






给定一个线性变换,不管经过多个线性变换,最终只能解决线性问题,那么这时需要在线性单元后加上一个非线性单元的函数,这类似于高中学过的神经元。因此这样的函数被称为激活函数(必须为非线性函数)。
而且激活函数必须可导,而且x取值范围必须是R应该是单调递增的s型曲线。
下面是常用的激活函数:
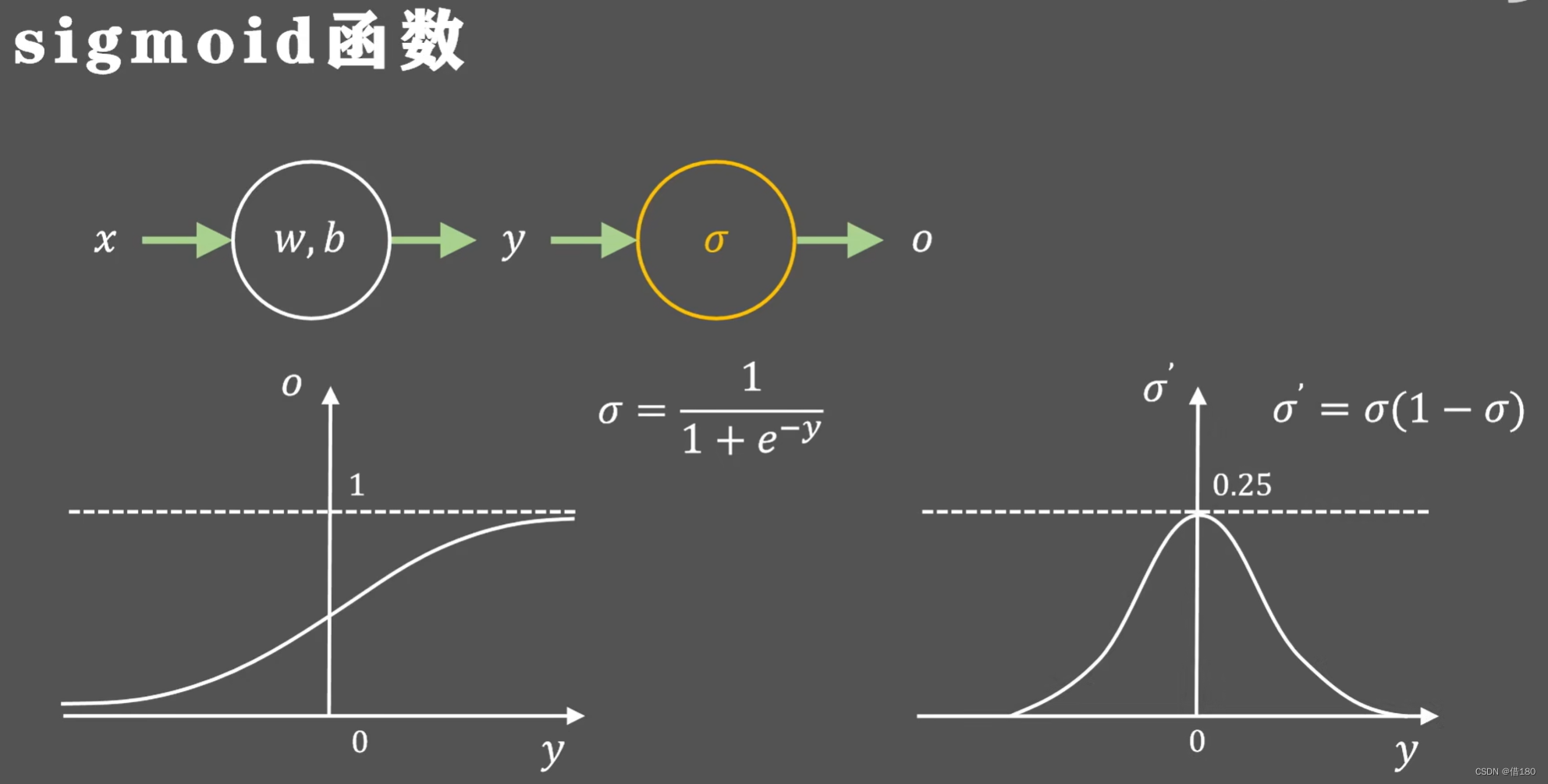
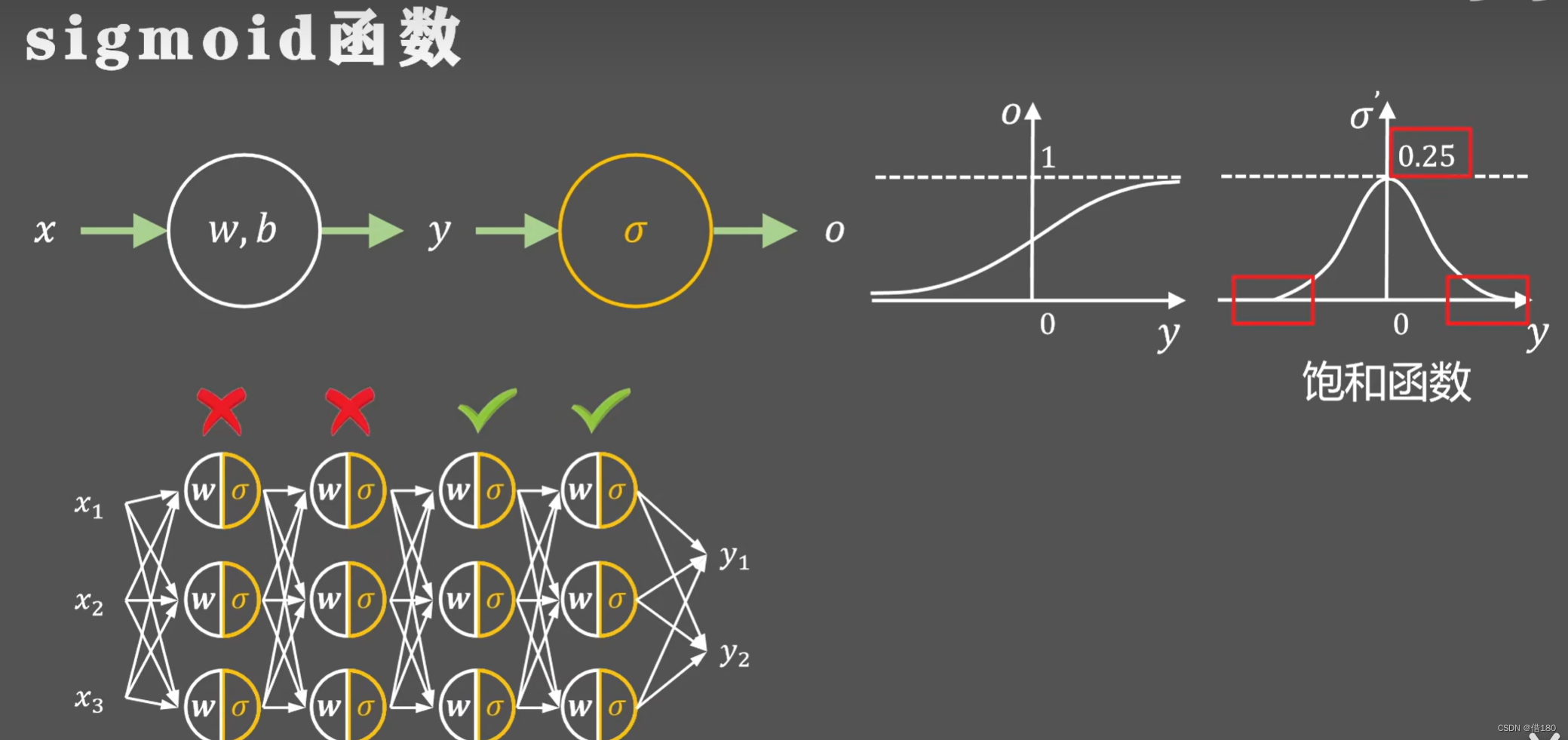
会有梯度消失现象,且导数最大值为0.25,这表示反向传播时,每层梯度会递减大概0.25。这会导致当网络层数很多或某层出现极端的输出反向传播的链式法则时会导致前几层的梯度几乎为0,参数不会更新。这里的四层网络等价于两层网络。这被称为梯度消失现象。
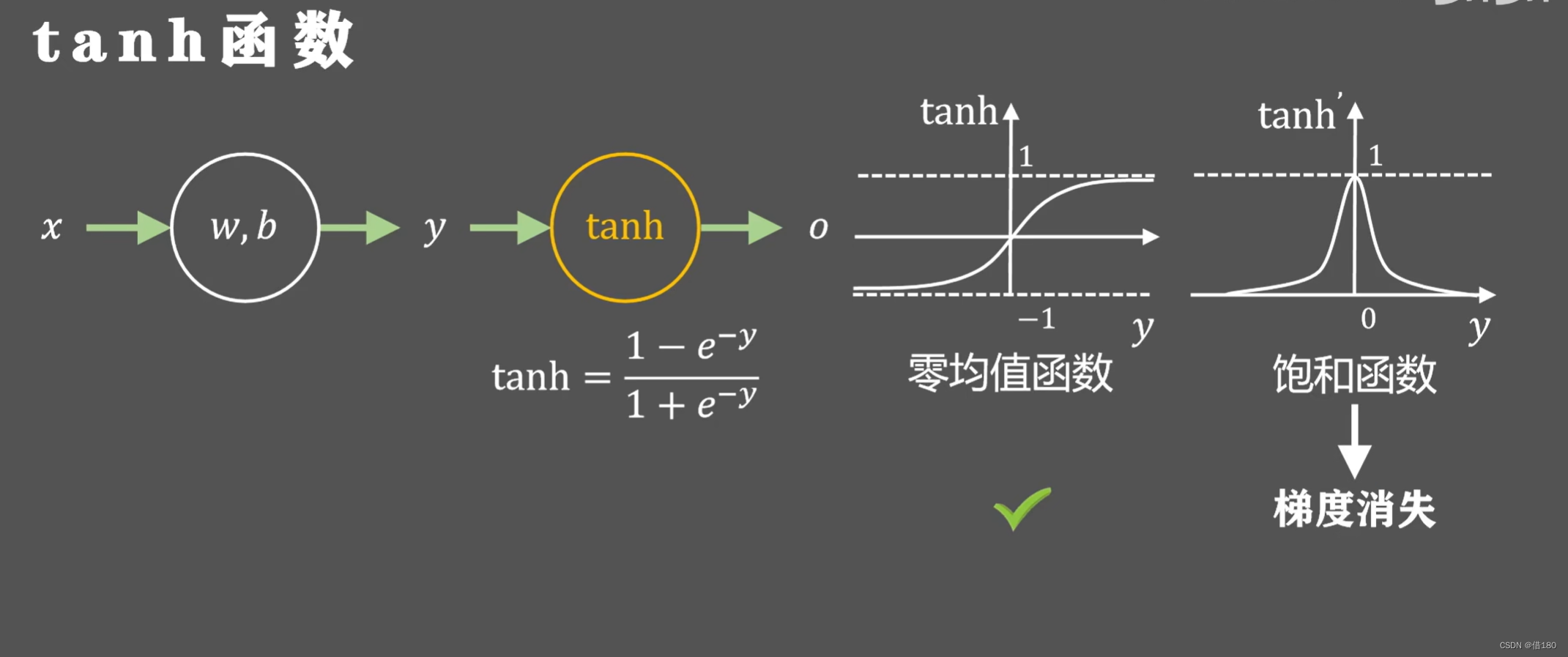
且其为非零均值函数,由前面可知导数始终大于零,那么会被强制同时正向或反向更新。这会使神经网络更慢的收敛到指定位置
ReLu函数:
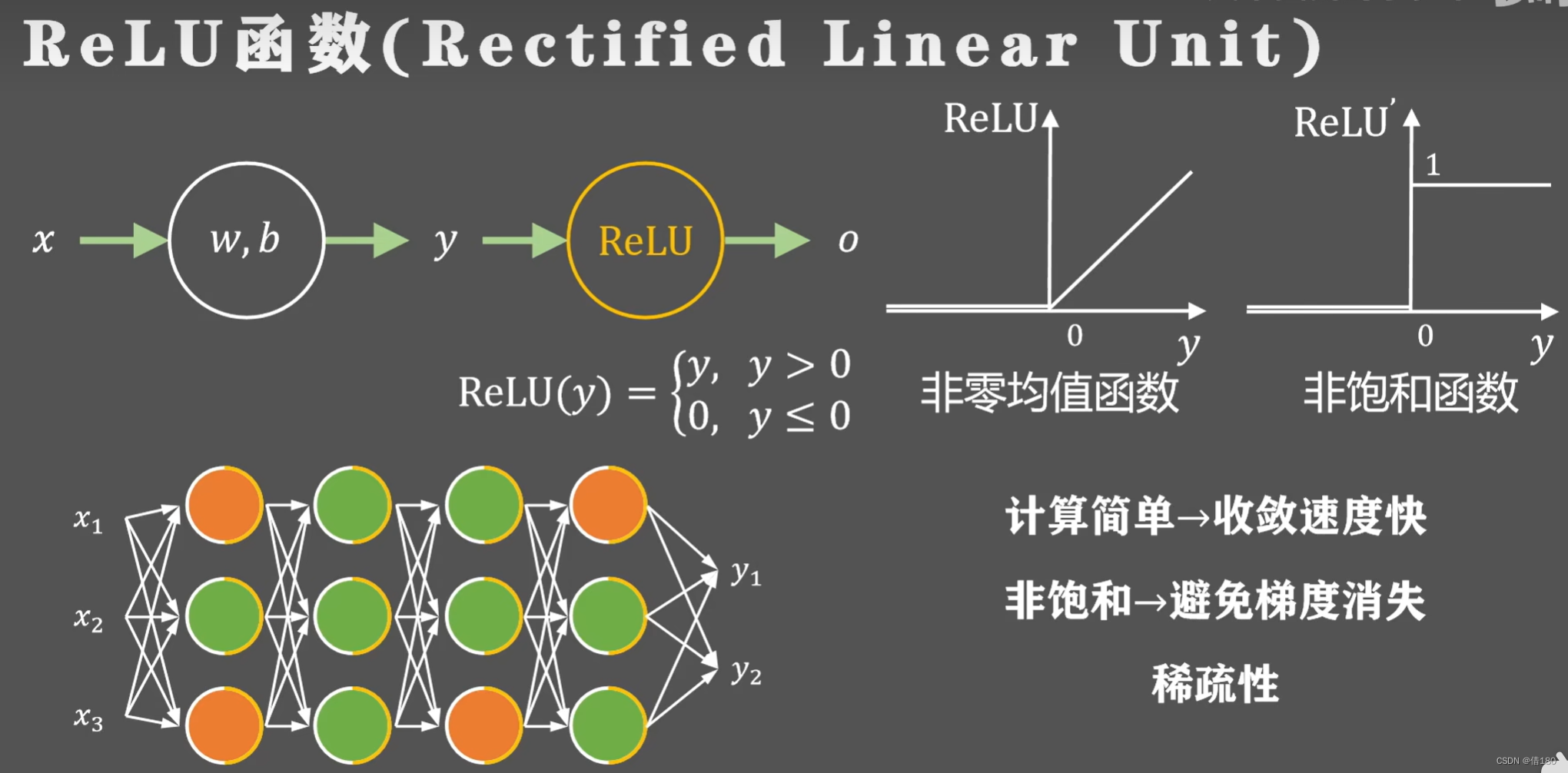
ReLU函数的优点:

缺点:
非零均值函数会影响网络的收敛效果---可用输出的归一化来解决。
relu函数没有上限,如果线性单元输出过大,或者网络是循环结构这就可能会导致梯度累计超出计算机的数值上限。这便是梯度爆炸现象。需要参数初始化和重新设置网络结构来解决。还有可能会神经元坏死。
为了解决这个问题提出了leaky relu函数,在保证稀疏性的前提下也避免了神经元的坏死。
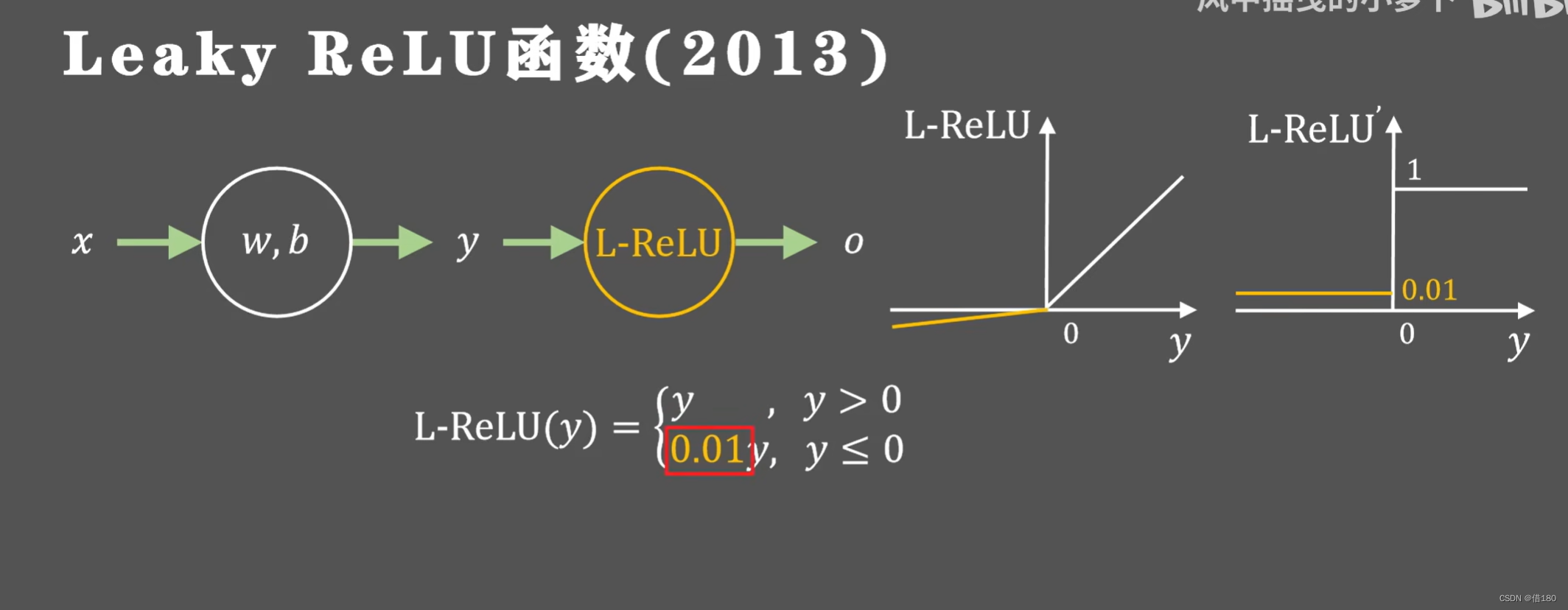
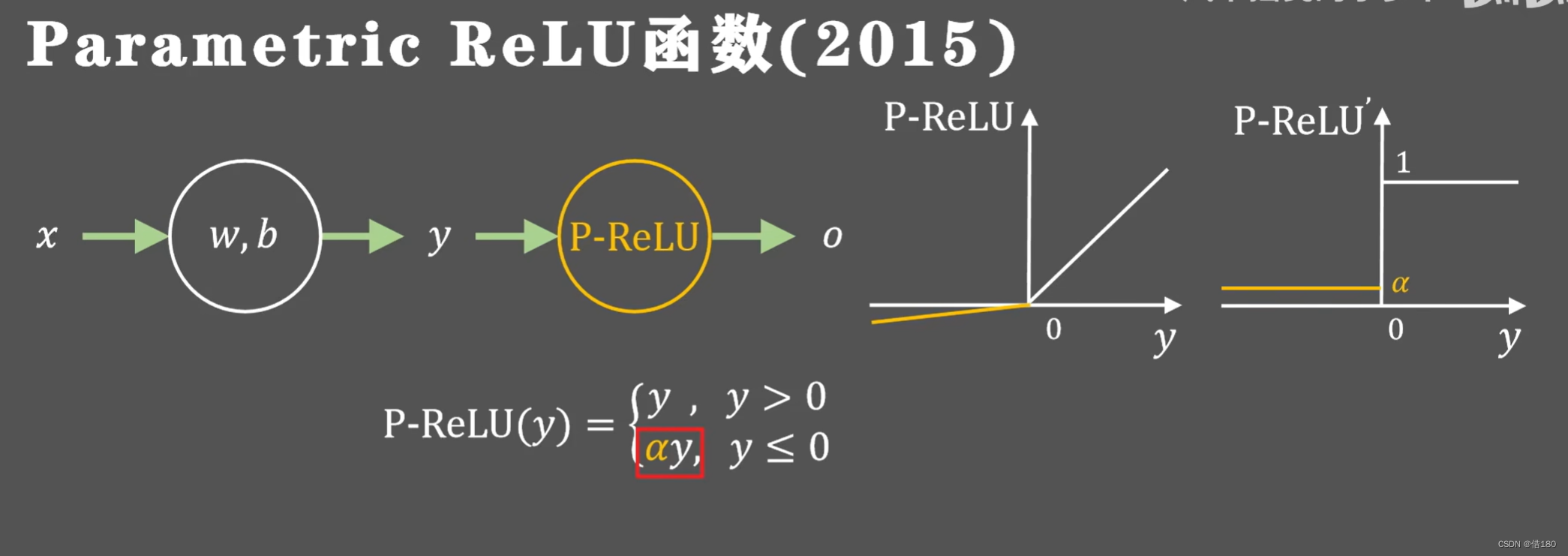
后面出现了一种将负半轴的梯度值更换成可以动态学习调整的参数。是否保持稀疏性和神经元都要通过训练过程来确定。
总结:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









