







我认为我们在针对一个问题的时候的思路应该如下:
使用5W2H方法论来分析定位问题。
what? 问题是什么?
who? 谁引起的?
when?什么时候发生的?
where? 哪里出现了问题?
why? 分析原因为什么导致的?
how much? 消耗了多少资源 损失了多少?
how to do?该去怎么解决
包括我在前期问题分析甚至到后面问题解决之后的复盘报告的总结都是根据以上的思路去构建整体的思维逻辑架构的
cpu利用率反应的是当前时间cpu使用的实时百分比。
负载是一段时间内正在使用或等待使用的cpu的平均任务,它是用来反应cpu的繁忙程度的
cpu利用率高,负载会变高,但负载高,cpu利用率不一定高
在linux系统中可以使用top命令或者uptime来查看cpu的平均负载
就拿top命令来打比方
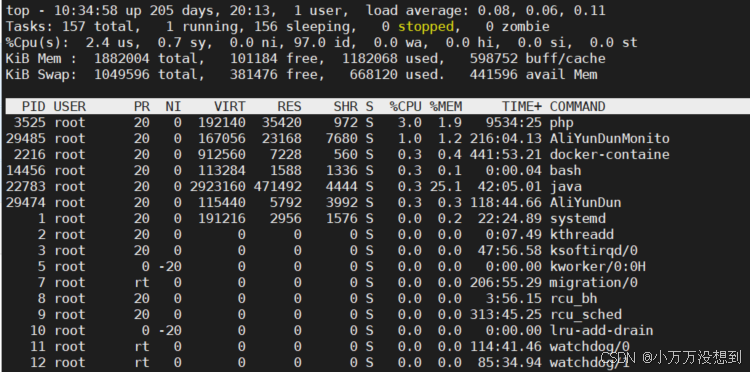 第一行就可以看到目前该服务器运行的时间,几个用户登入,load average平均负载
第一行就可以看到目前该服务器运行的时间,几个用户登入,load average平均负载
这里显示的是一分钟五分钟15分钟的平均负载 一般可以通过15分钟的平均负载来分析整个系统目前的性能和压力
负载可以用来衡量服务器的抗压能力
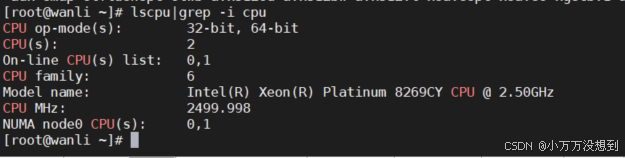
使用lscpu查看cpu的核心数 可以看到我这个cpu核心数是2核理论上负载小于2是可以承受的
所以我这里负载才0.11是完全可以接受的,说明目前系统性能是好的
![]()
uptime命令也可以查看系统的load average
前面提到了负载高,cpu利用率不一定高。这是因为决定系统负载的不知有cpu利用率这一个因素
决定系统负载的因素有:cpu利用率,磁盘io,内存使用率,网络带宽,用户的访问量
所以要分析一个系统,可以根据这些量化的数据来判断
磁盘io 使用iostat -x 查看当前磁盘的io使用情况

查看到%util来分析磁盘io是否过高,磁盘读写速度多少,然后可以配合iotop来具体定位分析是哪个操作导致的磁盘io过高
cpu使用率
可以使用top命令 shift+p 可以降序的查看具体是哪个经常占用了cpu过长时间
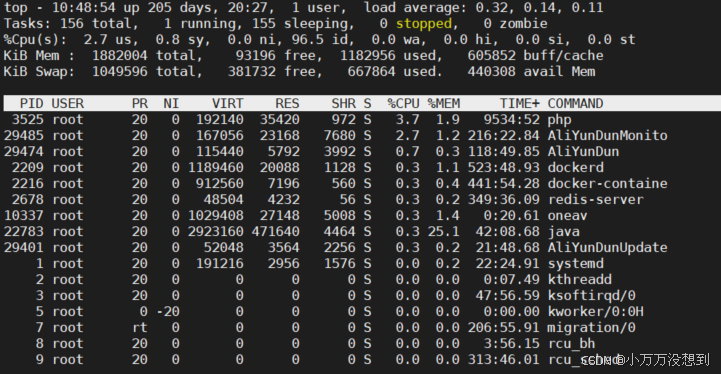
top命令是万能的什么都能查,可以查看当前运行的总进程的个数,僵尸进程,暂停的进程的个数
这里的僵尸进程可以重点说一下: 一般情况下子进程结束之后会返回一个状态码,父进程会调用wait()函数去读取该状态码来回收掉进程
僵尸进程就是父进程没有来及调用wait函数去回收子进程导致子进程出现无法被系统回收的问题。解决办法可以重启或者ps aux|grep "Z" 查看僵尸进程并杀掉她的父进程使该进程归init进程管,init进程调用wait()函数去回收其资源。
cpu使用率还有多少空闲的%idle,内存使用率,free多少 used多少,交换空间swap的使用率以及还有多少free的,used多少
同时ps命令有的top也都有
(PID)展示进程id (USER)用户属主 (PR)priority优先级 (NI)Nice值 (VIRT) virtual 虚拟内存大小
(RES) 物理内存大小 (SHR) share 共享内存大小
(S) Status 状态 (%cpu) cpu使用率 (%mem)内存使用率 (Time)运行时间 (Command)运行的命令
cpu使用率其实就是比如100ms中A进程占用了cpu10ms,B进程占用了cpu30ms,cpu空闲时间60ms,那这段时间内cpu的使用率就是40% 反应cpu被占用被使用的情况的实时百分比的
网络 使用speedtest进行网络测试测试服务器上传下载速度 (pip install speedtest-cli)

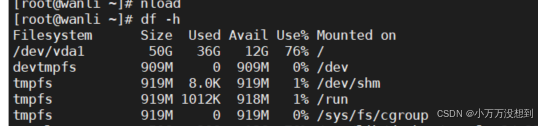
使用nload可以查看网络带宽 yum install -y nload
查看磁盘的使用情况是否磁盘空间不足?
df -h
如果系统负载高了怎么解决?
1. 避免单点单台server提供服务,使用多台跑着同样的业务代码的server作为分布式集群,前面定义负载均衡将用的流量分散到后端的服务集群中来提高整个系统的负载,当这个系统的复杂过高时,可以对后端的服务集群进行水平扩展,当服务集群中的某一台机器负载过高时,可以配置负载均衡算法将流量分散到其他的机器上或者垂直扩展提高单台机器整体的性能。
2. 提高网络带宽,这样可以有效的提高服务的响应速度
3. 优化程序代码,减少程序代码中不必要的资源浪费,做好异常处理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









