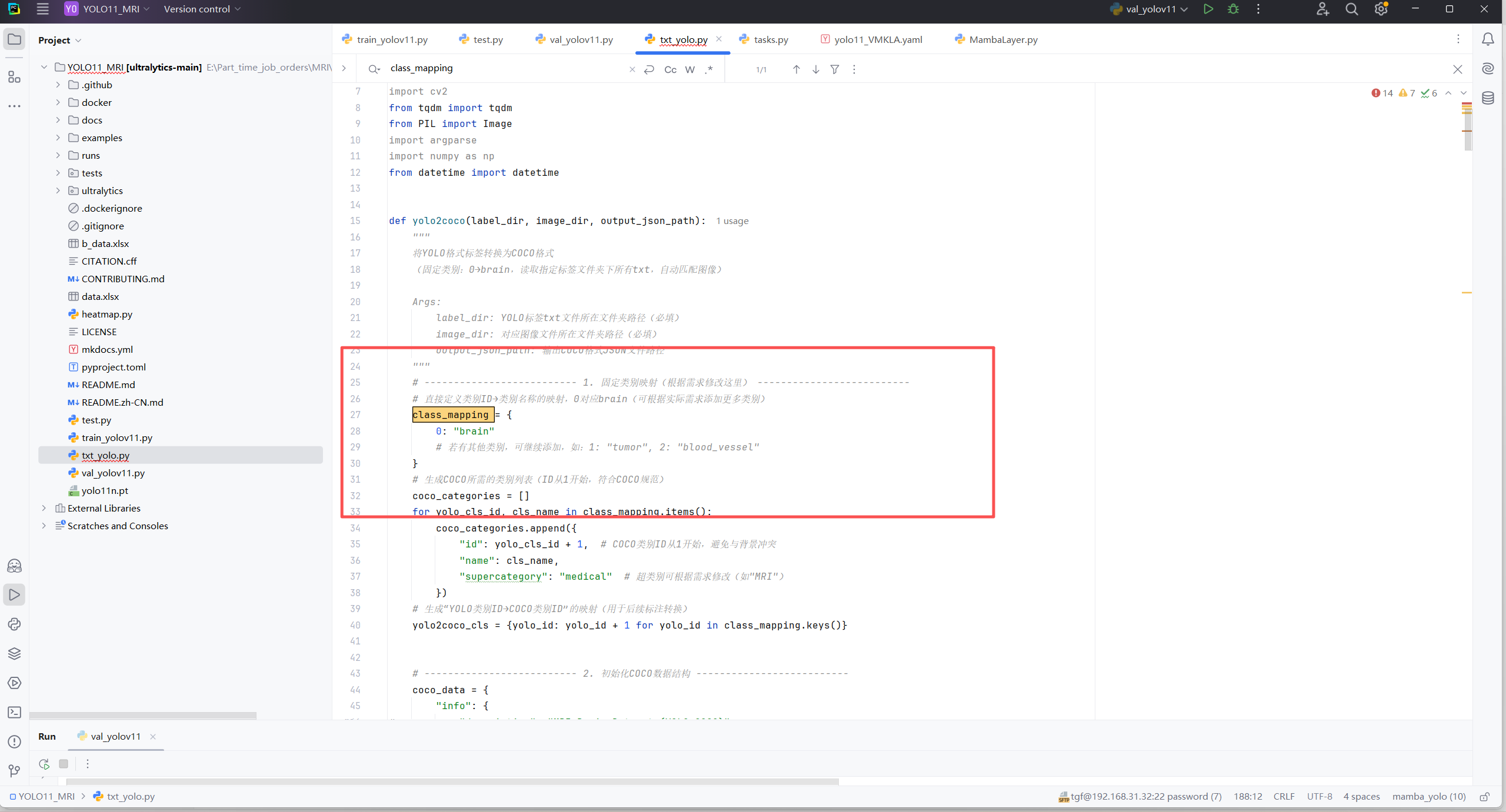
2. 图像路径和标签路径
import os
import json
import glob
import cv2
from tqdm import tqdm
from PIL import Image
import argparse
import numpy as np
from datetime import datetime
def yolo2coco(label_dir, image_dir, output_json_path):
"""
将YOLO格式标签转换为COCO格式
(固定类别:0→brain,读取指定标签文件夹下所有txt,自动匹配图像)
Args:
label_dir: YOLO标签txt文件所在文件夹路径(必填)
image_dir: 对应图像文件所在文件夹路径(必填)
output_json_path: 输出COCO格式JSON文件路径
"""
# -------------------------- 1. 固定类别映射(根据需求修改这里) --------------------------
# 直接定义类别ID→类别名称的映射,0对应brain(可根据实际需求添加更多类别)
class_mapping = {
0: "brain"
# 若有其他类别,可继续添加,如:1: "tumor", 2: "blood_vessel"
}
# 生成COCO所需的类别列表(ID从1开始,符合COCO规范)
coco_categories = []
for yolo_cls_id, cls_name in class_mapping.items():
coco_categories.append({
"id": yolo_cls_id + 1, # COCO类别ID从1开始,避免与背景冲突
"name": cls_name,
"supercategory": "medical" # 超类别可根据需求修改(如"MRI")
})
# 生成“YOLO类别ID→COCO类别ID”的映射(用于后续标注转换)
yolo2coco_cls = {yolo_id: yolo_id + 1 for yolo_id in class_mapping.keys()}
# -------------------------- 2. 初始化COCO数据结构 --------------------------
coco_data = {
"info": {
"description": "MRI Brain Dataset (YOLO→COCO)",
"url": "",
"version": "1.0",
"year": datetime.now().year,
"contributor": "",
"date_created": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
},
"licenses": [
{
"id": 1,
"name": "Unknown",
"url": ""
}
],
"categories": coco_categories,
"images": [],
"annotations": []
}
# -------------------------- 3. 读取所有标签文件 --------------------------
# 获取标签文件夹下所有.txt文件(仅处理txt,避免其他文件干扰)
label_files = glob.glob(os.path.join(label_dir, "*.txt"))
if not label_files:
raise FileNotFoundError(f"在标签文件夹 {label_dir} 中未找到任何.txt标签文件")
print(f"找到 {len(label_files)} 个标签文件,开始匹配图像并转换...")
# -------------------------- 4. 处理每个标签+对应图像 --------------------------
ann_id = 0 # COCO标注ID(自增,唯一标识每个标注)
# 支持的图像格式(可根据实际添加,如.bmp/.tiff)
support_img_ext = [".jpg", ".jpeg", ".png"]
for label_path in tqdm(label_files, desc="处理标签→图像→COCO"):
# 4.1 解析标签文件名(用于匹配图像)
label_filename = os.path.basename(label_path) # 如"img_001.txt"
img_name_without_ext = os.path.splitext(label_filename)[0] # 如"img_001"
# 4.2 寻找对应图像(匹配标签文件名+支持的图像格式)
img_path = None
for ext in support_img_ext:
temp_img_path = os.path.join(image_dir, img_name_without_ext + ext)
if os.path.exists(temp_img_path):
img_path = temp_img_path
break
# 若未找到对应图像,跳过并提示
if not img_path:
print(f"警告:标签文件 {label_filename} 未找到对应图像(支持格式:{support_img_ext}),跳过该标签")
continue
# 4.3 获取图像信息(尺寸、文件名等,COCO必填)
try:
with Image.open(img_path) as img:
img_width, img_height = img.size # 图像宽高(像素)
img_filename = os.path.basename(img_path) # 图像文件名(如"img_001.jpg")
except Exception as e:
print(f"警告:无法读取图像 {img_path}(错误:{str(e)}),跳过该标签")
continue
# 4.4 添加图像信息到COCO(用“标签文件名(无后缀)”作为image_id,确保唯一)
coco_data["images"].append({
"id": img_name_without_ext,
"file_name": img_filename,
"width": img_width,
"height": img_height,
"license": 1,
"date_captured": ""
})
# 4.5 解析标签文件,生成COCO标注
try:
with open(label_path, 'r', encoding='utf-8') as f:
# 读取标签行(跳过空行和注释行)
label_lines = [
line.strip() for line in f.readlines()
if line.strip() and not line.startswith("#")
]
# 处理每行标签(YOLO格式:cls_id x_center y_center width height)
for line in label_lines:
parts = line.split()
# 验证YOLO格式(必须是5个元素:类别ID + 4个坐标参数)
if len(parts) != 5:
print(f"警告:标签文件 {label_filename} 中该行格式错误({line}),跳过该行")
continue
# 解析YOLO参数(注意:YOLO坐标是“归一化后的值”,需转成像素值)
yolo_cls_id = int(parts[0])
# 检查类别ID是否在预定义的class_mapping中
if yolo_cls_id not in class_mapping:
print(f"警告:标签文件 {label_filename} 中类别ID {yolo_cls_id} 未定义(仅支持{list(class_mapping.keys())}),跳过该行")
continue
# 转换为COCO类别ID(从1开始)
coco_cls_id = yolo2coco_cls[yolo_cls_id]
# YOLO归一化坐标(x_center, y_center, width, height)
x_center_norm = float(parts[1])
y_center_norm = float(parts[2])
width_norm = float(parts[3])
height_norm = float(parts[4])
# 转换为COCO格式(左上角坐标x/y + 宽高w/h,像素值)
x = (x_center_norm - width_norm / 2) * img_width # 左上角x
y = (y_center_norm - height_norm / 2) * img_height # 左上角y
w = width_norm * img_width # 目标宽度
h = height_norm * img_height # 目标高度
# 4.6 添加标注到COCO
coco_data["annotations"].append({
"id": ann_id,
"image_id": img_name_without_ext, # 与images中的id对应
"category_id": coco_cls_id, # 与categories中的id对应
"bbox": [round(x, 2), round(y, 2), round(w, 2), round(h, 2)], # 保留2位小数,避免冗余
"area": round(w * h, 2), # 目标面积(像素)
"segmentation": [], # 若无需分割,留空(符合COCO规范)
"iscrowd": 0 # 0=单个目标,1=密集目标(此处默认0)
})
ann_id += 1 # 标注ID自增
except Exception as e:
print(f"警告:处理标签文件 {label_filename} 时出错(错误:{str(e)}),跳过该标签")
continue
# -------------------------- 5. 保存COCO JSON文件 --------------------------
# 确保输出目录存在(若不存在则创建)
output_dir = os.path.dirname(output_json_path)
if not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok=True)
# 保存JSON(ensure_ascii=False支持中文,indent=2格式化显示)
with open(output_json_path, 'w', encoding='utf-8') as f:
json.dump(coco_data, f, ensure_ascii=False, indent=2)
# 输出转换结果统计
print(f"\n转换完成!")
print(f"统计信息:")
print(f" - 处理标签文件:{len(label_files)} 个")
print(f" - 成功匹配图像:{len(coco_data['images'])} 张")
print(f" - 生成标注:{len(coco_data['annotations'])} 个")
print(f" - COCO文件保存路径:{output_json_path}")
def main():
# 命令行参数配置(直接通过终端传入路径,无需修改代码)
parser = argparse.ArgumentParser(description="YOLO标签→COCO格式(固定类别:0→brain)")
# 必选参数:标签文件夹路径(你的txt标签所在目录)
parser.add_argument("--label_dir", type=str, default="/home/tgf/tgf/MRI/data/br35h-simple/labels/val/",
help="YOLO标签txt文件所在文件夹的绝对路径(如:/home/tgf/labels)")
# 必选参数:图像文件夹路径(与标签对应的图像所在目录)
parser.add_argument("--image_dir", type=str, default="/home/tgf/tgf/MRI/data/br35h-simple/images/val/",
help="对应图像文件所在文件夹的绝对路径(如:/home/tgf/images)")
# 可选参数:输出JSON路径(默认保存在当前目录,可自定义)
parser.add_argument("--output", type=str,
default="/home/tgf/tgf/MRI/model/YOLO11_MRI/runs/detect/instances_val2017.json",
help="输出COCO格式JSON的路径(默认:当前目录/instances_val2017.json)")
args = parser.parse_args()
# 调用转换函数
yolo2coco(args.label_dir, args.image_dir, args.output)
if __name__ == "__main__":
main()📊 Step 3:COCO评估(计算大中小目标指标)
有了标注文件和预测文件,我们就可以用COCO官方API(pycocotools)进行标准化评估。
COCO格式是目标检测领域最通用的评估格式之一,COCO API要求我们提供:
-
一个 标注文件(
instances_val2017.json) -
一个 预测文件(
predictions.json)
import argparse
import json
import os
import time
from pathlib import Path
from typing import Tuple, List
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
def validate_json_file(file_path: Path) -> Tuple[bool, str]:
"""验证JSON文件:存在性、文件类型、JSON格式合法性"""
if not file_path.exists():
return False, f"文件不存在 → {file_path}"
if not file_path.is_file():
return False, f"不是有效文件 → {file_path}"
try:
with open(file_path, 'r', encoding='utf-8') as f:
json.load(f)
return True, "JSON文件验证通过"
except json.JSONDecodeError as e:
return False, f"JSON格式错误 → {str(e)}(文件:{file_path})"
except Exception as e:
return False, f"文件读取失败 → {str(e)}(文件:{file_path})"
def print_iou50_size_metrics(stats: np.ndarray) -> None:
"""
单独打印 IoU=0.5 阈值下大、中、小目标的 AP 和 AR 指标
COCOeval.stats 数组索引对应关系(关键):
- 1: AP@0.5(整体)
- 3: AP@0.5(小目标,面积 < 32²)
- 4: AP@0.5(中目标,32² ≤ 面积 < 96²)
- 5: AP@0.5(大目标,面积 ≥ 96²)
- 7: AR@0.5(整体)
- 9: AR@0.5(小目标)
- 10: AR@0.5(中目标)
- 11: AR@0.5(大目标)
"""
# 定义尺寸分类的中文说明
size_desc = {
"small": "小目标(面积 < 32×32)",
"medium": "中目标(32×32 ≤ 面积 < 96×96)",
"large": "大目标(面积 ≥ 96×96)"
}
print("\n" + "=" * 60)
print("📊 IoU=0.5 阈值下 大/中/小目标 专项评估结果")
print("=" * 60)
print(f"{'目标尺寸':<20} {'AP@0.5':<10} {'AR@0.5':<10}")
print("-" * 60)
# 小目标
print(f"{size_desc['small']:<20} {stats[3]:<10.4f} {stats[9]:<10.4f}")
# 中目标
print(f"{size_desc['medium']:<20} {stats[4]:<10.4f} {stats[10]:<10.4f}")
# 大目标
print(f"{size_desc['large']:<20} {stats[5]:<10.4f} {stats[11]:<10.4f}")
# 整体对比
print("-" * 60)
print(f"{'整体目标':<20} {stats[1]:<10.4f} {stats[7]:<10.4f}")
def print_overall_summary(stats: np.ndarray, class_names: List[str]) -> None:
"""打印完整的COCO评估指标汇总(含所有IoU阈值和尺寸)"""
metrics = [
("AP@[0.5:0.95]", "所有IoU阈值平均精度"),
("AP@0.5", "IoU=0.5平均精度"),
("AP@0.75", "IoU=0.75平均精度"),
("AP小目标", "IoU[0.5:0.95]小目标精度"),
("AP中目标", "IoU[0.5:0.95]中目标精度"),
("AP大目标", "IoU[0.5:0.95]大目标精度"),
("AR@[0.5:0.95]", "所有IoU阈值平均召回率"),
("AR@0.5", "IoU=0.5平均召回率"),
("AR@0.75", "IoU=0.75平均召回率"),
("AR小目标", "IoU[0.5:0.95]小目标召回率"),
("AR中目标", "IoU[0.5:0.95]中目标召回率"),
("AR大目标", "IoU[0.5:0.95]大目标召回率")
]
print("\n" + "=" * 60)
print(f"📋 完整评估结果汇总(检测类别:{', '.join(class_names)})")
print("=" * 60)
for i, (metric_name, metric_desc) in enumerate(metrics):
print(f"{metric_name:<15} | {metric_desc:<25} | {stats[i]:.4f}")
def evaluate_coco(pred_json: Path, anno_json: Path) -> np.ndarray:
"""核心评估逻辑:初始化COCO API、执行评估、输出结果"""
print(f"\n[开始评估]")
print(f"标注文件路径 → {anno_json}")
print(f"预测文件路径 → {pred_json}")
# 1. 先验证输入文件合法性
for file in [pred_json, anno_json]:
valid, msg = validate_json_file(file)
if not valid:
raise ValueError(f"文件验证失败:{msg}")
try:
start_time = time.time()
# 2. 初始化COCO标注和预测API
coco_anno = COCO(str(anno_json)) # 标注数据
coco_pred = coco_anno.loadRes(str(pred_json)) # 预测数据(基于标注API加载)
# 3. 获取数据集类别信息
cat_ids = coco_anno.getCatIds()
cat_info = coco_anno.loadCats(cat_ids)
class_names = [cat["name"] for cat in cat_info]
# 4. 执行bbox(边界框)评估
coco_eval = COCOeval(coco_anno, coco_pred, "bbox") # 指定评估类型为边界框
coco_eval.evaluate() # 计算评估指标
coco_eval.accumulate() # 累积统计结果
# 5. 输出评估结果(分三部分:原始详细结果、IoU50专项、整体汇总)
print("\n" + "-" * 80)
print("🔍 pycocotools 原始评估结果(详细)")
print("-" * 80)
coco_eval.summarize() # 打印pycocotools默认详细结果
# 单独打印IoU50大中小目标指标(本次改进核心)
print_iou50_size_metrics(coco_eval.stats)
# 打印完整指标汇总
print_overall_summary(coco_eval.stats, class_names)
# 6. 计算评估耗时
end_time = time.time()
cost_time = end_time - start_time
print(f"\n[评估完成] 总耗时:{cost_time:.2f}秒")
return coco_eval.stats # 返回完整统计结果数组,便于后续二次处理
except Exception as e:
raise RuntimeError(f"评估过程出错:{str(e)}") from e
def main():
"""命令行参数解析与主函数入口"""
parser = argparse.ArgumentParser(
description="COCO格式目标检测结果评估工具(支持IoU50大中小目标分析)",
formatter_class=argparse.ArgumentDefaultsHelpFormatter # 显示参数默认值
)
parser.add_argument('--annotations', type=str, default="/home/tgf/tgf/MRI/model/YOLO11_MRI/runs/detect/instances_val2017.json",
help='COCO格式的标注文件路径')
parser.add_argument('--predictions', type=str, default="/home/tgf/tgf/MRI/model/YOLO11_MRI/runs/detect/val6_GCE/predictions.json",
help='预测结果的JSON文件路径')
parser.add_argument(
"--verbose", "-v", action="store_true", default=False,
help="启用详细模式:显示更多评估过程日志(如类别数量、图像数量)"
)
args = parser.parse_args()
# 转换为绝对路径,避免相对路径问题
pred_json = Path(args.predictions).resolve()
anno_json = Path(args.annotations).resolve()
# 执行评估并捕获异常
try:
if args.verbose:
# 详细模式:打印数据集基本信息
coco_anno = COCO(str(anno_json))
print(f"\n[详细信息] 数据集包含:")
print(f"图像数量 → {len(coco_anno.getImgIds())}张")
print(f"类别数量 → {len(coco_anno.getCatIds())}类")
evaluate_coco(pred_json, anno_json)
except Exception as e:
print(f"\n❌ 评估失败:{str(e)}", file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
import sys # 延迟导入,仅主函数需要
main()


















 6847
6847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









