







目录
3.可用性通用场景Availability General Scenario
4.可用性战术Tactics for Availability
0.前言
本系列文章旨在软件设计与体系结构的知识点,资料来源四川大学授课内容,可用于期末复习,笔者理解尚浅,文中不正之处静待批正。加粗部分为重点。
1.Introduction
Availability = reliability + recovery可用性 = 可靠性 + 恢复
可用性的定义:可用性是指系统可供使用的能力,尤其是在发生故障后的可用性
- Availability and security:拒绝服务攻击的明确目的是使系统无法使用
- Availability and performance:当系统响应慢得离谱时,它就不可用了
故障Failure意味着系统或人类在环境中观察到的可见性
故障的原因称为错误fault
关注点:如何检测系统故障;系统故障发生的频率;故障发生时会发生什么;允许系统停止运行多长时间;如何预防故障
例子:心跳监控器确定服务器在正常运行期间没有响应。系统会通知操作员,并在不停机的情况下继续运行
可用性可以被计算:
Availability = MTBF / ( MTBF + MTTR)
MTBF 是平均故障间隔时间;MTTR 是平均修复时间
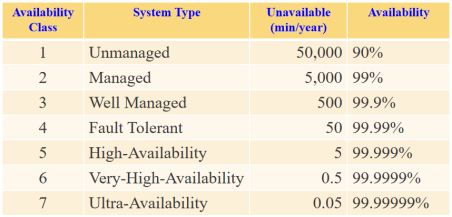
High Availability要达到99.999%
2.规划故障Planning for Failure
故障都是不可避免的
危害分析Hazard Analysis:是一种尝试对系统运行过程中可能发生的危害以及危害发生频率进行编目的技术
故障树分析Fault tree analysis(FTA):是一种分析技术,它指定了对安全性或可靠性有负面影响的系统状态,然后分析系统的背景和运行情况,找出可能出现不希望出现的状态的所有方式。(使用图形结构)
故障树不仅适用于静态分析,还适用于动态分析
3.可用性通用场景Availability General Scenario
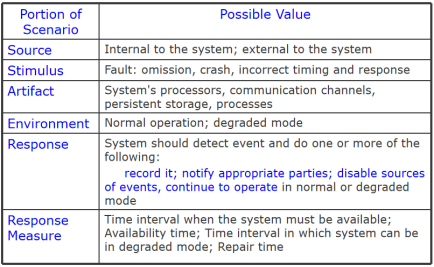
- Omission忽略:组件未能对输入做出响应
- Crash:组件反复出现遗漏故障
- Incorrect timing:组件做出响应,但响应过早或过迟
- Incorrect response:组件响应的值不正确
例子:

心跳监控器确定服务器在正常运行期间没有响应。系统会通知操作员,并在不停机的情况下继续运行。
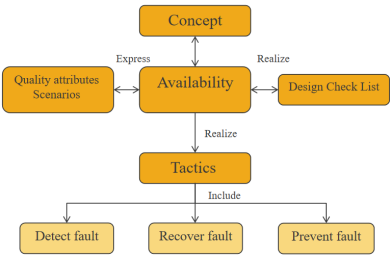
4.可用性战术Tactics for Availability
4.1 可用性战术的目的:可用性策略将防止故障演变为故障,或至少限制故障的影响,并使修复成为可能
4.2 可用性质量属性的战术分类:
- Fault Detect ——健康监测以检测故障
- Fault Recovery ——检测到故障时进行恢复
- Fault Prevention ——防止故障变为故障
所有可用性战术都涉及协调模型coordination model,因为协调模型必须了解发生的故障,才能做出响应
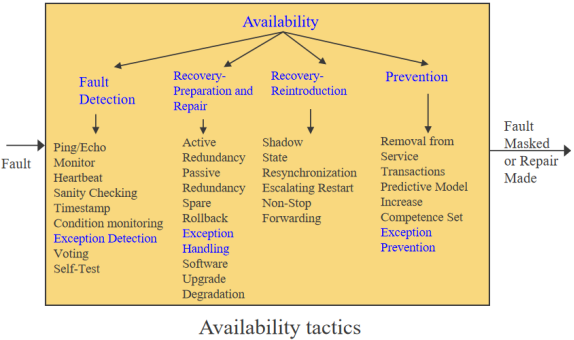
4.3 故障检测Fault Detection
ping/echo:节点之间交换的异步请求/响应信息对;用于确定相关网络路径的可达性reachability和往返延迟round-trip delay;ping/echo需要一个时间阈值;战术采取主动模式,类似于课程中的考勤
Heartbeat:一种故障检测机制,在系统监视器和被监视进程之间采用周期性的信息交换
Heartbeat也可以携带数据;策略采取被动模式passive mode,类似于听到报告hear report
Monitor:监控器是一个组件,用于监控系统其他各部分的健康状态:处理器、进程、I/O、内存等。
系统监控器可检测网络或其他共享资源的故障或拥塞,如来自拒绝服务攻击的故障或拥塞。
Sanity checking(正常性检查)检查组件特定操作或输出的有效性或合理性。
这种策略通常基于对内部设计的了解
例如 :int Get_Human_Temperature() 的限制范围为 33℃ - 45℃
Voting基于冗余
这一策略最常见的实现方式被称为三重模块冗余(TMR)
面对不一致性,投票者会报告故障,并决定使用哪种输出,如多数决制或平均值
Voting可细分如下:
Replication用于检查随机硬件错误,相同的输入和输出
Functional redundancy检查模型模式故障,相同输入、不同算法和相同输出
Analytic redundancy(最难实现),不同输入,复杂输出
异常检测Exception detection是指检测改变正常执行流程的系统条件。
该策略可细化如下:
系统异常System exceptions,如除以零
参数栅栏The parameter fence包含先验数据模式,如 0xDEADBEFF
参数类型Parameter typing 检查类型-长度-值(TLV)、强类型
Timeout超时检查
4.4 故障恢复Fault Recovery
故障恢复包括恢复准备和系统修复两部分。
恢复准备Preparing for recovery包括主动冗余、被动冗余、备用和异常处理等。
重启Reintroduction包括阴影、状态重新同步、升级重启和不间断转发(NSF)等。
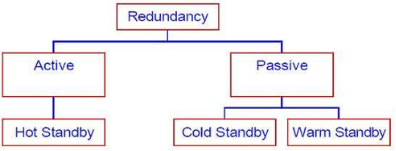
①主动冗余Active redundancy:所有冗余组件并行响应事件,通常只需几毫秒
②被动冗余Passive redundancy: 一个组件(主组件)对事件做出响应,并通知其他组件(备用组件)必须进行的状态更新,通常可限制在几秒钟内
③空闲Spare:故障发生时,备用机必须重新启动到适当的软件配置,并初始化其状态,通常为几分钟
④检查点/回滚Checkpoint/rollback:检查点是定期或针对特定事件创建的一致状态记录
⑤异常处理Exception Handling:一旦检测到异常,系统必须以某种方式进行处理
⑥状态重新同步State resynchronization: 被动和主动冗余策略要求被恢复的组件在恢复服务前升级其状态
⑦软件升级Software upgrade:其目标是以不影响服务的方式实现可执行代码映像的在役升级
有三种实现方法:
- 功能补丁Function patch (错误修复)
- 类补丁Class patch (错误修复)
- 无影响服务Hitless in-service (新特性和功能)
4.5 故障预防
系统可以从一开始就防止故障发生
有五类策略:
①停止服务Removal from service:将系统的一个组件从运行中移除,以进行一些活动,防止出现预期的故障(比如重启一个组件,以防止内存泄漏导致故障)
②交易Transactions:事务语义可确保分布式组件之间交换的异步消息具有原子性、一致性、隔离性和持久性(ACID)
③预测模型Predictive model:监控系统进程的健康状态,以确保系统在额定运行参数范围内运行(会话建立率、进程的维护统计)
④预防异常Exception prevention:为防止系统异常发生而采用的技术
⑤提高能力Increase competence set


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











