







RK3588搭建OpenCL环境
一、环境准备
1. OpenCL动态库准备
使用RK官网的ubuntu固件(OK3588 - C_Forlinx_Desktop_20.04),通过RKDevTool_Release_v2.84下载工具将固件安装到板子。在终端使用find指令查找OpenCL库文件:
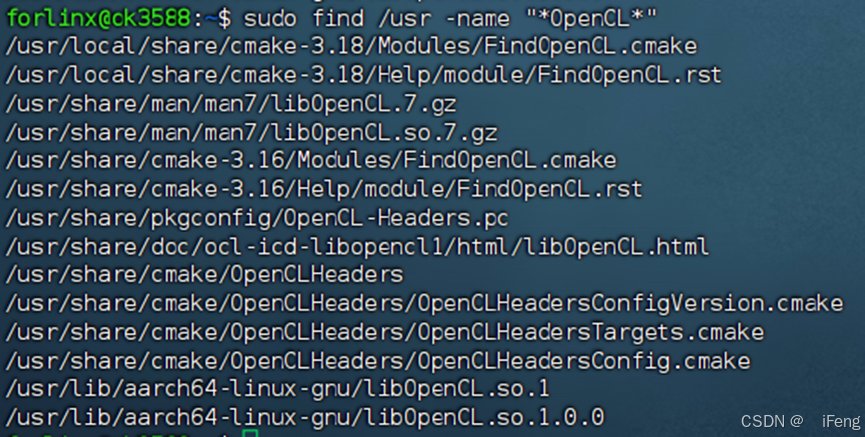
板子中存在多个OpenCL库,实际使用的OpenCL库名字为-lmali(在Windows下指定库名为OpenCL)。
2. OpenCL头文件准备
通过git clone命令克隆OpenCL头文件源码:
git clone https://github.com/KhronosGroup/OpenCL-Headers.git
进入源码目录,使用cmake命令进行编译:
cmake -S. -B build -DCMAKE_INSTALL_PREFIX=/usr
此命令在当前目录(.)下查找CMakeLists.txt文件,并在./build目录下生成Makefile文件。接着在./build目录执行构建操作,仅构建install目标,将生成文件安装到指定位置:
cmake --build build --target install
此时,头文件已安装到/usr/include/CL目录。
二、开始测试
1. 测试代码
测试代码用于计算1024大小的矩阵乘法,对比GPU和CPU的运行速度。代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#include <time.h>
#define MATRIX_SIZE 1024 // 矩阵大小
const char *kernelSource = "__kernel void matrixMultiply(__global float *A, __global float *B, __global float *C) {\n"
" int i = get_global_id(0);\n"
" int j = get_global_id(1);\n"
" if (i < MATRIX_SIZE && j < MATRIX_SIZE) {\n"
" float sum = 0.0f;\n"
" for (int k = 0; k < MATRIX_SIZE; k++) {\n"
" sum += A[i * MATRIX_SIZE + k] * B[k * MATRIX_SIZE + j];\n"
" }\n"
" C[i * MATRIX_SIZE + j] = sum;\n"
" }\n"
"}";
void initializeMatrix(float *matrix, int size, float value) {
for (int i = 0; i < size; i++) {
matrix[i] = value;
}
}
void initializeMatrix_Rand(float *matrix, int size, float value) {
for (int i = 0; i < size; i++) {
matrix[i] = rand()%(int)value;
}
}
void printMatrix(float *matrix, int size) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
//printf("%f ", matrix[i * size + j]);
}
//printf("\n");
}
}
void matrixMultiplyCPU(float *A, float *B, float *C, int size) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
float sum = 0.0f;
for (int k = 0; k < size; k++) {
sum += A[i * size + k] * B[k * size + j];
}
C[i * size + j] = sum;
}
}
}
int main() {
int size = MATRIX_SIZE * MATRIX_SIZE;
float *A = (float *)malloc(size * sizeof(float));
float *B = (float *)malloc(size * sizeof(float));
float *C = (float *)malloc(size * sizeof(float));
float *C_CPU = (float *)malloc(size * sizeof(float));
// 初始化矩阵A和B
initializeMatrix_Rand(A, size, 10.0f); // 所有元素设置为1
initializeMatrix_Rand(B, size, 20.0f); // 所有元素设置为2
initializeMatrix(C, size, 0.0f); // 所有元素初始化为0
initializeMatrix(C_CPU, size, 0.0f); // 所有元素初始化为0
// 打印矩阵A和B
printf("Matrix A:\n");
printMatrix(A, MATRIX_SIZE);
printf("Matrix B:\n");
printMatrix(B, MATRIX_SIZE);
// 设置OpenCL平台和设备
cl_platform_id platform;
cl_device_id device;
cl_int err;
err = clGetPlatformIDs(1, &platform, NULL);
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
// 创建上下文
cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
// 创建命令队列并启用性能计时
cl_command_queue queue = clCreateCommandQueue(context, device, CL_QUEUE_PROFILING_ENABLE, &err);
// 创建程序对象
cl_program program = clCreateProgramWithSource(context, 1, &kernelSource, NULL, &err);
// 编译程序
char options[32];
sprintf(options, "-D MATRIX_SIZE=%d", MATRIX_SIZE);
err = clBuildProgram(program, 1, &device, options, NULL, NULL);
if (err!= CL_SUCCESS) {
// 打印编译错误日志
size_t log_size;
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0, NULL, &log_size);
char *log = (char *)malloc(log_size);
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, log_size, log, NULL);
printf("Build log:\n%s\n", log);
free(log);
return -1;
}
// 创建内核
cl_kernel kernel = clCreateKernel(program, "matrixMultiply", &err);
// 创建缓冲区
cl_mem bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, size * sizeof(float), A, &err);
cl_mem bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, size * sizeof(float), B, &err);
cl_mem bufferC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, size * sizeof(float), NULL, &err);
// 设置内核参数
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);
err = clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);
err = clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);
// 设置工作组大小
size_t global[2] = {MATRIX_SIZE, MATRIX_SIZE};
// 计算GPU时间
cl_event event;
err = clEnqueueNDRangeKernel(queue, kernel, 2, NULL, global, NULL, 0, NULL, &event);
clWaitForEvents(1, &event);
// 读取结果
err = clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, size * sizeof(float), C, 0, NULL, NULL);
// 获取性能计时
cl_ulong time_start, time_end;
clGetEventProfilingInfo(event, CL_PROGRAM_PROFILING_COMMAND_START, sizeof(time_start), &time_start, NULL);
clGetEventProfilingInfo(event, CL_PROGRAM_PROFILING_COMMAND_END, sizeof(time_end), &time_end, NULL);
double gpu_time = (time_end - time_start) * 1.0e-6; // 将纳秒转换为毫秒
// 计算CPU时间
clock_t start = clock();
matrixMultiplyCPU(A, B, C_CPU, MATRIX_SIZE);
clock_t end = clock();
double cpu_time = ((double)(end - start)) / CLOCKS_PER_SEC * 1000; // 将秒转换为毫秒
// 打印结果矩阵C
printf("Matrix C (GPU Result):\n");
printMatrix(C, MATRIX_SIZE);
printf("Matrix C (CPU Result):\n");
printMatrix(C_CPU, MATRIX_SIZE);
// 对比结果
int correct = 1;
for (int i = 0; i < size; i++) {
if (C[i]!= C_CPU[i]) {
correct = 0;
break;
}
}
if (correct) {
printf("Results are correct.\n");
} else {
printf("Results are incorrect.\n");
}
printf("GPU computation time: %f ms\n", gpu_time);
printf("CPU computation time: %f ms\n", cpu_time);
// 清理资源
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
free(A);
free(B);
free(C);
free(C_CPU);
return 0;
}
2. 测试结果
arm_release_verof thislibmaliisg6p0 - 01eac0,rk_so_veris6。- Results are correct.
- GPU computation time: 982.265193 ms
- CPU computation time: 53531.447000 ms

















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









