







目录
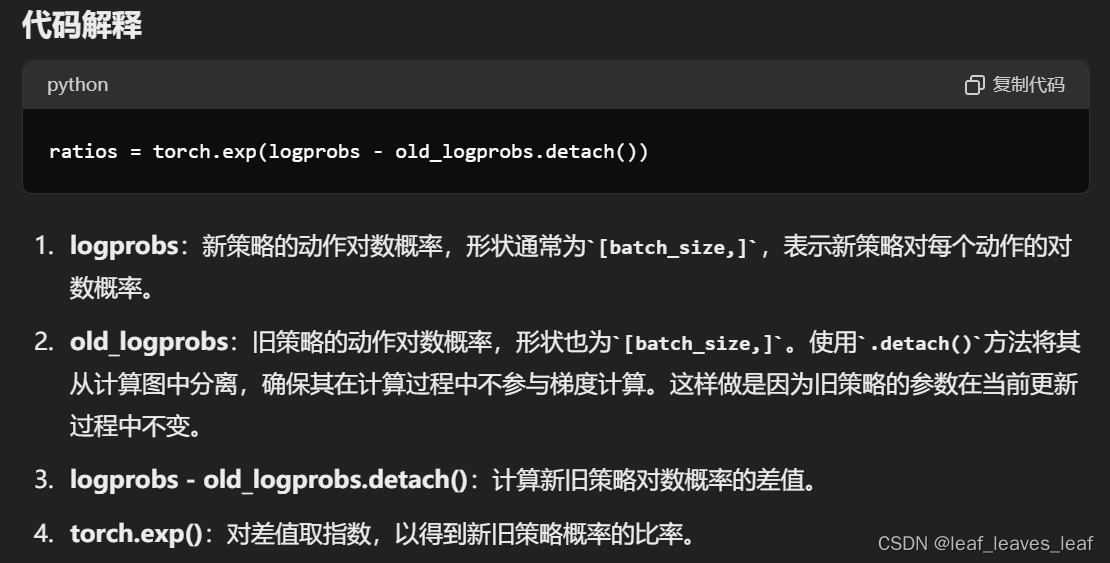
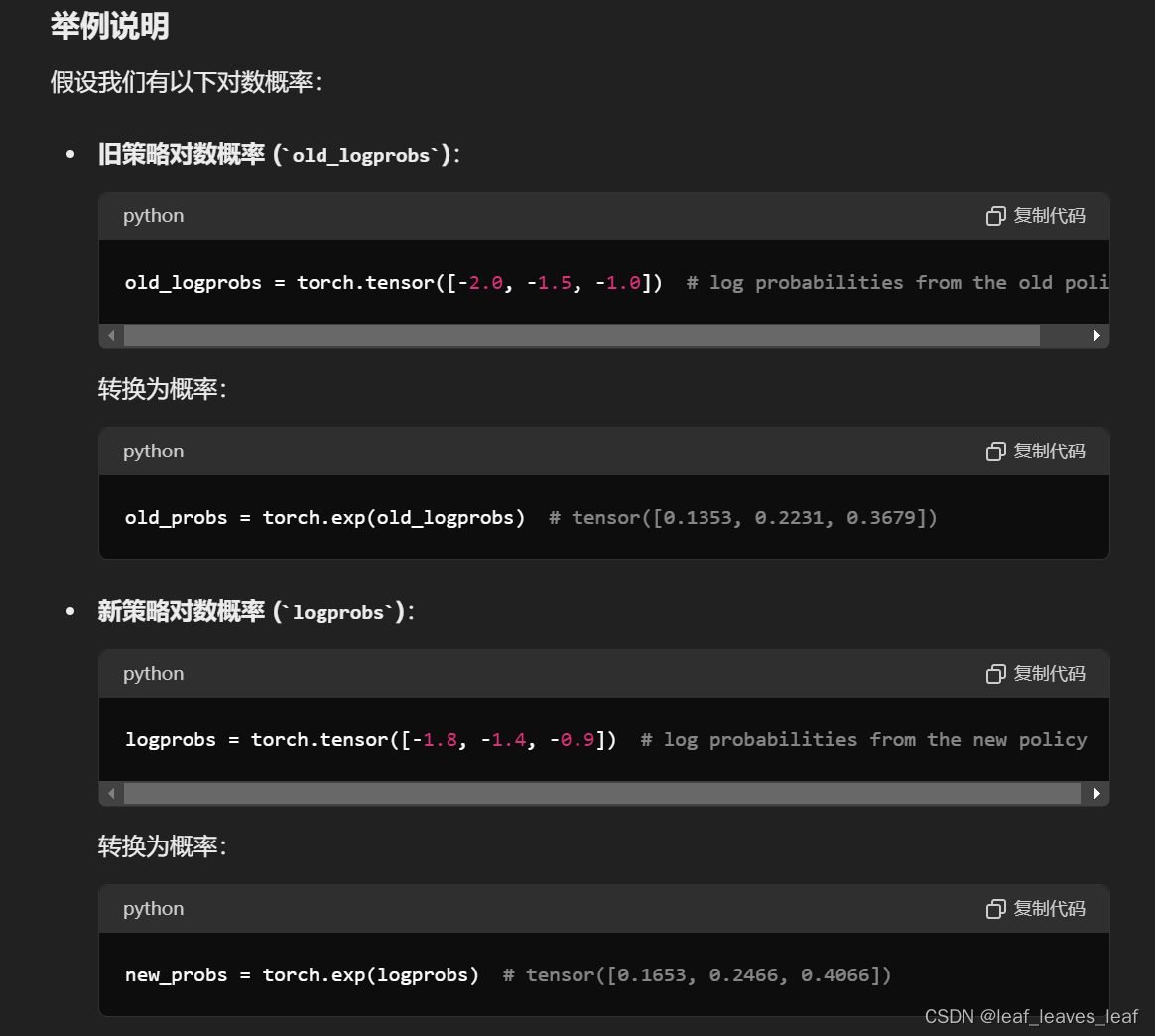
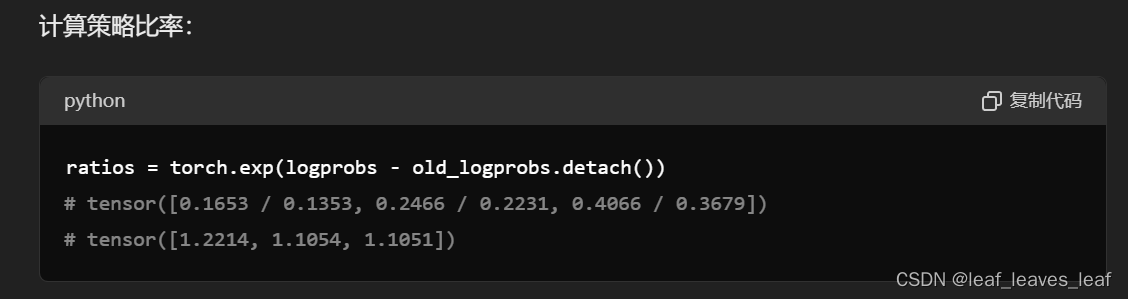
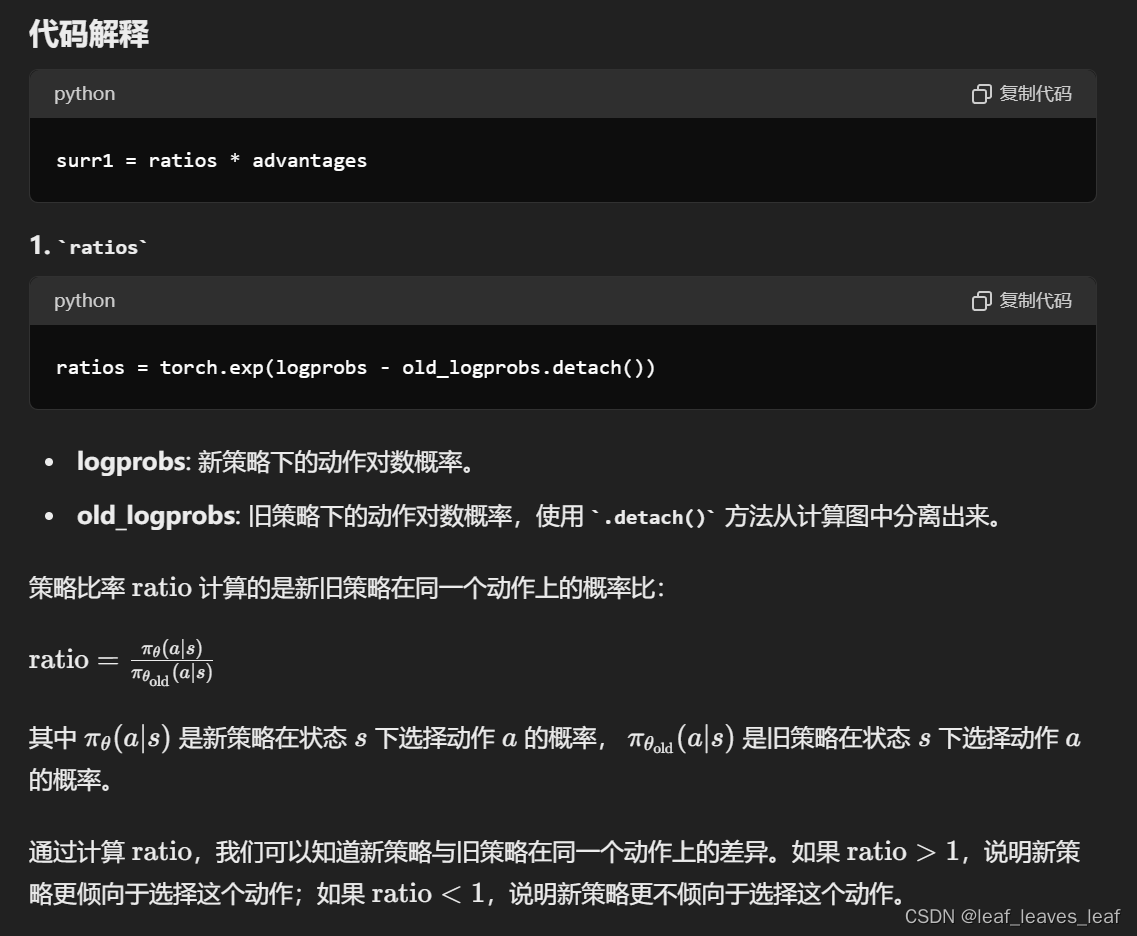
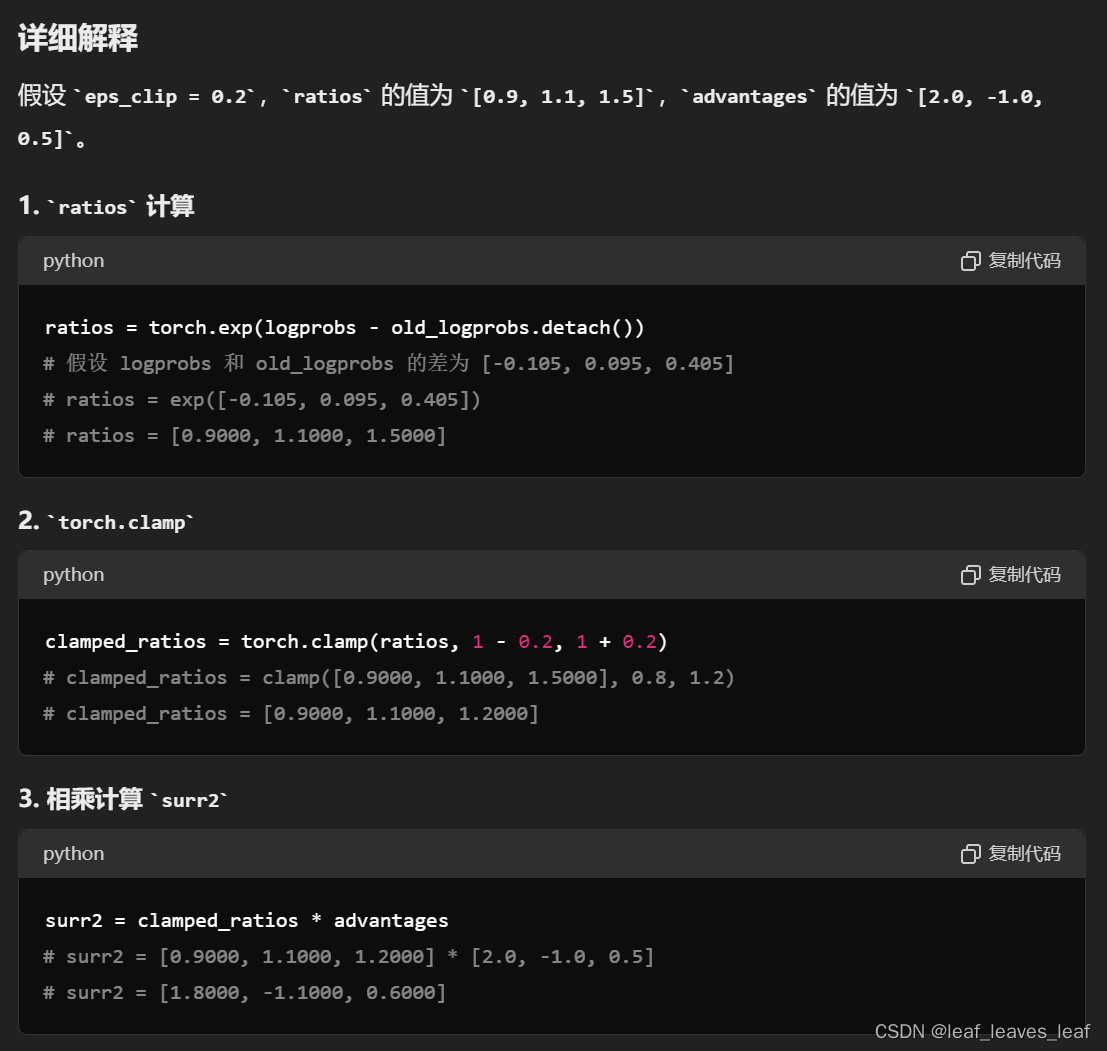
# Finding the ratio (pi_theta / pi_theta__old): ratios = torch.exp(logprobs - old_logprobs.detach())
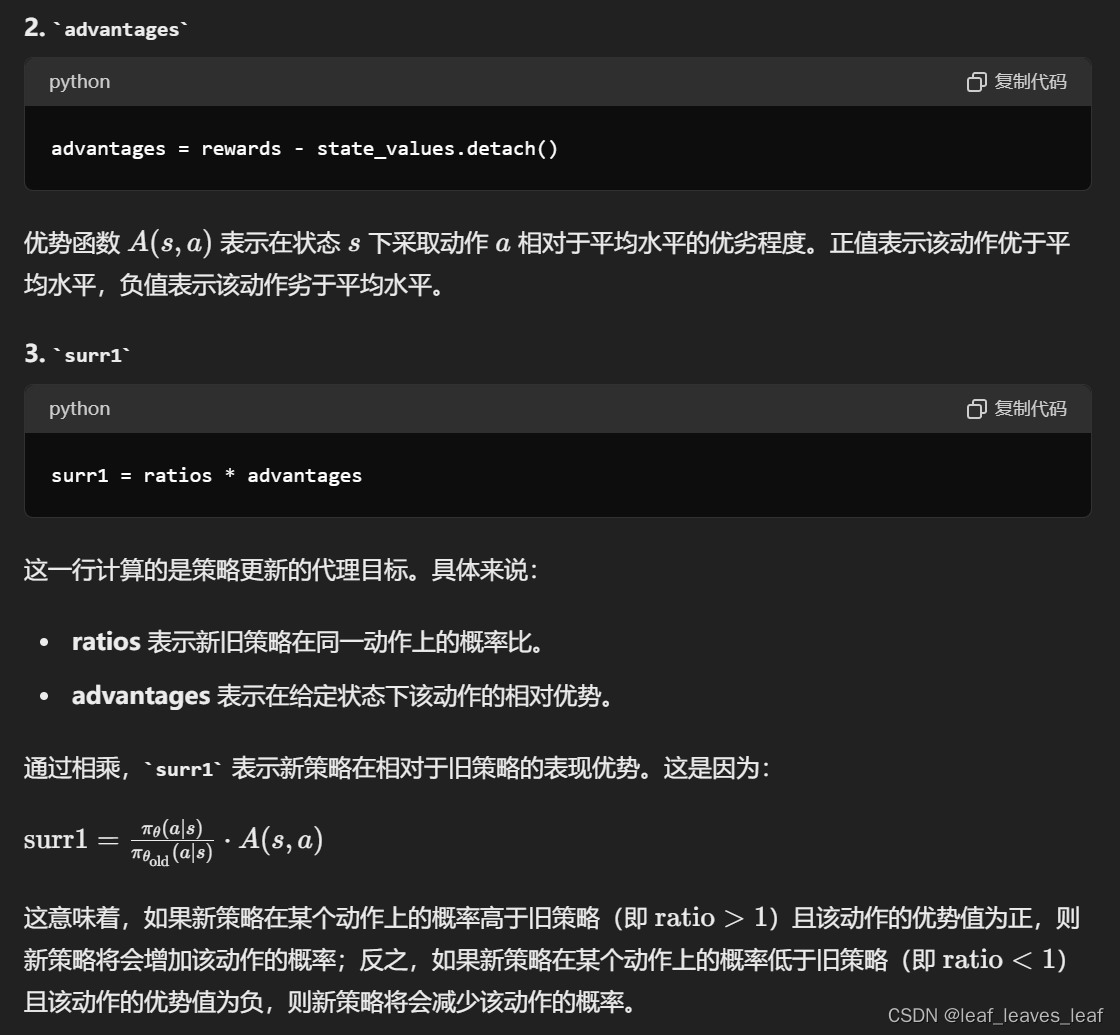
advantages = rewards - state_values.detach()
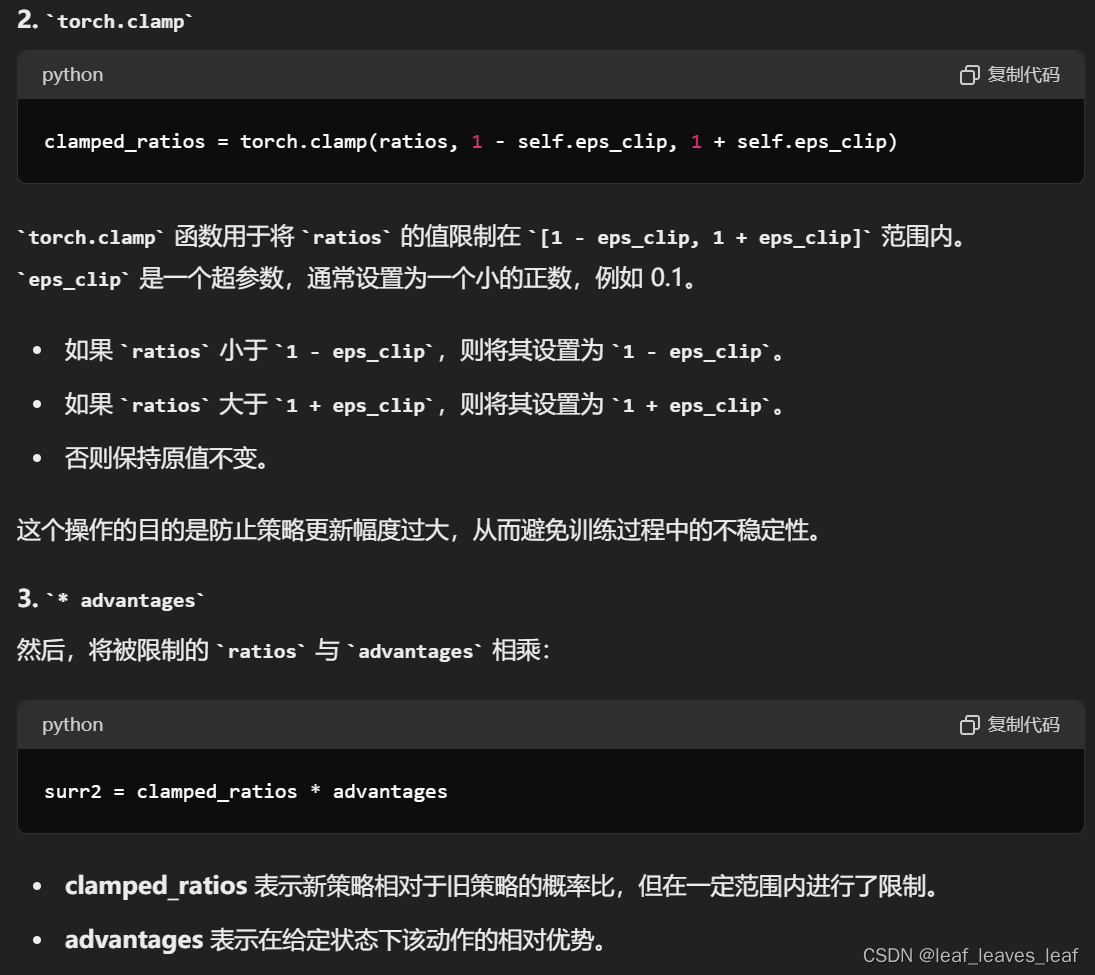
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
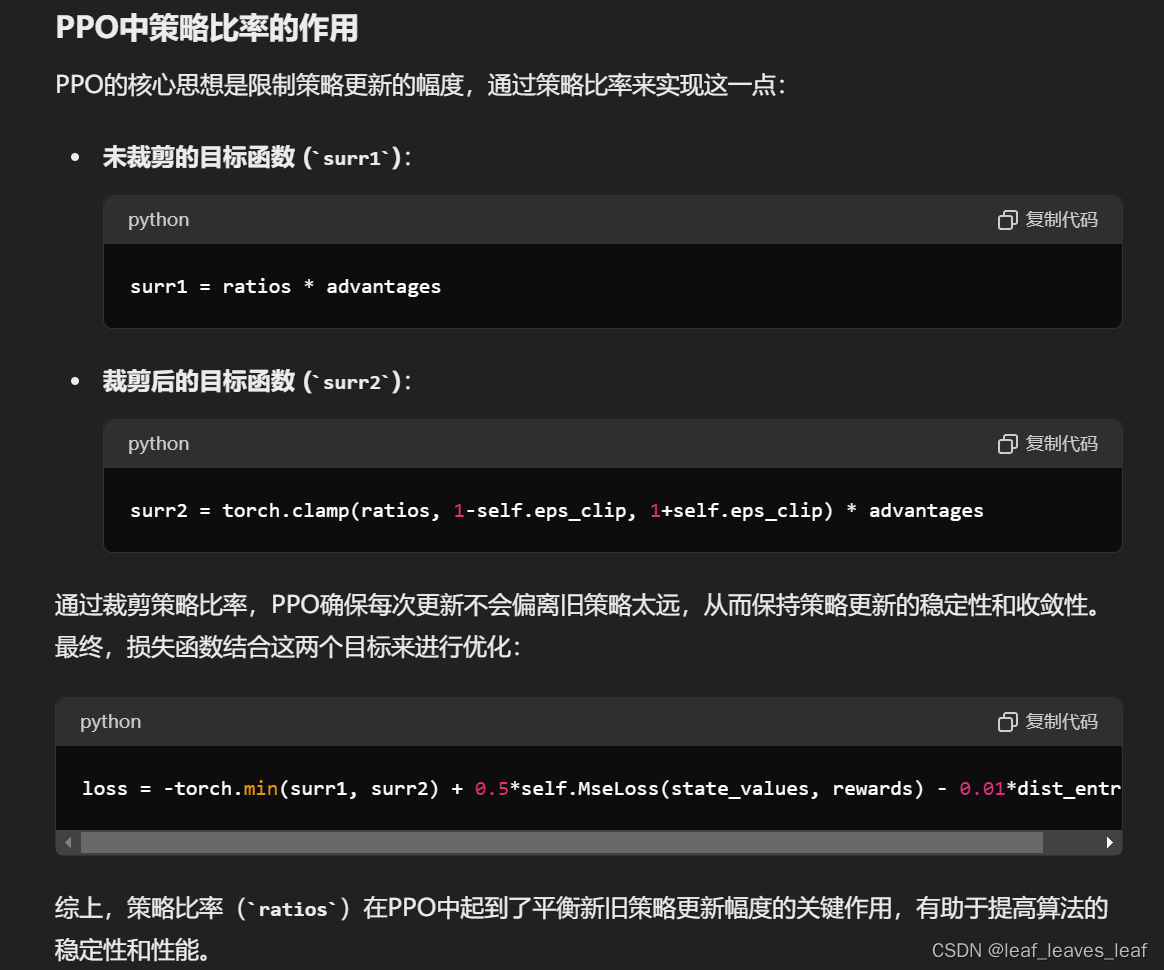
为什么最大化用新旧策略概率比率乘以优势函数,即ratios * advantages这个式子就可以代表最大化收益?
详细解释一下上面回答的第一个公式,即策略梯度定理给出的策略参数的梯度形式
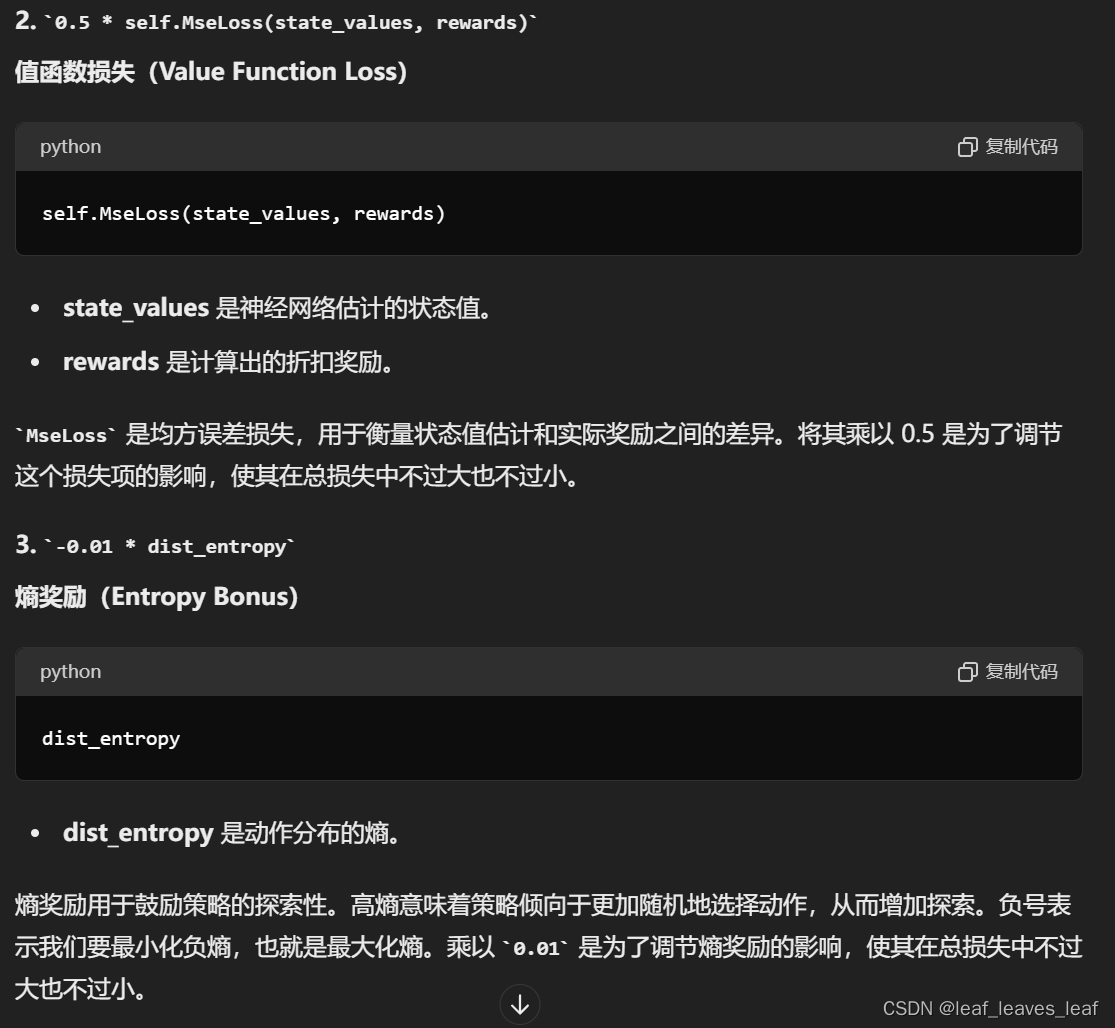
详细解释一下0.5*self.MseLoss(state_values, rewards)它的意义
为什么价值网络可以估计在给定状态下,智能体未来能获得的总奖励的期望值,它是怎么估计出来的?
优势函数 A(s,a) 表示在状态 s 下采取动作 a 相对于平均水平的优劣程度。正值表示该动作优于平均水平,负值表示该动作劣于平均水平。为什么state_values可以代表平均水平
V(s)在代码中只是个神经网络呀,输入736个特征,输出一个值,为什么它就是对所有可能动作的期望奖励的估计
状态-动作值函数Q(s,a)意思是采取动作 a 所能带来的预期奖励,而状态值函数V(s)意思是采取所有可能动作的平均奖励,采取的动作都不一样,为什么要让他们接近
# Finding the ratio (pi_theta / pi_theta__old):
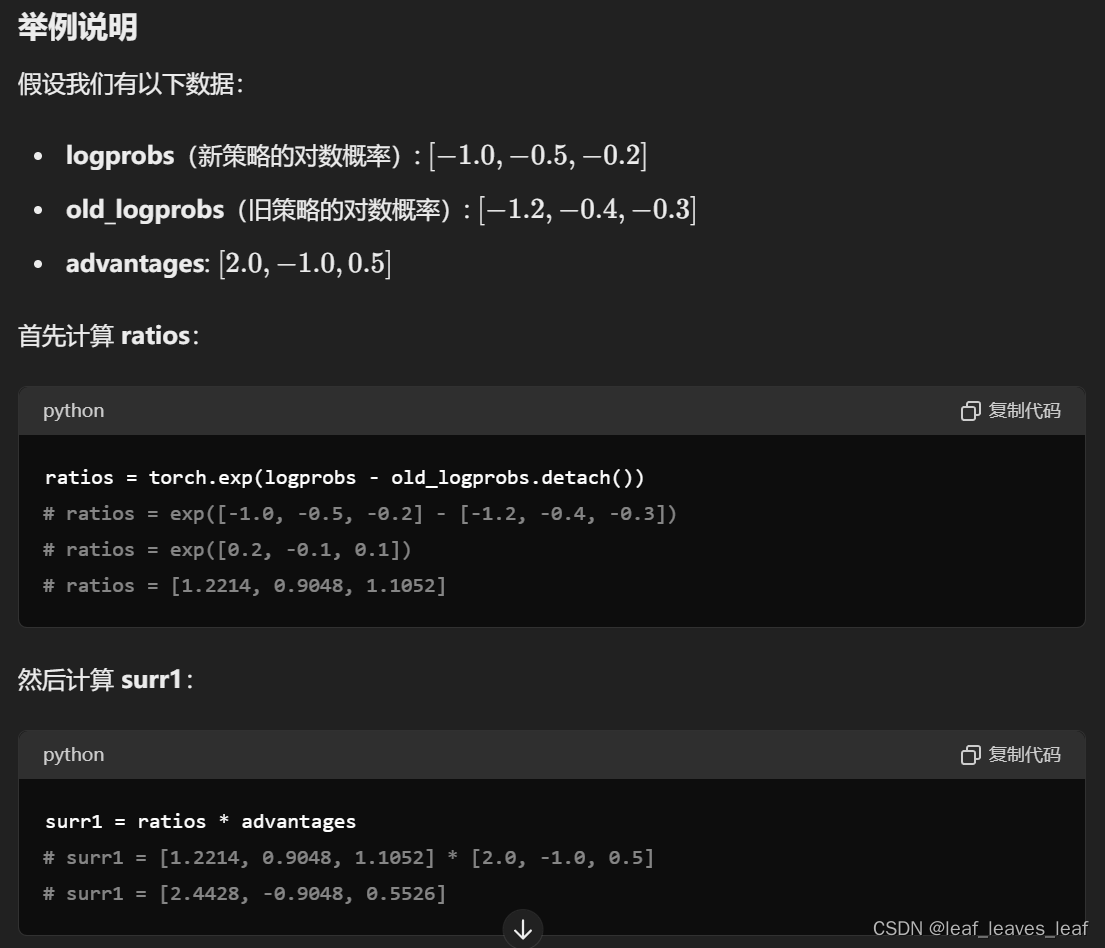
ratios = torch.exp(logprobs - old_logprobs.detach())
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
advantages = rewards - state_values.detach()
advantages = rewards - state_values.detach()



surr1 = ratios * advantages
surr1 = ratios * advantages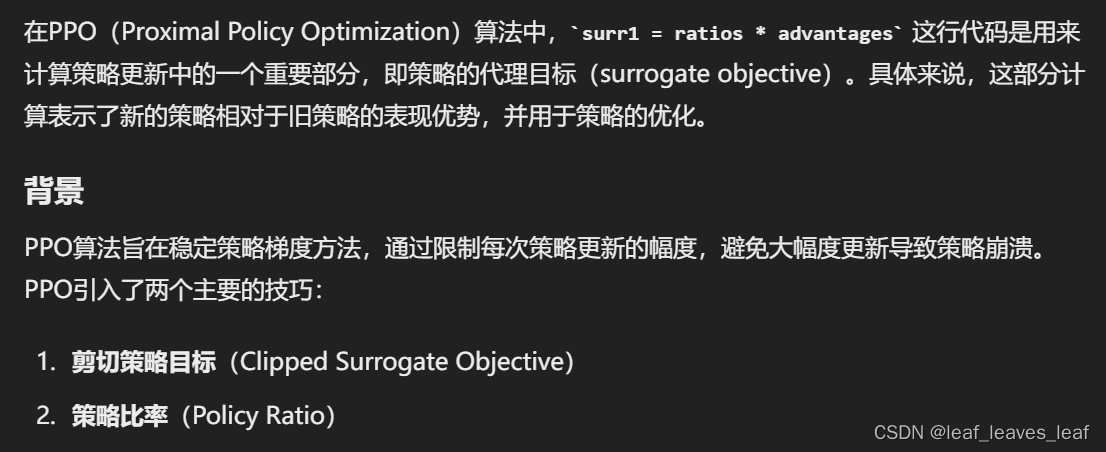

surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages

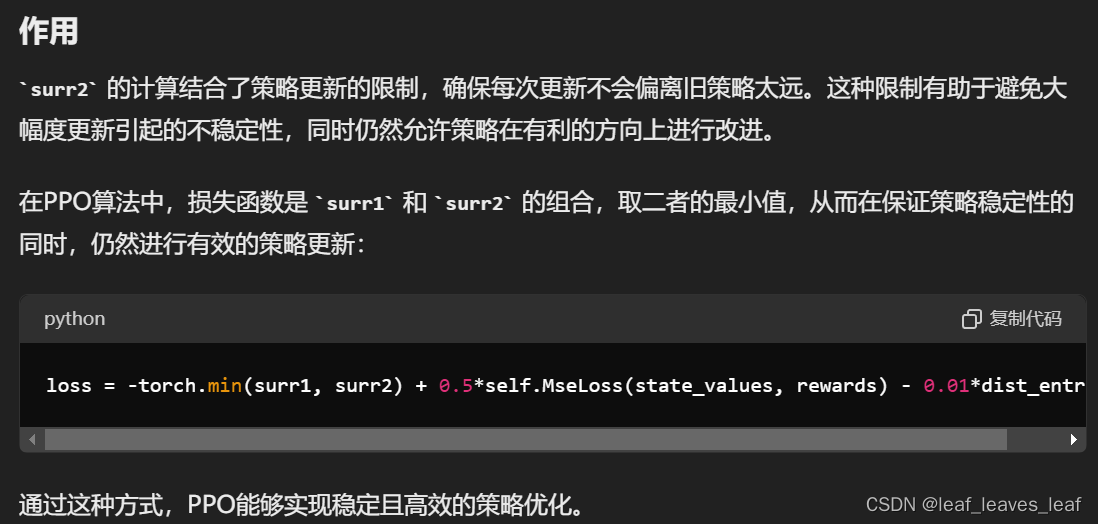
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy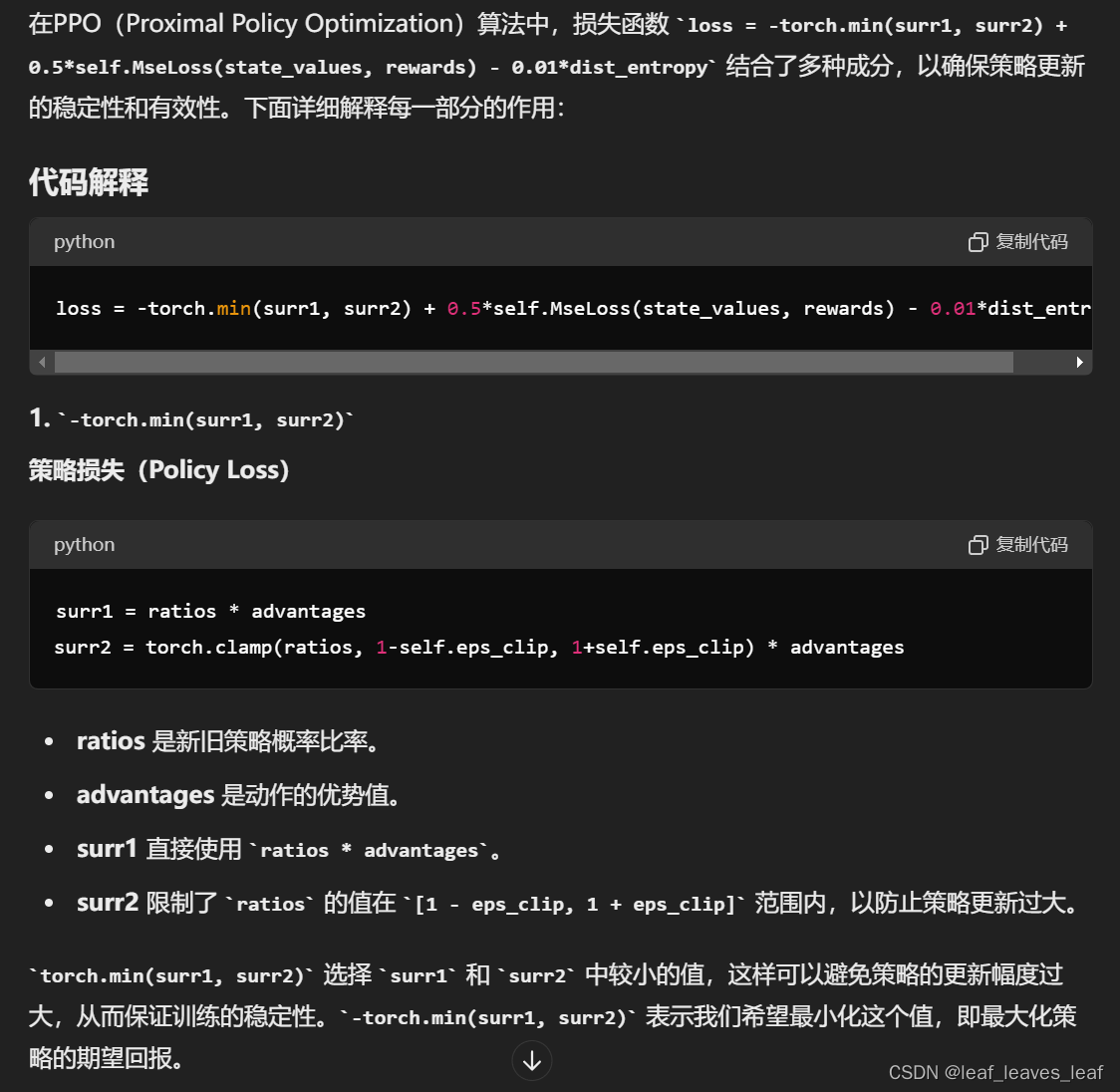



为什么最大化用新旧策略概率比率乘以优势函数,即ratios * advantages这个式子就可以代表最大化收益?

代表策略,某个状态在该策略下选择该动作的概率乘以选择该动作后的收益,最大化这个值。期望E是对一批数据求平均。



详细解释一下上面回答的第一个公式,即策略梯度定理给出的策略参数的梯度形式



详细解释一下0.5*self.MseLoss(state_values, rewards)它的意义



为什么价值网络可以估计在给定状态下,智能体未来能获得的总奖励的期望值,它是怎么估计出来的?




详细解释一下0.01*dist_entropy它的意思



优势函数 A(s,a) 表示在状态 s 下采取动作 a 相对于平均水平的优劣程度。正值表示该动作优于平均水平,负值表示该动作劣于平均水平。为什么state_values可以代表平均水平


V(s)在代码中只是个神经网络呀,输入736个特征,输出一个值,为什么它就是对所有可能动作的期望奖励的估计



PPO的第二项:0.5*self.MseLoss(state_values, rewards),是让状态-动作值函数Q(s,a)接近状态值函数V(s),可是状态-动作值函数Q(s,a)意思是在某个状态 s 下采取动作 a 所能带来的预期奖励,而状态值函数V(s)意思是在状态 s 下采取所有可能动作的平均奖励,这两个不是一个东西呀,为什么损失函数想让他俩越接近越好


状态-动作值函数Q(s,a)意思是采取动作 a 所能带来的预期奖励,而状态值函数V(s)意思是采取所有可能动作的平均奖励,采取的动作都不一样,为什么要让他们接近



状态-动作值函数Q(s,a)意思是采取动作 a 所能带来的预期奖励,而状态值函数V(s)意思是采取所有可能动作的平均奖励,采取的动作都不一样,状态值函数V(s)神经网络的意思是让采取所有可能动作的平均奖励接近采取动作 a 所能带来的预期奖励吗






















 1504
1504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











