






一、前言
在python进行爬虫时,有时会遇到动态加载的页面,通过下载(访问)静态的html文件,很难取出大量有用数据。因为数据可能是随着你的访问而逐渐挂载到html中的(比如我们这里的图片加载,滚轮下滚==》图片加载),此时我们就可以需要借助selenium来解决这个问题。
二、准备
2.1 确保你的selenium可以使用
from selenium import webdriver
driver = webdriver.Firefox() # 这里是Firefox驱动,会用火狐浏览器打开百度页面
# driver = webdriver.Chrome() # 如果你下载的是谷歌浏览器的驱动,你可是使用这行代码,其他浏览器大致相当。
driver.get('https://www.baidu.com')
driver.quit()
如果自动用浏览器打开一个百度页面,则运行成功。否则运行失败,自行解决。
2.2 安装库
后面会使用到几个非系统自带的库,可能需要用pip3 install命令安装库。
2.3 分析网页代码
爬取照片的网页地址:
https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B7%E7%BE%B0%CD%BC%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MCw2LDMsMSw1LDQsMiw3LDgsOQ%3D%3D
其实就是在百度搜索框中输入风景图片打开的网址。
打开网址,F12检查
- id为imgid的标识的div下,存放的是图片页imgpage,里面存放着一定数量的图片。imgpage是动态加载的,这个截图只显示两页,如果鼠标滚轮滚,会动态加载更多图片页,
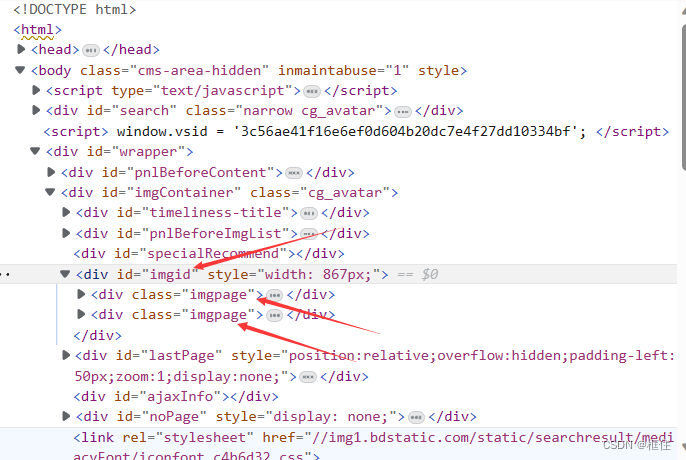
- 鼠标滚轮下滚,动态加载更多imgpage
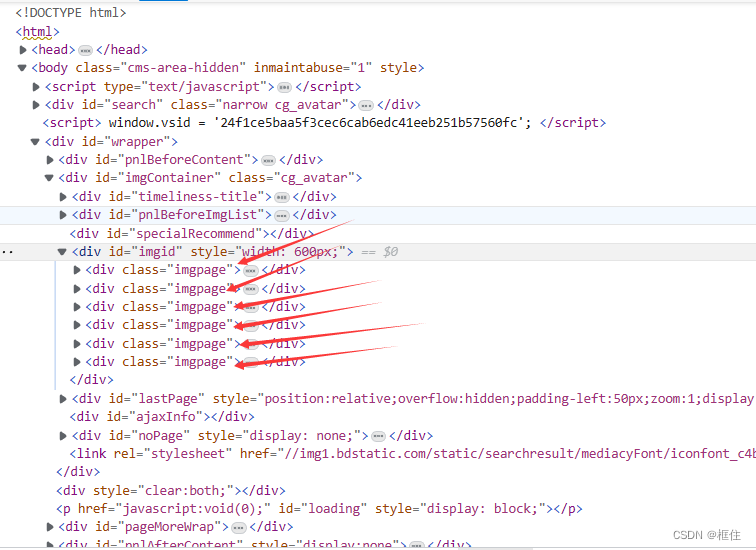
- imgpage下有个ul列表,ul下的每一个li标签存放着一个图片,。
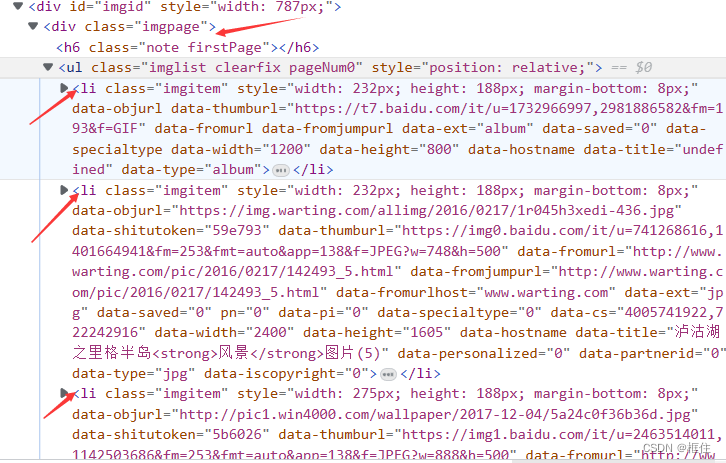
- li下的img标签的data-imgurl属性存放的是图片的下载地址,也是我们解析的目标。黑色字体标出的图片信息,取出后可以用作图片的名称。

三、编程
代码不一定是拷贝即可运行的,可能需要点改动。
比如,一些必备的库需要下载,浏览器的驱动程序(**driver.exe)
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from urllib.request import urlretrieve
from time import sleep
import os
options = Options()
options.add_argument('--headless') # 设置firefox浏览器无界面模式(不显示打开浏览器的界面)
"""
******** 替换 **********,如果你使用的不是火狐驱动,请替换代码
driver = webdriver.Chorme(options=options) # 比如换成谷歌浏览器驱动
"""
driver = webdriver.Firefox(options=options) # 火狐驱动
# 访问的网页地址
url = 'https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B7%E7%BE%B0%CD%BC' \
'%C6%AC&fr=ala&ala=1&alatpl=normal&pos=0&dyTabStr=MCw2LDMsMSw1LDQsMiw3LDgsOQ%3D%3D '
driver.get(url) # 访问页面
# 根据id查询,返回一个列表,只有一个元素(css的id是唯一标识一个标签)
ls = driver.find_elements(by='id', value='imgid')[0] # id=imgid 的标签下存放着许多class为 imgpage 的图片页,每一页存放一定量的图片,动态imgid
# 滑轮滚动次数越多,加载出的imgpage就相应越多
for i in range(2): # 因为随着我们向下浏览图片,imgpage 是动态增加的,模拟滚轮下滚,获得更多imgpage
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
print('滚轮下滑。。。')
sleep(0.5)
imgpages = ls.find_elements(By.CLASS_NAME, value='imgpage') # 取出所有图片页
print('查找到的图片页数:', len(imgpages))
n = 0 # 下载图片的次数
for imgpage in imgpages: # 遍历每一页(其实就是个ul)
img_ls = imgpage.find_elements(By.CLASS_NAME, 'imgitem') # 找到每页的所有图片(ul下的li)
for img in img_ls:
try:
img_name = img.text + '.jpg' # 取出li中的文本作为照片名称
img_name = img_name.replace('/', '_') # 如果照片名称中存在'/', 会导致文件的下载位置发生改变,故将其替换成'_'
img_img = img.find_element(By.TAG_NAME, 'img') # 找到 img 标签,其下的 data-imgurl 属性存放着图片的下载地址
url_img = img_img.get_attribute('data-imgurl') # 取出图片的下载地址
if not os.path.exists('img_downloads'): # 如果当前目录下没有img_downloads目录,则创建img_downloads目录,用来存放下载的图片
os.mkdir('img_downloads')
img_path = 'img_downloads/' + img_name # 拼接图片的下载路径
urlretrieve(url_img, img_path) # 下载图片
n += 1
except:
print(img_name + '下载失败')
else:
print(img_name + '下载成功')
print(n)
driver.quit() # 退出驱动
四、结束语
1、程序本身无实际意义,只是一个练手小程序,代码比较简单。
2、我也是第一次尝试用selenium爬取图片,所以代码应该存在很多不足之处,如有发现,还望指出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









