







1.高斯分布推导得最小二乘法、
高斯分布:由u和sigma决定,u决定其横坐标的位置,sigma决定其峰值的高低,sigma越大表示标准差越大,说明分布越散,峰值也就越低,同理标准差越小分布越集中,峰值越高。
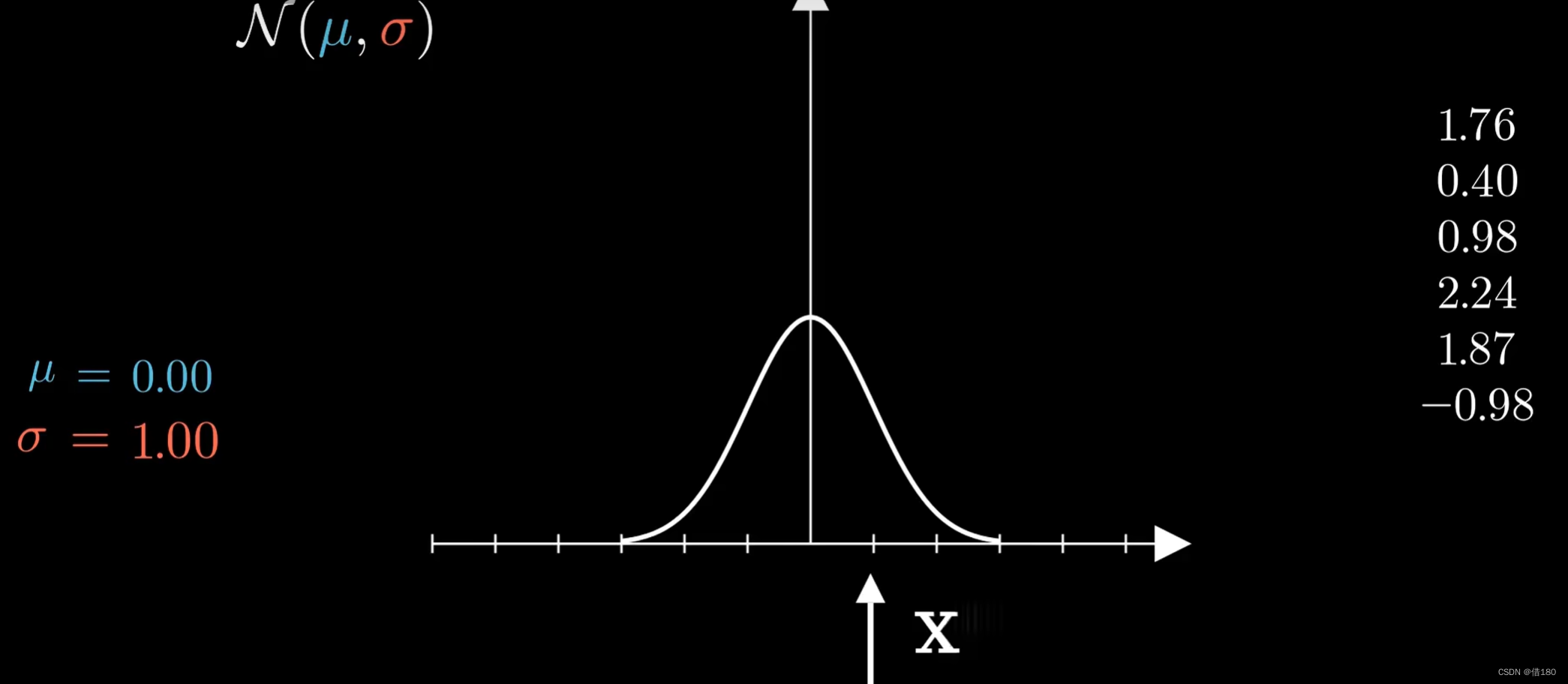
因为概率密度函数给出了相应值的概率,我们就可以按照分布对数据进行采样,每个数据点的采样互不影响,且都是从同一个分布中采样而来的。这样的采样结果我们称为独立同分布的数据,(独立同分布很重要,是大部分算法模型的重要假设)。
那么将问题反过来:有一组采样数据来自于同一个高斯分布,如何确定这些数据是具体来自于下面的哪一个高斯分布呢?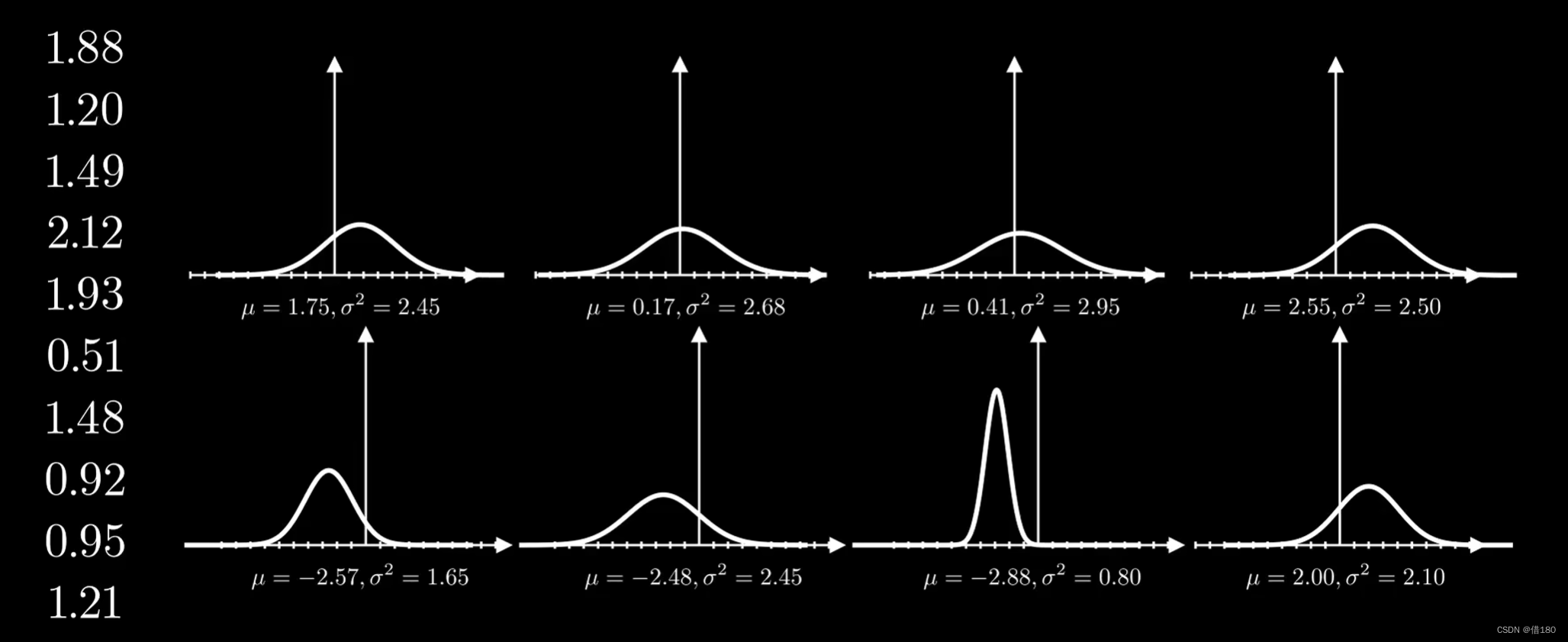
其实任何参数的高斯分布都能取到上述数据,区别只是概率大小。那么,我们想知道的是哪一个高斯分布使得上述的数据出现的概率最大,每一个数据被采样的概率都可以写成一个条件概率的形式,其中u和sigma都是一样的,同时他们相互独立。所以同时出现的概率也就是联合概率,概率的连乘。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









