






1.项目背景:
在线旅游平台已成为我们规划旅行的重要工具。去哪儿网作为国内领先的在线旅游平台之一,提供了丰富的旅游攻略和用户反馈,为我们的研究提供了宝贵的数据资源。
2.项目需求:
在去哪儿旅行官网使用Python爬虫技术爬取攻略数据,并保存到本地,对CSV文件里的数据进行可视化分析,并写一份数据分析报告
3.项目目的:
市场趋势分析:通过采集和分析去哪儿网上的旅行攻略数据,了解当前旅游市场的趋势和用户偏好,为旅游企业提供市场策略的参考依据 用户行为研究:
分析用户在选择旅游目的地、旅游方式、旅游时间和旅游消费等方面的偏好,以便更好地理解消费者需求
旅游攻略推荐:利用数据分析结果,为用户提供个性化的旅行攻略和建议,帮助用户规划更合理、更有趣的旅行行程
4.项目范围:
数据集 :来 自 对 去 哪 儿 官 网 旅 游 攻 略 的 数 据 采 集
时间范围 : 2024年1月份到10月份
5.技术栈:
工具和库:Pycharm和Edge浏览器驱动
模块和库:os,用于操作文件系统;threading,用于创建多线程;pandas,用于数据处理和CSV文件的读写;selenium,用于Web自动化测试;Xpath,提取网页中数据元素;matplotlib,设置图形参数,以支持中文显示和负号显示;Pyrcharts,数据可视化分析
6.数据分析部分:
6.1 设计思路:
-
数据预处理:1.将采集到的数据转换成DataFrame数据结构,方便后续处理。2.去除重复数据、处理缺失值、处理异常值等 3.对不符合分析需求的字段进行格式转换,例如将文本型数据转换为数值型数据
-
文本处理:对景点的简介文本进行自然语言处理,提取关键词并进行频次统计和词云展示,以了解旅游景点的特征和主题
-
数据可视化:应用柱状图、饼图等图表展示数据分析结果,如热门目的地Top10及其人均费用、出游的结伴方式等
6.2 主要代码:
6.2.1 数据预处理
mport pandas as pd
import matplotlib.pyplot as plt
#%%
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#%%
df = pd.read_csv('travel_data.csv')
df
#%%
#填充缺省值
# 查看缺失值
df.isnull().sum()
# 填充缺省值
df['出行类型'] = df['出行类型'].fillna('风景 美食')
df['行程'] = df['行程'].fillna('自驾游')
#查看填充后的缺失值
df.isnull().sum()
#%%
# 查看重复数据
df.duplicated().sum()
duplicate_data = df[df.duplicated()]
duplicate_data
#%%
df.to_csv('travel_data_clean.csv', index=False)这段代码的主要功能是:
-
导入必要的库以进行数据处理和可视化。
-
设置绘图时的中文显示参数。
-
从CSV文件中读取旅行数据。
-
处理数据中的缺失值,使用指定的默认值进行填充。
-
检查并识别数据中的重复项。
-
将处理完成的数据保存为新的CSV文件
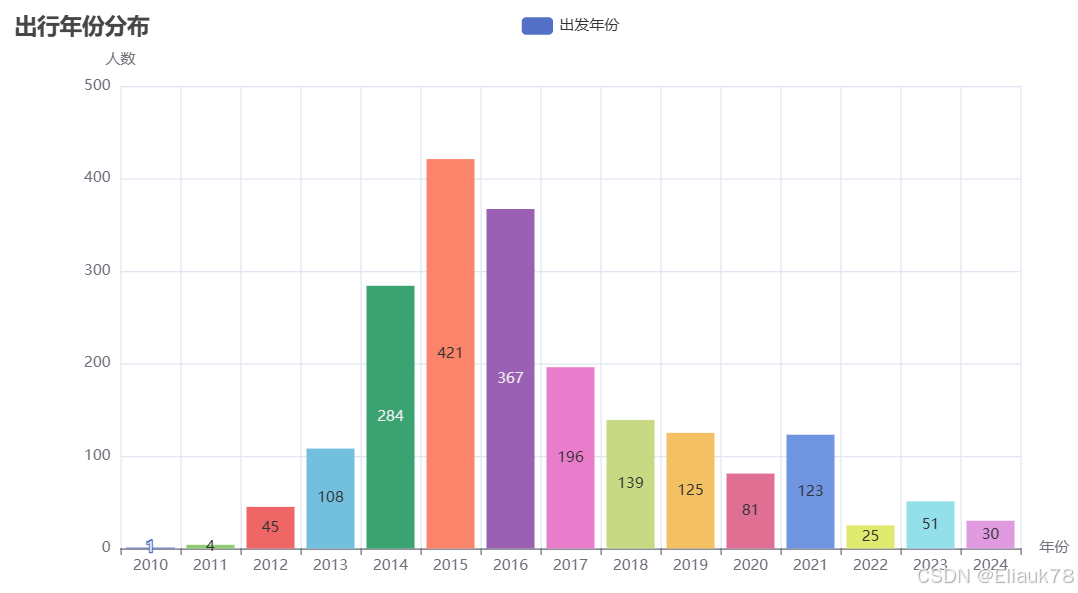
6.2.2 出发日期年份分布
df['出发日期——年'] = df['出发日期'].str.split('-').str[0].astype('int')
df['出发日期——月'] = df['出发日期'].str.split('-').str[1].astype('int')
df
#%%
# 天数处理
df['天数'] = df['天数'].str.replace('共','').str.replace('天','').astype('int')
df
#%%
# 出发日期_年份分布
bar1 = Bar()
# 对年份进行排序,并获取排序后的年份和对应的计数
sorted_years = df['出发日期——年'].value_counts().sort_index()
sorted_years_list = sorted_years.index.tolist()
sorted_counts_list = sorted_years.values.tolist()
# 添加 x 轴数据
bar1.add_xaxis(sorted_years_list)
# 定义颜色列表
colors = [
"#5470C6", "#91CC75", "#EE6666", "#73C0DE", "#3BA272",
"#FC846B", "#9A60B4", "#EA7CCC", "#C7DA83", "#F3C063",
"#E06F94", "#6F94E0", "#E0EA6F", "#94E0EA", "#E09AE0"
]
# 添加 y 轴数据,并为每个柱子设置颜色
bar1.add_yaxis(
series_name="出发年份",
y_axis=sorted_counts_list,
itemstyle_opts=opts.ItemStyleOpts(
color=JsCode(
f"""
function(params) {{
var colorList = {colors};
return colorList[params.dataIndex % colorList.length];
}}
"""
)
)
)
# 设置全局选项
bar1.set_global_opts(
title_opts=opts.TitleOpts(title='出行年份分布'),
xaxis_opts=opts.AxisOpts(name="年份"), # 设置 x 轴名称
yaxis_opts=opts.AxisOpts(name="人数") # 设置 y 轴名称
)
# 渲染图表到 HTML 文件
bar1.rendern('出行年份分布.html')该代码的主要功能是处理并可视化出发日期的数据。首先,它将出发日期字符串分解为年份和月份,并将天数数据转化为整数。接下来,通过对年份数据进行计数和排序,创建了一个动态的柱状图,展示不同年份出行的人数分布。最终,它通过设置图表的各种参数并将其渲染为 HTML 文件,使得数据可视化结果可以被共享和展示。
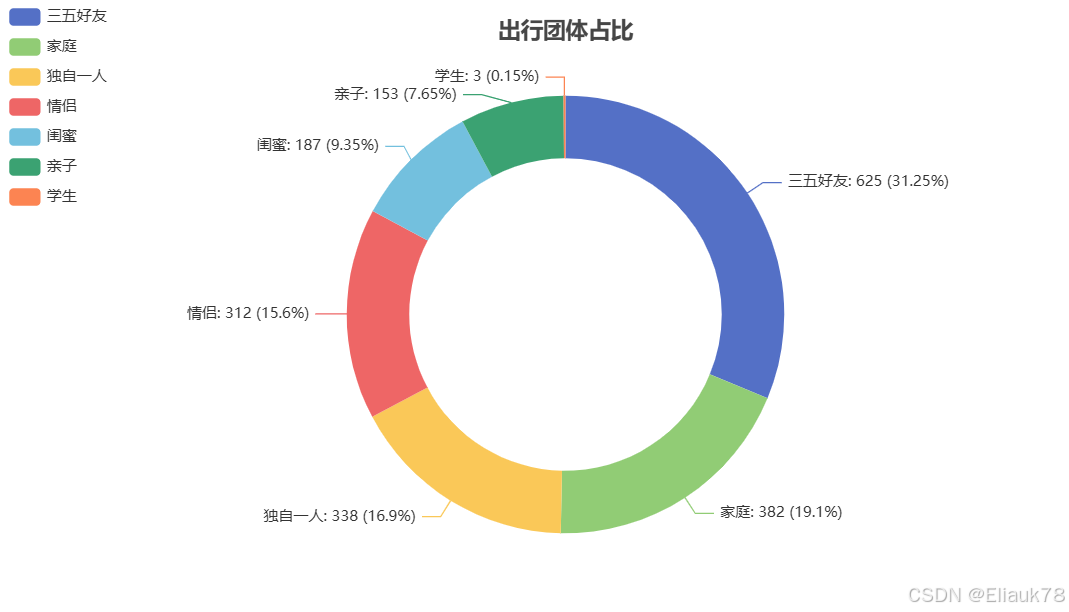
6.2.3 团队出行占比
# 出行团体占比
x_data = df['出行团体'].value_counts().index.tolist()
y_data = df['出行团体'].value_counts().values.tolist()
(
Pie()
.add(
series_name="出行团体",
data_pair=[list(z) for z in zip(x_data, y_data)],
radius=["50%", "70%"],
label_opts=opts.LabelOpts(is_show=True, position="outside", formatter="{b}: {c} ({d}%)"),
)
.set_global_opts(
legend_opts=opts.LegendOpts(pos_left="legft", orient="vertical"),
title_opts=opts.TitleOpts(title="出行团体占比", pos_top='2%', pos_left="center"),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
.render("出行团体占比.html")
)这段代码的主要功能是利用 Python 的可视化库(如 pyecharts)生成一个饼图,展示不同出行团体的数量占比。通过对数据源的处理,代码首先提取出行团体的名称和对应的计数,然后创建饼图并设置样式选项,最后将图表输出为 HTML 文件,方便查看和分享。
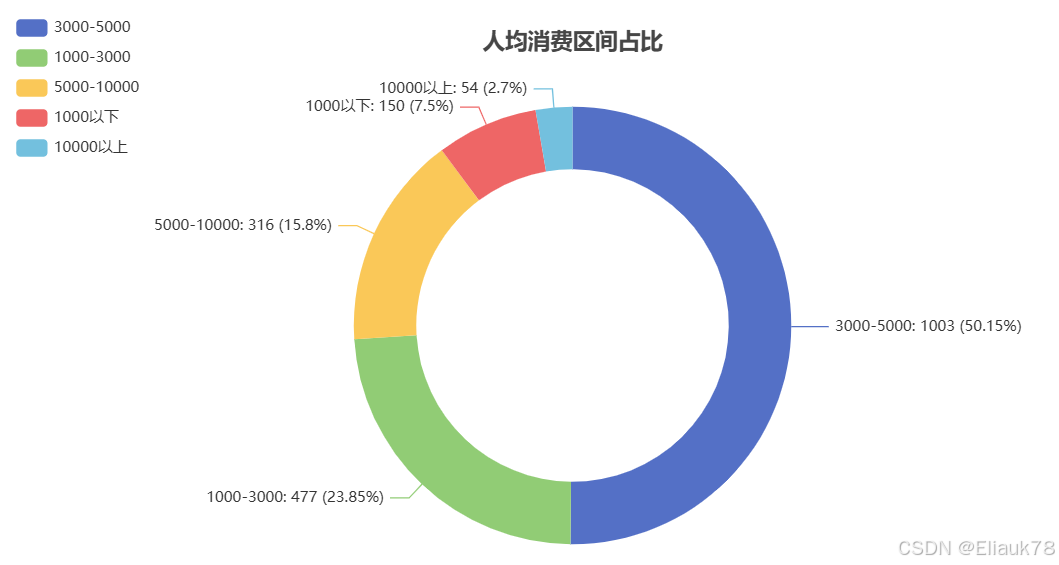
6.2.4 人均消费分布
# 人均消费分布
x_data = df['人均消费分类'].value_counts().index.tolist()
y_data = df['人均消费分类'].value_counts().values.tolist()
(
Pie()
.add(
series_name="消费区间",
data_pair=[list(z) for z in zip(x_data, y_data)],
radius=["50%", "70%"],
label_opts=opts.LabelOpts(is_show=True, position="outside", formatter="{b}: {c} ({d}%)"),
)
.set_global_opts(
legend_opts=opts.LegendOpts(
pos_left="legft",
orient="vertical"
),
title_opts=opts.TitleOpts(title="人均消费区间占比", pos_top='2%', pos_left="center"),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# label_opts=opts.LabelOpts(formatter="{b}: {c}")
)
.render("人均消费区间占比.html")
)
这段代码的主要功能是基于给定的数据集“df”,统计并展示“人均消费分类”的分布,通过pyecharts库生成一个美观的环形饼图,同时将该饼图保存为HTML格式,方便后续数据可视化分析和展示。
6.2.5 词云分布
# 旅游地词云图
x_data = df['首经地址'].value_counts().index.tolist()
y_data = df['首经地址'].value_counts().values.tolist()
words = [list(z) for z in zip(x_data, y_data)]
(
WordCloud()
.add("",words,word_size_range=[10,50])
.set_global_opts(
title_opts=opts.TitleOpts(
title='旅游地点词云',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='c', font_size=20)
),
)
.render("旅游地点词云.html")
) 这段代码的主要功能是根据旅游地点及其出现频次生成一个互动词云图。首先,代码通过 zip 函数将地点和频次结合起来,并使用 WordCloud 的实例创建词云。接着,通过设置标题及其样式,确定了词云的展示方式。最后,词云被渲染并保存为一个 HTML 文件,便于后续查看和分享。这种可视化方式可以让用户直观地了解不同旅游地点的受欢迎程度。
7.分布图效果展示:
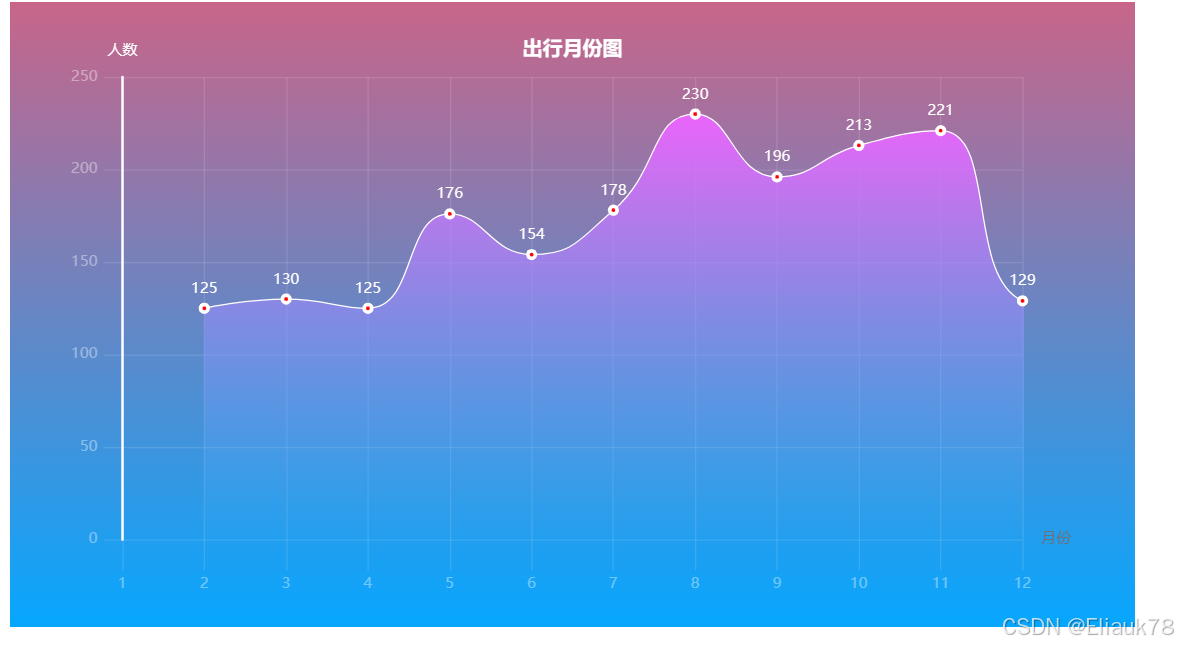

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









