




MANO 的提出是为了解决传统 Transformer 在视觉和物理模拟任务中因二次复杂度导致的高计算和内存开销问题。尽管已有一些方法通过局部窗口、下采样或低秩近似来降低复杂度,但这些方法往往以牺牲细节和全局上下文为代价。MANO 受多体数值模拟中的快速多极方法(FMM)启发,将注意力计算建模为网格点之间的多尺度交互问题,旨在以线性复杂度实现高效且表达力强的特征建模。
1.MANO原理
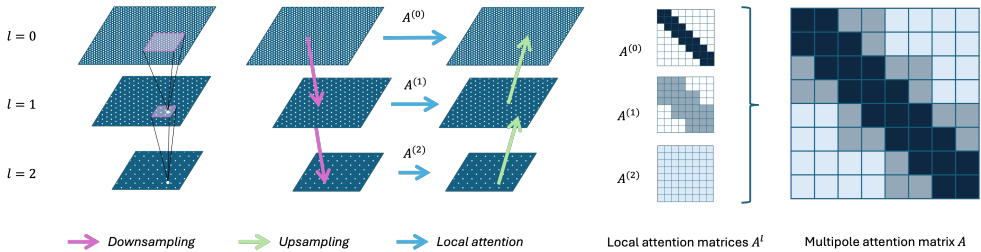
MANO 的核心原理是通过分层多尺度机制近似全局注意力。其结构包含以下关键组成部分:
-
多级特征金字塔:输入特征通过共享卷积核逐级下采样(如使用 2×2卷积核,步长 2),形成多分辨率特征图
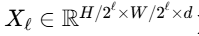 。
。 -
局部窗口注意力:在每个层级ℓ上,将特征图划分为滑动窗口(如 8×8窗口),并在窗口内计算标准注意力
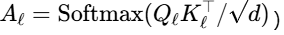 ,其中
,其中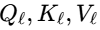 由同一层级特征映射生成。
由同一层级特征映射生成。 -
跨层级特征融合:注意力输出
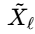 通过转置卷积上采样至原始分辨率,并与其它层级的输出求和
通过转置卷积上采样至原始分辨率,并与其它层级的输出求和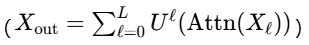 ,实现细节与全局上下文的整合。
,实现细节与全局上下文的整合。 -
参数共享与复杂度:下采样/上采样卷积核及注意力权重在不同层级共享,确保参数效率。总复杂度为 O(N)(N为网格点数),显著优于全局注意力的
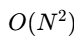 。
。
2.MANO 习作思路
-
目标检测:MANO 的多尺度注意力机制能够同时捕捉局部细节(如小目标边缘)和全局上下文(如场景布局),通过分层融合避免因下采样丢失关键信息。其线性复杂度支持高分辨率输入处理,提升检测精度和鲁棒性,尤其适用于密集或小目标场景。
-
语义分割:MANO 在保持长程依赖的同时高效整合多尺度特征,能准确预测复杂边界和拓扑结构。分层注意力允许模型在粗粒度上建模语义关系,在细粒度上细化边缘,优于仅依赖局部窗口或全局池化的方法。
3. YOLO与MANO 的结合
将 MANO 嵌入 YOLO 可增强多尺度特征融合能力,提升对小目标和复杂背景的检测灵敏度;其线性注意力机制降低计算开销,支持更高输入分辨率或实时推理;同时,分层结构兼容YOLO的金字塔网络设计,无需显著增加参数即可优化特征表达能力。
4.MANO 代码部分
YOLO11|YOLO12|改进| 多极注意力神经算子MANO 通过多尺度分层注意力机制,以线性复杂度实现全局感知与局部细节的高效融合_哔哩哔哩_bilibili
YOLO12模型改进方法,快速发论文,总有适合你的改进,还不改进上车_哔哩哔哩_bilibili
代码获取:YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. MANO 引入到YOLOv12中
第一: 先新建一个v12_changemodel,将下面的核心代码复制到下面这个路径当中,如下图如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。
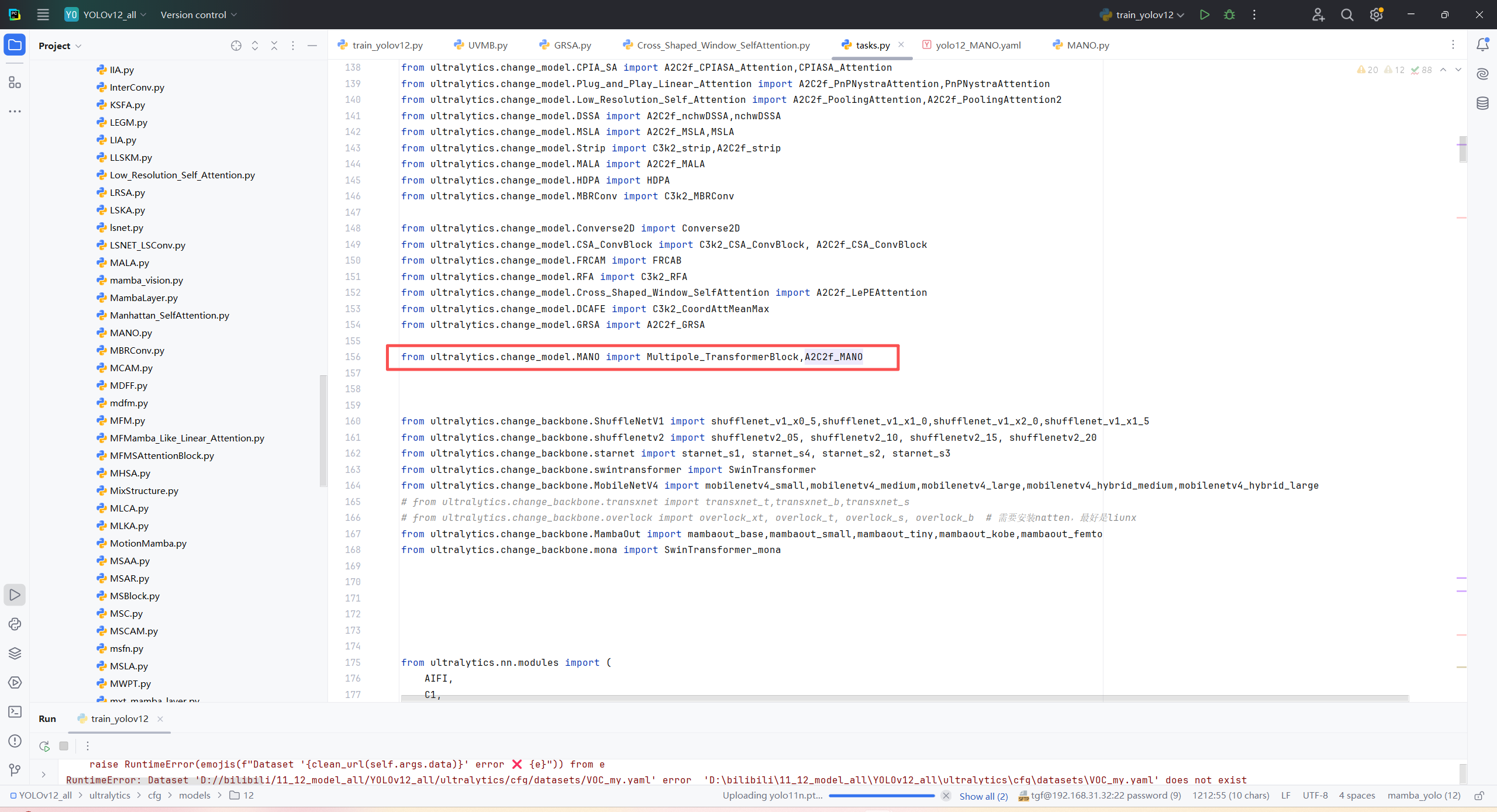
第二:在task.py中导入包
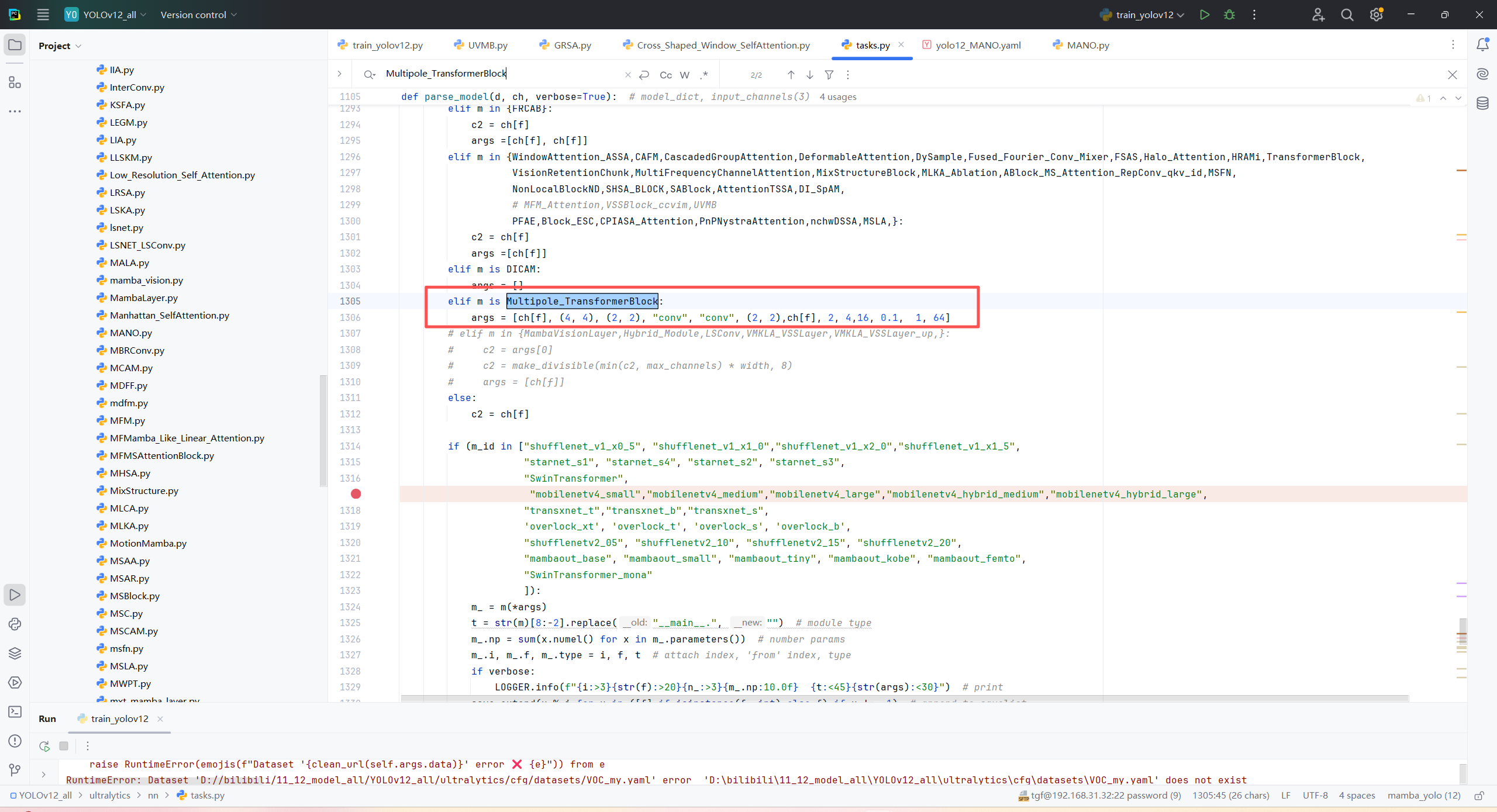
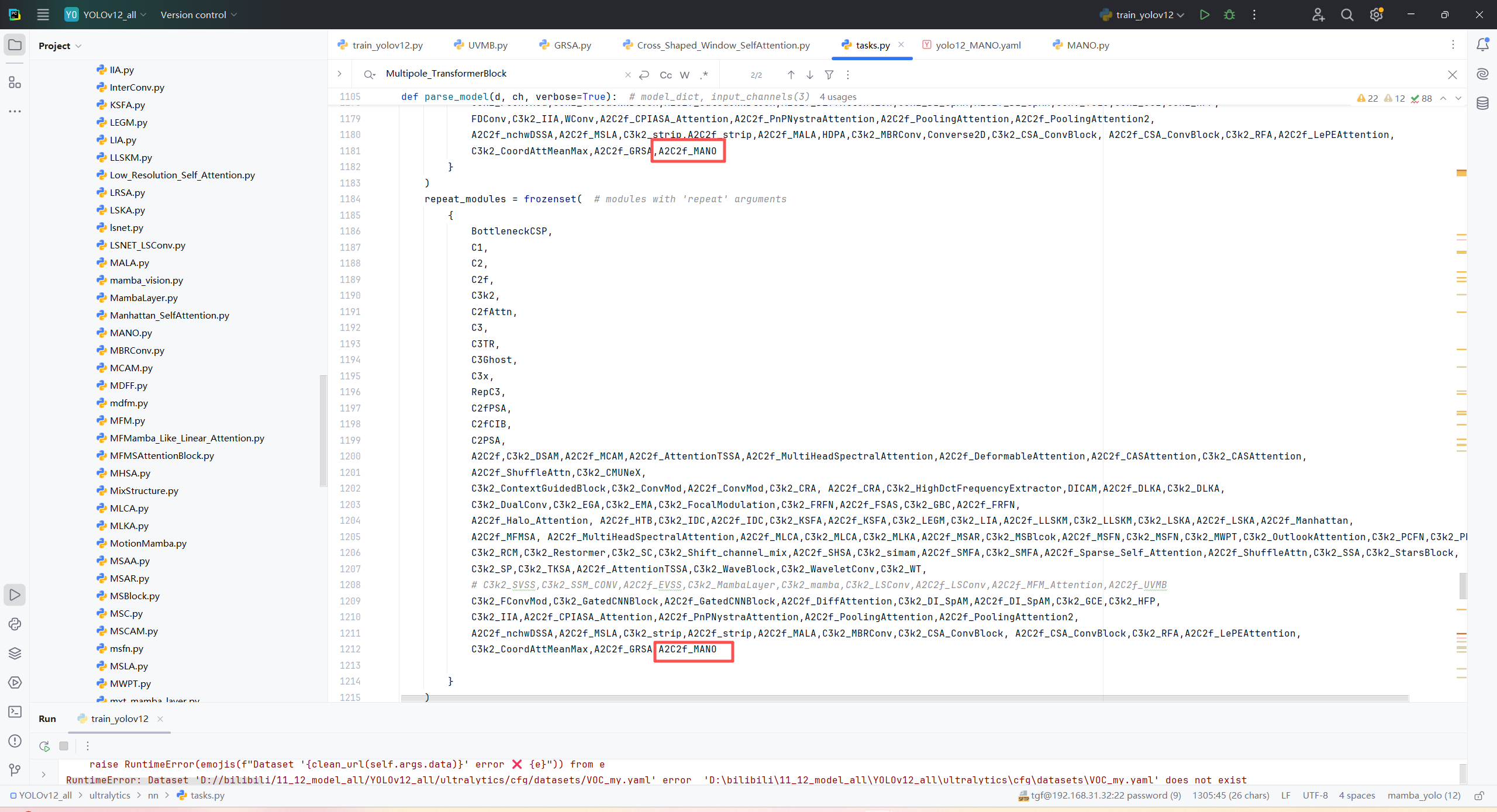
第三:在task.py中的模型配置部分下面代码
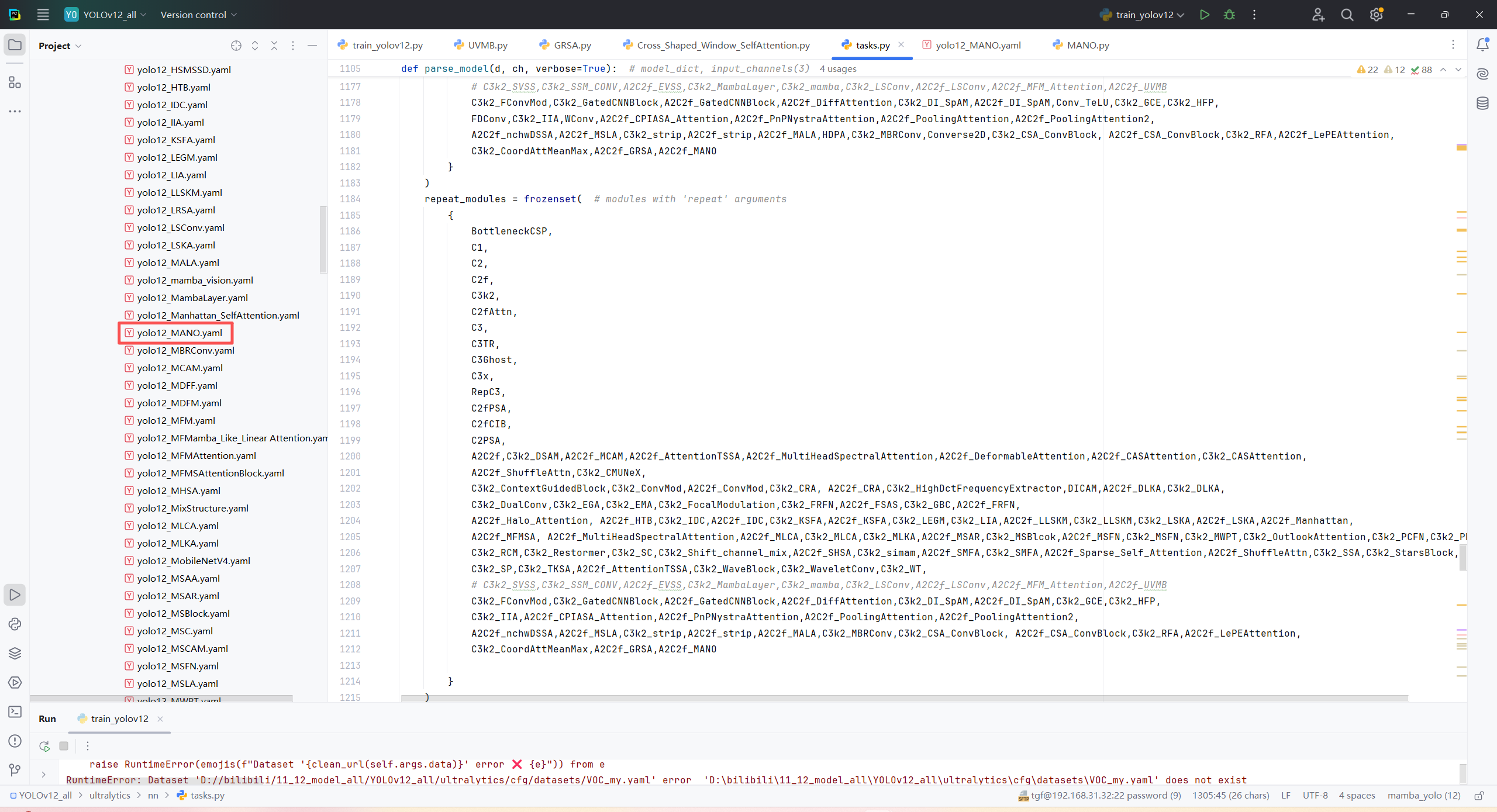
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO("/home/tgf/tgf/yolo/model/YOLO12_All/ultralytics/cfg/models/12/yolo12_MANO.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)

















 35
35

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









