







目录
🚩哈希桶实现unordered_set和unordered_map
🚩哈希思想
谈及哈希思想,就不能不谈映射!哈希思想的主要特征就是把分散的数据,经过统一的映射关系进行转化,然后创建一个新的空间,按照映射关系将数据直接存进去,也可能是将数据的一些特征(比如出现的次数)存进去。新的空间更有规律可循,一般按照创建时的映射关系就能很快的实现对某些特定数据的查找。
说来说去,核心思想就两个:映射与转换!
🚩闭散列与开散列
闭散列
所谓闭散列,实际上就是创建一个一维数组。这里会引入一个变量叫装载因子。具体就是数组存的数据个数比上总的空间大小所得的值。一般情况下存的数据越多,越容易出现一种情况:经过哈希函数的映射之后,两个截然不同的数据却指向同一个空间。--哈希冲突
而为了避免哈希冲突,一般我们取负载因子<=0.7,大于0.7的话就对数组进行扩容操作。
这里我们一般是怎么处理的呢?在冲突的位置后面寻找是否有空余的位置,有的话就把冲突的数据存到空余位置。至于怎么找到,当然是可以一个一个的往后排查(线性探测), 也可以跳着查找,比如每次都是i的次方数往后查找(二次探测)。二次探测能够避免数据过分集中。
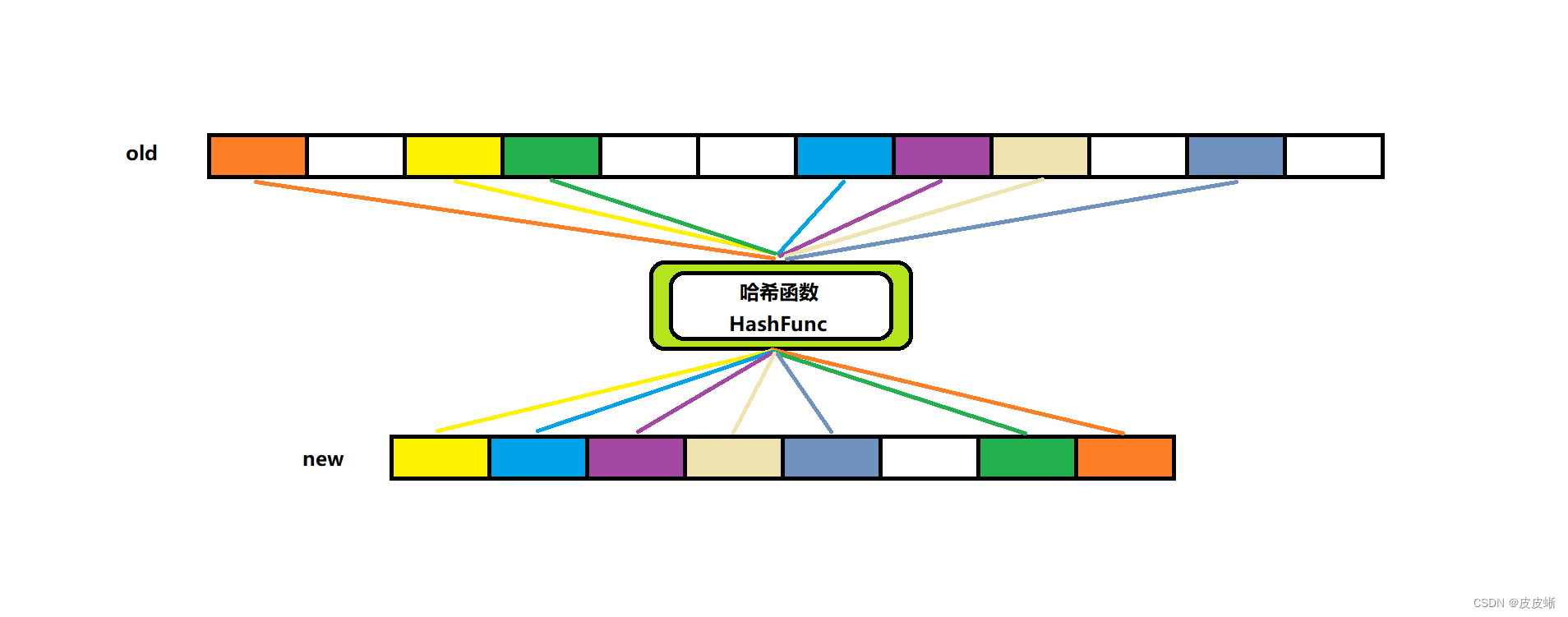
实际上闭散列并不被频繁使用,使用更多的式开散列,也即是哈希桶。这个我们接下来细谈。
开散列(哈希桶)
开散列其实是在闭散列的基础之上进行的改进,原本应该存数据的数组元素现在存的是链表结构。这也就意味着哈希冲突不再是问题。直接用链表链接起来就成。
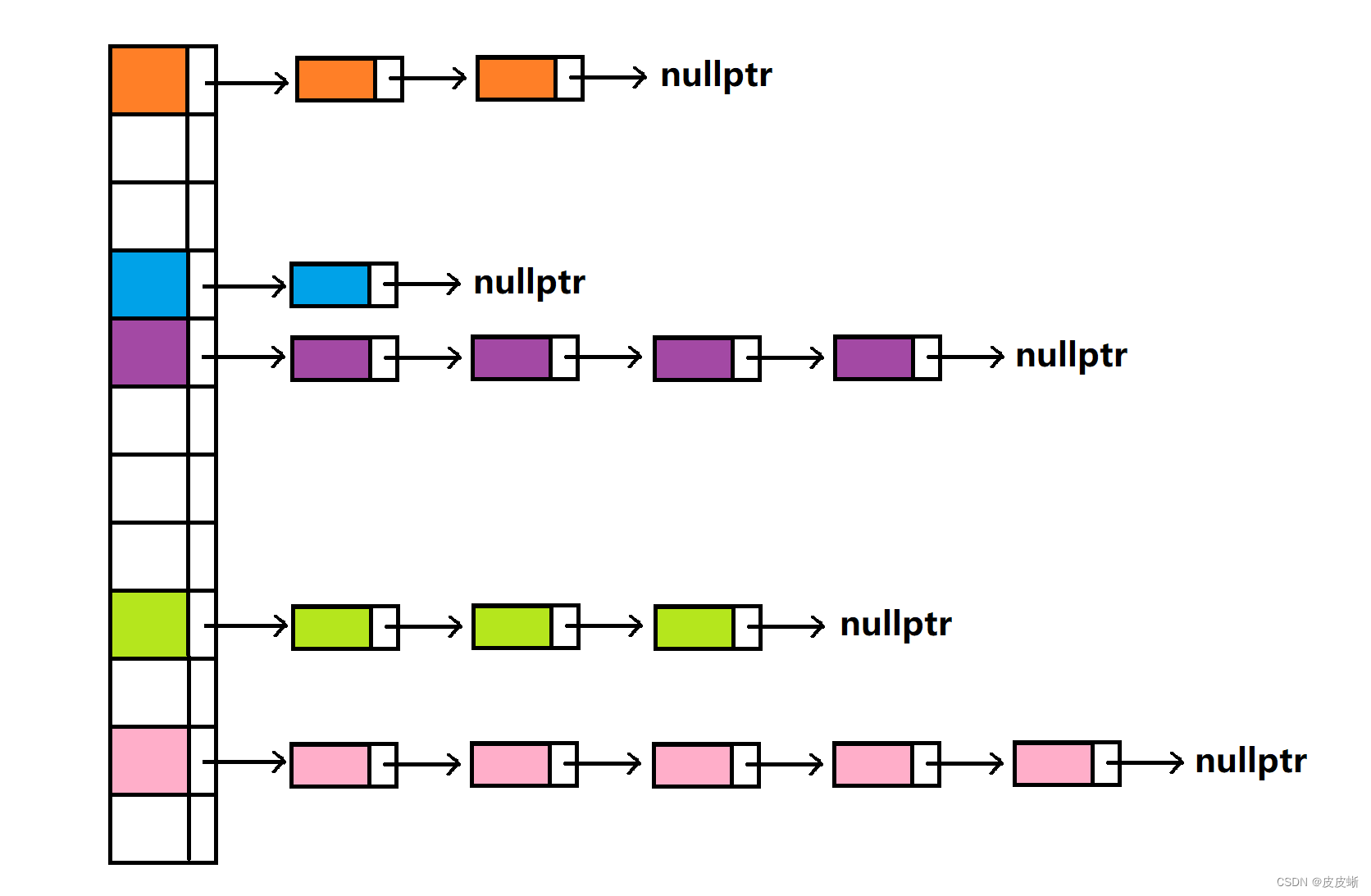
🚩哈希桶的实现
链表节点
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};哈希桶的结构
template<class K,class T,class KeyOfT,class HashFunc>
class HashTable
{
public:
template<class K, class T, class KeyOfT, class HashFunc>
friend class _HSIterator;//方便迭代器调用私有成员_table
typedef HashNode<T> Node;
typedef _HSIterator<K, T, KeyOfT, HashFunc> iterator;//迭代器(先用着,后面实现)
/.../
private:
vector<Node*> _table;//哈希桶主体
size_t _n=0;//有效数据个数
};其中T表示节点数据,KeyOfT是取节点数据中的Key值,是仿函数,方便我们下面实现unordered_map和unordered_set。HashFunc是哈希函数(映射关系转化)。
哈希桶的查找
1.有效数据个数是0,表明哈希桶为空,查找失败。
2.哈希桶不为空,使用哈希函数定位到一条单链表上,在该链表上查找。
iterator Find(const K& key)
{
if (_table.size() == 0)//哈希桶为空
{
return iterator(nullptr, this);
}
KeyOfT kot;
//利用哈希函数取到数据对应的哈希下标
HashFunc hf;
size_t hashi = hf(key);
hashi %= _table.size();
//单链表查找
Node* cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);//找到了,返回迭代器(后面实现)
}
cur = cur->_next;
}
return iterator(nullptr, this);//没找到,空指针构造迭代器
}哈希桶的插入
1.首先判断是否为重复插入数据
2.再看哈希桶是否"满"了,这里的满指的是有效数据个数与哈希桶的主体大小相等。"满"了的话就重新建立一个更大一点的哈希桶,并借助哈希函数来存原来的单链表。最后再交换新旧哈希桶。
3.通过哈希函数(映射关系),找到插入链表的位置,直接进行头插,有效数据个数加一。
pair<iterator, bool> Insert(const T& data)
{
HashFunc hf;
KeyOfT kot;
//避免重复插入
if (Find(kot(data))._node)
{
return make_pair(Find(kot(data)), false);
}
//检查是否扩容
if (_n == _table.size())
{
size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
vector<Node*> newTable;
newTable.resize(newSize, nullptr);
//新旧桶的数据交接
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _table[i];
if (cur)
{
size_t hashi = hf(kot(cur->_data)) % newSize;
newTable[hashi] = cur;
}
_table[i] = nullptr;
}
newTable.swap(_table);
}
//寻找插入位置,进行单链表的头插
size_t hashi = hf(kot(data));
hashi %= _table.size();
Node* newnode = new Node(data);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}哈希桶的删除
1.检查是否为空桶
2.通过哈希函数(映射关系),找到删除链表的位置。
3.进行单链表的节点删除,有效数据个数减一。
bool Erase(const K& key)
{
//检查是否为空桶
if (_table.size() == 0)
{
return false;
}
//哈希函数查找位置
KeyOfT kot;
HashFunc hf;
size_t hashi = hf(key);
hashi %= _table.size();
Node* prev = nullptr;
Node* cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)//单链表头删节点
{
_table[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}哈希桶的析构
除了释放vector这个容器,还要把每个节点的空间给释放了。
~HashTable()
{
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}vector会自动调用自己的析构函,就不用咱们自己写了。
哈希桶的迭代器
结构框架
template<class K, class T, class KeyOfT, class HashFunc>
class _HSIterator
{
typedef HashNode<T> Node;
typedef _HSIterator<K, T, KeyOfT, HashFunc> Self;
public:
Node* _node;
HashTable<K, T, KeyOfT, HashFunc>* _pht;
_HSIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht)
:_node(node)
, _pht(pht)
{}
/.../
};其中_pht是一个哈希桶的指针,之所以需要用到节点所在的哈希桶,是因为在实现++的时候,如果该节点是一个单链表的尾节点,再进行++操作时,就需要找下一个单链表,而这必须要有哈希桶整个数据才行,毕竟哈希桶之间的单链表不一定一个个挨着,不可能像数组那样直接去找下一个位置。这也是为什么上面哈希桶的结构里迭代器会是友元的原因:使用哈希桶的私有成员变量。
operator ++
1.看本节点是否是单链表的尾节点,是的话利用哈希函数和本节点的数据,找到下一个单链表的位置。
2.改变_node的值,使其指向下一个节点。
Self& operator++()
{
//_node非此单链表的尾节点
if (_node->_next)
{
_node = _node->_next;
}
else
{
//找到下一个单链表的位置
KeyOfT kot;
HashFunc hf;
size_t hashi = hf(kot(_node->_data));
hashi %= _pht->_table.size();
++hashi;
//在单链表中查找
for (; hashi < _pht->_table.size(); ++hashi)
{
if (_pht->_table[hashi])
{
_node = _pht->_table[hashi];
break;
}
}
//遍历完了还没找到,_node本身++前就是最后一个数据了,++后赋空值
if (hashi == _pht->_table.size())
{
_node = nullptr;
}
}
return *this;
}operator * 、->、 ==、 !=
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}哈希桶的begin和end
1.对于begin来说,就是找哈希桶的第一个单链表的头节点,然后进行迭代器的构造。
2.从迭代器的++可知,找到的尾的下一个节点是空,因此end直接使用nullptr来进行迭代器的构造。
iterator begin()
{
for (size_t i = 0; i < _table.size(); ++i)
{
if (_table[i])
{
return iterator(_table[i], this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}哈希桶的两种哈希函数
数字类型的哈希函数
template<class K>
struct DefaultHash
{
size_t operator()(const K& key)//仿函数
{
return (size_t)key;
}
};string模板特化的哈希函数
template<>
struct DefaultHash<string>
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash = hash * 131 + ch;
}
return hash;
}
};每次乘以131是大量的测试和数学模型得出,能够最大可能的避免数据不同而hash值相同的情况。除了131,还有其他的一些值也能做到,事实上,如果不是考虑到哈希冲突,随便哪个值都行。
🚩哈希桶实现unordered_set和unordered_map
unordered_set和unordered_map是无序容器,特点就是O(1)的插入和查找,面对大量的数据,这种速度堪称无敌。
代码
template<class K,class HashFunc=DefaultHash<K>>
class Unordered_Set
{
template<class K>
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, SetKeyOfT<K>, HashFunc>::iterator iterator;
pair<iterator,bool> insert(const K& key)
{
return _ht.Insert(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
private:
HashTable<K, K, SetKeyOfT<K>, HashFunc> _ht;
};
/*_________________________________________________________________________________*/
template<class K,class V,class HashFunc=DefaultHash<int>>
class Unordered_Map
{
template<class K,class V>
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& data)
{
return data.first;
}
};
typedef typename HashTable<K, pair<K, V>, MapKeyOfT<K,V>, HashFunc>::iterator iterator;
public:
pair<iterator, bool> insert(const pair<K, V>& data)
{
return _ht.Insert(data);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator find(const K& key)
{
_ht.Find(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
private:
HashTable<K, pair<K, V>, MapKeyOfT<K, V>, HashFunc> _ht;
};上面的模拟实现都是通过哈希桶变量_ht的函数实现的。
🚩总结
哈希思想在处理海量数据极具优越性,往后我会进一步探索哈希的应用。今天咱就只讲一些基础的知识,为以后的拓展做个铺垫。👋

















 7854
7854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









