 YOLO11改进:DPCF提升小目标检测
YOLO11改进:DPCF提升小目标检测





在计算机视觉的多尺度任务中,高分辨率特征与低分辨率特征的互补性是提升模型性能的关键 —— 高分辨率特征承载着目标边缘、纹理等精细细节信息,是定位小目标、识别目标局部特征的核心;低分辨率特征经过多次下采样,整合了全局上下文与语义信息,能帮助模型区分目标类别、排除背景干扰。然而,传统的多尺度融合方法(如直接加法、固定权重拼接)存在显著缺陷:一方面,固定的融合比例无法适配不同区域的特征需求,例如在小目标区域过度依赖低分辨率语义特征会导致细节丢失,在背景区域过度保留高分辨率细节会引入噪声;另一方面,缺乏对通道维度的针对性处理,不同通道承载的特征信息(如边缘通道、纹理通道)无法得到差异化融合,导致融合后特征的判别性不足。随着目标检测、图像分割对 “细节 - 语义平衡” 要求的提升,传统方法已难以满足需求,细节保留上下文融合(DPCF)模块由此提出,旨在通过自适应融合策略解决 “细节丢失” 与 “语义冗余” 的双重矛盾。
1. DPCF原理
DPCF 模块的核心原理是 “分区域自适应调控,细节与语义协同保留”,通过三层逻辑实现多尺度特征的高效融合:
特征对齐铺垫:首先解决高低分辨率特征的 “维度不匹配” 问题 —— 通过双线性插值将低分辨率特征上采样至与高分辨率特征一致的空间尺寸,再通过 1×1 卷积调整两者通道数,确保后续融合在相同维度下进行,避免因维度差异导致的信息错位。
通道分段与动态门控:将对齐后的高低分辨率特征按通道拆分为多个子段,针对每个子段设计可学习的空间门控机制。门控参数通过训练学习,生成取值在 [0,1] 区间的权重矩阵:当权重接近 0 时,优先保留高分辨率子段的细节信息,适配小目标、边缘等细节敏感区域;当权重接近 1 时,侧重整合低分辨率子段的语义信息,适配背景、目标主体等语义主导区域,实现 “哪里需要细节就保细节,哪里需要语义就融语义” 的动态调控。
融合优化收尾:对每个子段完成自适应加权融合后,将所有子段重新拼接为完整特征图,再通过卷积块(含卷积、批归一化、激活函数)消除通道间的冗余信息,强化融合特征的一致性与判别性,确保输出特征既保留细节又富含语义。
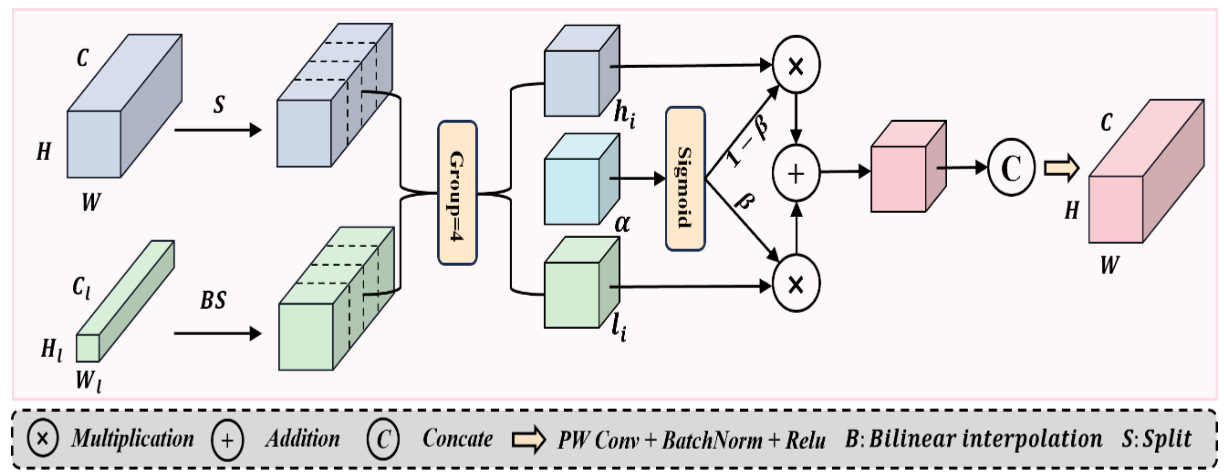
2. DPCF习作思路
在目标检测任务中:DPCF 模块能精准解决 “小目标难检出” 与 “背景易误判” 的痛点。其通道分段与动态门控机制,可在小目标、遮挡目标等细节敏感区域,优先保留高分辨率特征的空间细节,避免传统融合中细节被语义特征覆盖导致的 “漏检”;在背景复杂区域,通过强化低分辨率语义特征,帮助模型区分 “目标与相似背景”(如密集场景中的小目标与背景 clutter),减少因细节噪声导致的 “假阳性”,同时保障目标类别判断的准确性。
在目标检测任务中:DPCF 模块可同时满足 “边界精细” 与 “区域一致” 的需求。对于分割边界、细小组件(如医疗影像中的微小病灶、自然场景中的纤细目标),其门控机制会侧重高分辨率细节特征,避免传统融合导致的 “边界模糊”“区域断裂”;对于大面积同类区域(如分割后的目标主体、背景区域),则通过语义特征强化,确保区域内部的语义一致性,减少 “同类区域错分”,尤其适用于细粒度分割任务,提升分割结果的视觉完整性与分类准确性。
3. YOLO与VDPCF的结合
将 DPCF 模块融入 YOLO 架构,可针对性优化其多尺度特征融合环节:一是解决 YOLO 传统 FPN(特征金字塔网络)中 “高低分辨率特征权重固定” 的问题,通过动态门控保留小目标、遮挡目标的细节,显著提升这类难点目标的检测精度;二是在 YOLO 的特征融合过程中,DPCF 能根据不同区域的特征需求差异化整合细节与语义,帮助模型在复杂场景(如密集目标、复杂背景)中降低误判率,且模块计算开销小,不会影响 YOLO 固有的实时检测性能。
4.DPCF代码部分
YOLO11|YOLO12|改进| 细节保留上下文融合模块DPCF,通过动态门控保留小目标、遮挡目标的细节,显著提升这类难点目标的检测精度。_哔哩哔哩_bilibili
YOLOv11模型改进讲解,教您如何修改YOLOv11_哔哩哔哩_bilibili
代码获取:YOLOv8_improve/YOLOv11.md at master · tgf123/YOLOv8_improve
5. DPCF到YOLOv11中
第一: 将下面的核心代码复制到D:\model\yolov11\ultralytics\change_model路径下,如下图所示。
第二:在task.py中导入包
第三:在task.py中的模型配置部分下面代码
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO("/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/models/11/yolo11_DPCF.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = False
)

















 5361
5361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









