







项目的意义,动机,创新点,遇到的困难,产出
前言:
- 项目/论文是很重要的:
- 参加夏令营面试的时候,你得有一个能跟面试老师聊、或者说能让人家问你的东西,要不然一片空白,全问专业课真受不了,而且效果也没有项目/论文好。
- 而且如果你提前联系导师,导师可能更看重项目/论文这部分。(笔者是纯rk选手,没有提前联系老师,就是没有能拿得出手的东西)
- 所以如果你现在大一/大二/大三,有时间有精力有余力的话,尽量多去跟老师搞一些科研项目/论文(即使搞不出来成果,有一段能聊得出来东西的科研经历也是很值得的)。至于跟“卷成绩”之前的平衡问题,就得自己去考量了。
- 怎么写项目/论文:
- 如果你已经有一段扎实的科研经历,或者能拿得出手的项目/论文,这当然是很大的加分项:可以在面试/套磁老师方面更容易,需要考虑的就是弱com的话,联系导师给捞入营;强com的话,能不能通过自己的排名进去(所以说需要“平衡”)。
- 如果没有,就像上面说的,有时间有精力有余力的话,尽量多去跟老师搞一些科研项目/论文:而怎么找导师、怎么出成果、难度概率这些问题,由于笔者没怎么搞过科研,所以也不怎么清楚。只能说多跟同学讨论,有些大佬可能已经进组了,跟他们取取经是很有益处的。
- 实在没有怎么办:
- 可能你现在时间不够进组出成果了,或者没有这个精力余力搞项目/论文。但又非得搞出来一个,那可能就需要把课程实验/大作业包装成一个项目来讲。
- 你可能已经注意到,笔者的两个项目,一个是云计算的第一个课程实验,一个是电路电子学的大作业。在笔者的参营面试过程中,基本都会问到第一个“多处理器解数独问题”(不问第二个,可能是因为面试时间限制,或者是看不上这种简单陈旧的东西)。虽然面试老师们基本都能看出来这是课程实验级别的项目,但最后结果来看,笔者的面试成绩相较于笔试成绩来说,绝不是减分项。笔者也觉得很奇怪,绝非凡尔赛而言,只能归功于“运气”的成分。
- 最后,你可以参考,可以“无中生有”般包装出来一个项目;但绝不建议完全取这个巧,如果真能有一个能说能拿得出手的东西,在面试/套磁过程中也更有信心,不至于归因于“运气”的成分。
一、多处理器解数独问题(并行算法设计)
面试过程中问到的,就是多线程的思路、以及达到什么样的优化效果。
基本没有问到具体的实现代码,和舞蹈链算法的内容。
- 成果:主动派发的分发模式,时间和空间性能均接近理论最优值,实现近似线性的加速比
- 负责:标记位技术最大化利用存储空间,循环双队列自适应内存限制,细粒度工作派发使得工作线程几乎不会阻塞
1.代码
(1)Makefile
一个简单的 Makefile,用于编译 sudoku_solve 程序
# CXXFLAGS 是一个用来存放编译器参数的变量
CXXFLAGS+=-O2 -ggdb -DDEBUG
# -O2 表示启用优化等级为 2,-
# ggdb 表示生成的可执行文件包含调试信息,-
# DDEBUG 表示定义了一个名为 DEBUG 的宏,通常用于开启调试模式。
CXXFLAGS+=-Wall -Wextra # 向 CXXFLAGS 变量添加了两个编译器标志
# -Wall 和 -Wextra,它们用于启用额外的警告,有助于发现潜在的代码问题
# 在执行时,默认应该生成名为 sudoku_solve 的目标。
all: sudoku_solve
# 定义了一个名为 sudoku_solve 的目标
# 其依赖于 sudoku_solve_threadpool.cc 和 sudoku_dancing_links.cc 两个源代码文件
sudoku_solve: sudoku_solve_threadpool.cc sudoku_dancing_links.cc
g++ -O2 -o $@ $^ -pthread # 生成 sudoku_solve 目标的命令。
# g++ 是编译器的名称,
# -O2 表示使用优化等级为 2,
# -o $@ 表示将生成的可执行文件命名为 $@,$@ 在 Makefile 中代表目标的名字,
# $^ 代表所有依赖文件的列表,
# -pthread 表示链接 POSIX 线程库
# 定义了一个名为 clean 的目标,用于删除生成的可执行文件 sudoku_solve
clean:
rm sudoku_solve(2)运行脚本judge.sh
# 指定脚本解释器为Bash
#!/bin/bash
#~/test_data/advanced_test (include test1 test1000)
if [ $# != 2 ] ; then # 传递给脚本的参数数量 不等于 2
echo "参数数量不对"
echo "参数1:包含测试文件组的文件 例如 \"test_group\" (其中可能包含 ./test1 ./test1000) "
echo "参数2:包含测试文件组的文件 例如 \"answer_group\" (其中可能包含 ./answer1 ./answer1000) "
echo "完整命令列如 : $0 test_group"
exit 1; # 退出脚本,并返回退出状态码1,表示错误
fi # 结束if语句块
test_data_txt=$1 # 将第一个参数赋值给变量test_data_txt,即test_group
answer_data_txt=$2 # 将第二个参数赋值给变量answer_data_txt,即answer_group
HERE="Here"
Current_Folder=$(cd `dirname $0`; pwd) # 当前脚本所在的文件夹路径
# $(...):Bash 中的命令替换语法,它允许执行括号中的命令,并将其输出作为字符串返回。
# dirname $0:$0 表示当前脚本的名称。dirname 是一个命令,用于获取文件路径的目录部分。因此,dirname $0 返回的是当前脚本文件的路径所在的目录。
# cd dirname $0;:切换当前工作目录到脚本文件所在的目录。
# pwd:获取当前工作目录的绝对路径。
Record_Time="${test_data_txt}_Folder/Record_Time.csv" # 记录时间的文件路径test_group_Folder/Record_Time.csv
Error_Teams="${test_data_txt}_Folder/Error_Teams.csv" # 记录错误队伍的文件路径test_group_Folder/Error_Teams.csv
if [ -e ${test_data_txt}_Folder ];then # 测试数据文件夹test_group_Folder已存在 (说明:[ -e FILE ] 如果 指定的文件或目录存在时返回为真。)
echo "${test_data_txt}_Folder 无需创建,已存在"
else
mkdir ${test_data_txt}_Folder
echo "创建${test_data_txt}_Folder"
fi
touch ${Record_Time} # 创建记录时间的文件test_group_Folder/Record_Time.csv
echo "Here,Use_Time(ms),Creat_Time,Modify_Time" > ${Record_Time} # 将表头写入记录时间的文件。
# 用于计算运行时间和比对结果的函数;
# 调用:Cul_Run_Time $1 ${Current_Folder}/${Result} ${Answer_Line} ${diff_line}
#$1 Here $2 Result_name $3 ${Answer_Line} $4 diff_line
Cul_Run_Time(){
# stat $2
INODE=$(ls -i $2 |awk '{print $1}') # 文件 Advanced_Result 的 inode 号
FILENAME=$2 # 将第二个参数Advanced_Result赋值给变量
string=$(pwd) # 获取当前工作目录
array=(${string//\// }) # 当前工作目录以/为分隔符分割成数组。
root_Directory=${array[0]}; # 根目录
# echo "root_Directory=@$root_Directory@"
# 判断磁盘信息
DISK=$(df -h |grep ${root_Directory} |awk '{print $1}') # 获取磁盘信息:文件系统的名称存储在 DISK 中
# echo "DISK=@$DISK@"
if [[ -z ${DISK} ]];then # 磁盘信息为空:未找到与 ${root_Directory} 关联的文件系统
DISK=$(df -h |grep "/$" |awk '{print $1}')
fi
# 文件系统非ext4则退出
[[ "`df -T | grep ${DISK} |awk '{print $2}'`" != "ext4" ]] && { echo ${DISK} is not mount on type ext4! Only ext4 file system support!;exit 2; }
# 记录时间
Create_Time_t=$(sudo debugfs -R "stat <${INODE}>" ${DISK} | grep "crtime:" | awk '{printf $7}') # 获取文件创建时间
Access_Time_t=$(stat $2 | grep "Access: 2" | awk '{printf $3}') # 获取文件访问时间
Modify_Time_t=$(stat $2 | grep Modify | awk '{printf $3}') # 获取文件修改时间
# 根据Modify_Time_t的grep匹配查询,判断是中文/英文系统,并作处理得到正确的“文件修改时间”
if [[ -z ${Modify_Time_t} ]];then # 若修改时间为空
echo "推测为中文系统"
Modify_Time_t=$(stat $2 | grep "最近改动" | awk '{printf $2}')
else
echo "推测为英文系统"
fi
# echo "Access_Time_t:$Access_Time_t Modify_Time_t:$Modify_Time_t"
echo "Create_Time_t:$Create_Time_t Modify_Time_t:$Modify_Time_t" # 输出创建时间/修改时间
# 转换为毫秒
# Access_Time=$(date -d ${Access_Time_t} +%s%N)
Create_Time_t=$(date -d ${Create_Time_t} +%s%N) # 将创建时间转换为毫秒
Modify_Time=$(date -d ${Modify_Time_t} +%s%N)
# echo "$1 A is $Access_Time M is $Modify_Time"
# 计算时间
# Use_Time=`echo $Modify_Time $Access_Time | awk '{ print ($1 - $2) / 1000000}'`
echo "$1 Cr is $Create_Time_t M is $Modify_Time"
Use_Time=`echo $Modify_Time $Create_Time_t | awk '{ print ($1 - $2) / 1000000}'` # 计算使用时间
# Check_Answer $1 $2 $3
echo -e "\033[32m $1 Use_Time: $Use_Time ms \033[0m" # 输出使用时间
Team_Answer=$(cat $2 | wc -l) # Advanced_Result的行数
if [[ ${Team_Answer} -ge $3 ]];then # 如果Advanced_Result行数大于等于预期行数
echo -e "\033[32m Up to standard Team_Answer:${Team_Answer} Answer_Line:$3 \033[0m"
else
echo -e "\033[31m Not up to standard Team_Answer:${Team_Answer} Answer_Line:$3 \033[0m"
echo "$1 Not up to standard Team_Answer:${Team_Answer} Answer_Line:$3" >> ${Error_Teams} # 将不符合标准的team_answer记录到错误队伍文件中
fi
right_rate=$(echo "scale=2;1 - $4 / $3" | bc) # 计算正确率
# echo "$1,${right_rate},$Use_Time,${Team_Answer},$3,,$Access_Time_t,$Modify_Time_t"
# echo "$1,${right_rate},$Use_Time,${Team_Answer},$3,,$Access_Time_t,$Modify_Time_t" >> ${Record_Time}
}
# 基础测试
Basic_Test(){
# $1 Here $2 test_data_file_name $3 answer_data_file_name 即Basic_Test函数的三个形参
test_data=$(cat $2) # ./test1 kml 读取测试数据文件
Answer_Line=0 # 初始化答案行数
Exe_Prog="" # 执行文件,后面会赋值为sudoku_solve或sudoku
cd ${Current_Folder} # 切换到当前文件夹
Result="${test_data_txt}_Folder/Basic_Result" # Basic测试结果文件路径
Answer="${test_data_txt}_Folder/Basic_Answer" # Basic测试答案文件路径
# 找执行文件sudoku_solve或sudoku
if [[ -e sudoku_solve ]];then
echo "找到执行文件sudoku_solve"
Exe_Prog='sudoku_solve'
elif [[ -e sudoku ]];then
echo "找到执行文件sudoku"
Exe_Prog='sudoku'
else
echo "未找到命名为sudoku或sudoku_solve的执行文件"
echo "进行编译"
make #若未找到执行文件,脚本会自动用make编译
if [[ -e sudoku_solve ]];then
echo "找到执行文件sudoku_solve"
Exe_Prog='sudoku_solve'
elif [[ -e sudoku ]];then
echo "找到执行文件sudoku"
Exe_Prog='sudoku'
else
echo "编译后仍未找到相应执行文件"
exit 1;
fi
fi
# 创建Basic_Answer,并修改其权限,启动新screen会话
if [[ -e ./${Answer} ]];then # Basic_Answer存在,则删除重建
rm ./${Answer}
touch ./${Answer}
else
touch ./${Answer} # Basic_Answer不存在,则创建
fi
sudo chmod 777 ./${Answer} # 更改Basic_Answer文件的权限为可读写。
screen -S $1 -X quit # 关闭名为$1的screen会话($1 Here)
screen -dmS $1 # 在后台启动一个新的screen会话,会话名为$1
# 创建Basic_Result
if [[ -e ./${Result} ]];then
rm ./${Result}
touch ./${Result}
else
touch ./${Result}
fi
# 运行sudoku_solve,并将结果输出到Basic_result
screen -S $1 -X stuff "stdbuf -oL ./${Exe_Prog} > ./${Result}^M" # 使用screen命令,在后台运行sudoku_solve程序,并将输出重定向到Basic_Result文件中
while read -r test_data # 循环读取$2文件中的每一行数据($2 test_data_file_name)
do
Answer_Line=`expr ${Answer_Line} + $(cat ${test_data} | wc -l)` # 累加每个测试数据文件的行数
screen -S $1 -X stuff "${test_data}^M" # 使用screen命令将test_data($2)发送到后台程序执行
done < $2
while read -r answer_data # 循环读取$3文件中的每一行数据($3 answer_data_file_name)
do
cat ${Current_Folder}/${answer_data} >> ${Current_Folder}/${Answer} # 将${answer_data}文件的内容追加到${Answer}(Basic_Answer)文件中
done < $3
sleep 30
screen -S $1 -X stuff "^C^M" # 向后台程序发送中断信号,停止其运行
screen -S $1 -X quit # 关闭名为$1的screen会话
diff_line=$(diff -ab ./${Result} ./${Answer} | wc -l) # 计算${Result}和${Answer}文件的差异行数。
echo -e "\033[32m 错误个数:$diff_line / ${Answer_Line} \033[0m" # 输出错误个数和总行数。
Cul_Run_Time $1 ${Current_Folder}/${Result} ${Answer_Line} ${diff_line}
}
# 高级测试
# 调用:Advanced_Test ${HERE} ${test_data_txt} ${answer_data_txt}
Advanced_Test(){
# $1 Here $2 test_data_file_name
test_data=$(cat $2) # 从文件 $2 中读取全部内容,并将其存储在变量 test_data 中
Answer_Line=0
Exe_Prog=""
cd ${Current_Folder}
# 测试文件路径
Result="${test_data_txt}_Folder/Advanced_Result"
Answer="${test_data_txt}_Folder/Advanced_Answer"
# 找执行文件sudoku_solve或sudoku
if [[ -e sudoku_solve ]];then
echo "找到执行文件sudoku_solve"
Exe_Prog='sudoku_solve'
elif [[ -e sudoku ]];then
echo "找到执行文件sudoku"
Exe_Prog='sudoku'
else
echo "未找到命名为sudoku或sudoku_solve的执行文件"
echo "进行编译"
make
if [[ -e sudoku_solve ]];then
echo "找到执行文件sudoku_solve"
Exe_Prog='sudoku_solve'
elif [[ -e sudoku ]];then
echo "找到执行文件sudoku"
Exe_Prog='sudoku'
else
echo "编译后仍未找到相应执行文件"
exit 1;
fi
fi
# 创建Advanced_Answer,并修改其权限(所有用户都有读、写、执行权限),启动新screen会话
if [[ -e ./${Answer} ]];then
rm ./${Answer}
touch ./${Answer}
else
touch ./${Answer}
fi
sudo chmod 777 ./${Answer}
screen -S $1 -X quit # 结束名为 $1 的 screen 会话;如果会话不存在,则命令不会产生任何效果
screen -dmS $1 # 以后台模式创建一个新的 screen 会话,会话的名称为 $1
# 后台模式:会话会在后台运行,不会占用当前终端的控制权,可以继续在当前终端中执行其他命令
# 创建Advanced_Result
if [[ -e ./${Result} ]];then
rm ./${Result}
touch ./${Result}
else
touch ./${Result}
fi
# 在后台运行${Exe_Prog}程序,并将标准输出重定向到${Result}文件中,并设置输出缓冲方式为行缓冲。
screen -S $1 -X stuff "stdbuf -oL ./${Exe_Prog} > ./${Result}^M"
# stuff :用于向 screen 会话中发送字符序列,这里是发送"stdbuf -oL ./${Exe_Prog} > ./${Result}^M"
# stdbuf -oL ./${Exe_Prog} > ./${Result}:将 ${Exe_Prog} 程序的标准输出重定向到 ${Result} 文件中,并且使用 stdbuf 命令来设置标准输出的缓冲方式为行缓冲。
# ^M:这个字符表示回车符,是用 Ctrl+V,然后按下 Enter 产生的。它用来模拟在 screen 会话中输入回车键,以便执行发送的命令。
# read -r 不对反斜杠进行转义。以保留输入行中的特殊字符的原样,而不会对其进行解释
while read -r test_data # 从$2--test_group中逐行读取内容,每次读取一行内容存储在test_data 中
do
Answer_Line=`expr ${Answer_Line} + $(cat ${test_data} | wc -l)` # cat ${test_data} | wc -l 统计文件 ${test_data} 中的行数
screen -S $1 -X stuff "${test_data}^M" # 使用 screen 命令将当前测试数据test_data发送给名为 $1 的 screen 会话
done < $2 # < $2 表示将文件 $2 作为 while 循环的输入。也就是说,循环会读取文件 $2 的内容,直到文件结束。
while read -r answer_data
do
cat ${Current_Folder}/${answer_data} >> ${Current_Folder}/${Answer} # 读取文件 answer1/1000/10000 的内容,并将其追加到文件 Advanced_Answer 中。
done < $3
sleep 10
screen -S $1 -X stuff "^C^M" # ^C,即中断信号(Ctrl+C); ^M 表示回车符,表示模拟按下回车键,以便执行中断信号
screen -S $1 -X quit # 关闭 $1 名称的 screen 会话
diff_line=$(diff -ab ./${Result} ./${Answer} | wc -l) # 计算两个文件 ${Result} 和 ${Answer} 之间的差异行数; 选项 -ab 表示忽略空白字符,并将连续的多个空白字符视为一个空白字符
echo -e "\033[32m 错误个数:$diff_line / ${Answer_Line} \033[0m"
Cul_Run_Time $1 ${Current_Folder}/${Result} ${Answer_Line} ${diff_line}
}
if [ -e ${test_data_txt} ];then # 若测试test_data_txt(即test_group)存在
Running_Version=$(cat ${test_data_txt} | wc -l) # 文件中的行数,即获取测试样例的数量
echo "测试样例:$Running_Version 个"
cat ${test_data_txt}
if [[ $Running_Version == 1 ]];then # 若test_group中只有一行---》Basic测试
echo -e "\033[32m --------------${HERE} is running Basic_Test-------------- \033[0m"
Basic_Test ${HERE} ${test_data_txt} ${answer_data_txt} # 调用Basic_Test函数
elif [[ $Running_Version == 0 ]];then # 若test_group中0行,则输出报错信息
echo "请检查输入格式,确保文件末尾有一个换行"
else # 若test_group中大于一行
echo -e "\033[32m --------------${HERE} is running Advanced_Test--------------\033[0m"
Advanced_Test ${HERE} ${test_data_txt} ${answer_data_txt} # 调用Advanced_Test函数
fi
else # 文件${test_data_txt}不存在
echo "文件$1不存在"
exit 1;
fi
(3) sudoku_solve_threadpool.cc
-
(a)如何分配任务?How jobs are assigned?
- 在处理之前预分配任务 Pre-assign job before processing
- 动态分配任务 Dynamically assign job
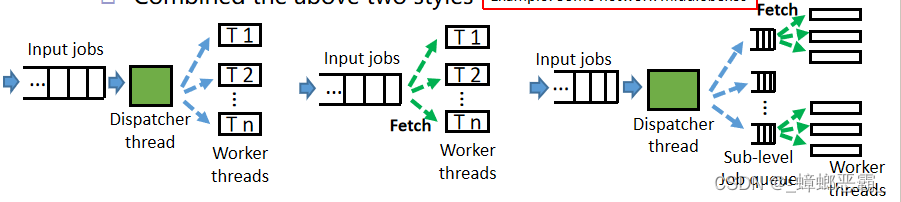
- 一个分发线程将任务分配给不同的工作者 A dispatcher thread distributes jobs to different workers【SW load balancer】
- 工作者主动从共享输入队列中获取任务 Workers actively fetch from a shared input queue【HTTP server】
- 将上述两种风格结合起来 Combined the above two styles
- (b)工作者线程是异构的还是同构的?Heterogeneous or homogeneous worker threads?
- 线程执行相同的任务 Threads do same tasks
- 线程执行不同的任务 Threads do different tasks
- (c)如何维护工作者线程?How worker threads are maintained?
- 长时间存活的工作者线程池 Long-lived worker thread pool
- 说明:提前创建多个线程,然后分配任务给他们Pre-create multiple threads, and distributed jobs to them
- 优点:隐藏了创建、销毁线程的开销Hide overhead of creating/destroying thread
- 适用:预先已知的作业
- 根据需要创建 Create on demand
- 长时间存活的工作者线程池 Long-lived worker thread pool
- 1)先读到任务/问题缓存数组:int puzzle_buf[puzzle_buf_num][N];
- 大小:const int puzzle_buf_num = 10240;
- 2)再平均分配缓存中的问题,把任务添加到进程池
- 平均分配:
- for (int i = 0; i < thread_num; i++) {
end = (start + len >= line_num) ? line_num : start + len;
start += len;
} - 添加到进程池:results.emplace_back(thread_pool.enqueue(solve, start, end));
- 3)阻塞等待:
- result.wait():阻塞直至结果变得可用
#include <assert.h>
#include <cstring>
#include <fstream>
#include <iostream>
#include <stdint.h>
#include <stdio.h>
#include <string>
#include <sys/time.h>
#include <thread>
#include "sudoku.h"
#include "threadpool.h"
using namespace std;
// ios和stdio的同步是否打开
#define SYNC 0 // 控制 ios_base::sync_with_stdio 函数;定义为 0,表示关闭同步,提高程序的运行效率
#define DEBUG 0
double total_time_start,total_time_end;
double time_start,time_end;
double sec;
ThreadPool thread_pool; // 一个线程池对象,用于管理多线程任务执行
int thread_num = 1; // 指定线程数的全局变量,初始化为 1
char one_puzzle[128]; // 一个字符数组,用于存储单个数独谜题的数据
const int puzzle_buf_num = 10240; // 数独谜题缓冲区的大小
int puzzle_buf[puzzle_buf_num][N];
// 获取当前时间
double now() { // 返回时间
struct timeval tv;
gettimeofday(&tv, NULL);
return (double)tv.tv_sec * 1000000 + (double)tv.tv_usec;
}
// 初始化线程池和同步标志
void init() {
if (DEBUG)
cout << "init ThreadPool...." << '\n';
ios_base::sync_with_stdio(SYNC);
thread_num = thread::hardware_concurrency(); // 获取当前系统支持的线程数
thread_pool.start(thread_num); // 启动线程池,其中 thread_num 参数指定了线程池中线程的数量
if (DEBUG)
cout << "ThreadNum: " << thread_num << '\n';
}
// 清理线程池
void del() {
if (DEBUG)
cout << "destroy ThreadPool...." << '\n';
thread_pool.close();
if (DEBUG)
cout << "destroy success" << '\n';
}
// 解数独
int solve(int start, int end) { //要处理的数独谜题的范围【start,end)
for (int i = start; i < end; i++)
solve_sudoku_dancing_links(puzzle_buf[i]);
if (DEBUG) {
thread::id tid = this_thread::get_id();
cout << "[tid]: " << tid << " | "
<< "[start]: " << start << " | "
<< "[end]: " << end << '\n';
}
return 0;
}
// 打印数独解
void print(int line_num) {
for (int i = 0; i < line_num; i++) {
for (int j = 0; j < N; j++)
putchar('0' + puzzle_buf[i][j]);
putchar('\n');
}
}
// 从文件中读取数独题目并解决
void file_process(string file_name) {
if (DEBUG)
total_time_start = now();
ifstream input_file(file_name, ios::in); // 以输入模式打开文件
// 一个存储 future 对象的向量,用于存储每个解数独任务的 future 对象
// future<int> 是一个表示异步操作结果的类型,这里存储的是整数类型的结果
vector<future<int>> results;
while (!input_file.eof()) {
if (DEBUG)
time_start = now();
// 取数据
int line_num = 0; // 当前读取的数独行数
while (!input_file.eof() && line_num < puzzle_buf_num) {
input_file.getline(one_puzzle, N + 1);
if (strlen(one_puzzle) >= N) {
for (int i = 0; i < N; i++)
puzzle_buf[line_num][i] = one_puzzle[i] - 48;
line_num++;
}
};
if (DEBUG)
cout << "current data line_num: " << line_num << '\n';
// 分数据
int start = 0, end = 0, len = (line_num + thread_num) / thread_num;
if (DEBUG)
cout<<"len: "<<len<<" thread_num: "<<thread_num<<endl;
for (int i = 0; i < thread_num; i++) {
end = (start + len >= line_num) ? line_num : start + len;
if (DEBUG)
cout<<"i: "<<i<<" start: "<<start<<" end: "<<end<<endl;
results.emplace_back(thread_pool.enqueue(solve, start, end));
start += len;
}
if (DEBUG)
cout << "wait task accomplish..." << '\n';
for (auto &&result : results)
result.wait();
// 输出数据
if (DEBUG)
cout << "print data" << '\n';
print(line_num);
if (DEBUG) {
time_end = now();
sec = (time_end - time_start) / 1000000.0;
cout << "[time]:" << 1000 * sec << "ms" << '\n';
cout << "------------------------------------------------------" << '\n';
}
}
input_file.close();
if (DEBUG) {
total_time_end = now();
sec = (total_time_end - total_time_start) / 1000000.0;
cout << "[total time]:" << 1000 * sec << "ms" << '\n';
cout << "------------------------------------------------------" << '\n';
}
}
int main() {
init();
string file_name;
while (getline(cin, file_name))
file_process(file_name);
del();
return 0;
}(4)phreadpool.h-基于C++11实现线程池
(a)尾返回类型推导
auto enqueue(F &&f, Args &&...args)-> std::future<typename std::result_of<F(Args...)>::type>;
推导函数的返回类型:利用auto关键字将返回类型后置
(b)future
std::future,提供了一个访问异步操作结果的途径。
可以使用std::future的wait()方法来设置屏障,阻塞线程,实现线程同步;get()方法来获得执行结果。
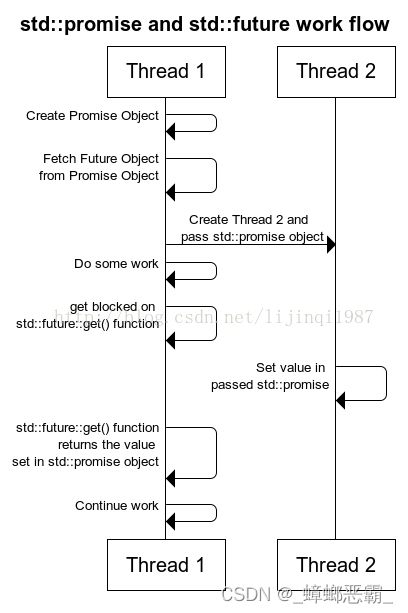
(c)function,bind,forward
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));// 完美转发,构造任务仿函数的指针
std::bind:将函数f和参数args绑定起来std::function:可以对多个相似的函数进行包装(即通用的描述方法);任何可以通过“()”来调用的对象std::forward():完美转发;完整保留参数的引用类型进行转发(左值引用,右值引用)std::make_shared<>():- 声明了一个
std::packaged_task<decltype(f(args...))()>类型的智能指针; std::function方法声明的特殊函数包装func--》作为std::packaged_task的实例化参数
- 声明了一个
std::packaged_task:可以用来封装任何可以调用的目标,从而用于实现异步的调用。
(d)task
tasks.emplace([task]() { (*task)(); });
- 将task指向的std::packaged_task对象取出并包装为void函数
- 任务进入队列
(e)unique_lock、condition——创建线程
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(
lock, [this] { return this->stop || !this->tasks.empty(); });
- std::condition_variable :
- void wait( std::unique_lock<std::mutex>& lock )
- 当前线程调用 wait() 后将被阻塞:
- 自动调用
lck.unlock() 释放锁:使得其他被阻塞在锁竞争上的线程得以继续执行。 - 一旦当前线程获得通知(notified,通常是另外某个线程调用 notify_* 唤醒了当前线程):自动调用 lck.lock(),使得 lck 的状态和 wait 函数被调用时相同。
- template< class Predicate > void wait( std::unique_lock<std::mutex>& lock, Predicate pred );
- pred 为 false 时,调用 wait() 才会阻塞当前线程;
- 收到其他线程的通知后, pred 为 true 时才会被解除阻塞;否则会释放mutex并重新阻塞在wait。
- void wait( std::unique_lock<std::mutex>& lock )
- 具体到本例:
- wait后阻塞,并释放锁:使得其他的线程可以拿到锁,并阻塞在这里;
- 当该线程被唤醒notify,拿到锁后,并且stop或者任务队列非空:就从阻塞变为就绪/执行
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <condition_variable>
#include <functional>
#include <future>
#include <memory>
#include <mutex>
#include <queue>
#include <stdexcept>
#include <thread>
#include <vector>
class ThreadPool {
public:
ThreadPool();
void start(int); // 启动线程池
void close(); // 关闭线程池
// 添加任务到线程池并返回 std::future 对象,用于获取异步任务的结果
template <class F, class... Args>
auto enqueue(F &&f, Args &&...args)
-> std::future<typename std::result_of<F(Args...)>::type>;
~ThreadPool();
private:
std::vector<std::thread> workers; // 存储工作线程的向量
std::queue<std::function<void()>> tasks; // 存储待执行任务的队列
std::mutex queue_mutex; // 保护任务队列的互斥量
std::condition_variable condition; // 条件变量,用于线程之间的同步
bool stop; // 表示线程池是否停止运行
};
// the constructor just launches some amount of workers
inline ThreadPool::ThreadPool() : stop(false) {
}
// 启动线程池:创建了指定数量的工作线程,并让它们开始等待任务的到来
inline void ThreadPool::start(int threads){
for (size_t i = 0; i < threads; ++i) // 循环创建指定数量的工作线程
workers.emplace_back([this] { // 向 workers 向量中添加一个新的线程
// [] { ... }:这是一个 lambda 表达式,用于定义线程的执行函数。
// 这里[this] 捕获了当前对象的引用,使得在 lambda 表达式中可以访问当前对象的成员变量和成员函数。
for (;;) { // 无限循环,表示线程将一直运行,直到线程池被关闭或者没有待执行的任务
std::function<void()> task; // 定义了一个 std::function 对象 task,用于存储要执行的任务
{
// 创建lock,使用 this->queue_mutex 进行加锁。
// 这里使用了 RAII技术,即资源获取即初始化,确保在退出作用域时自动释放锁。
std::unique_lock<std::mutex> lock(this->queue_mutex);
//当前线程被阻塞, 直到condition.notify_one()调用
// 如果lambda返回false,wait会解锁互斥元lock并置阻塞或等待状态,如果条件满足互斥元仍被锁定
//锁用std::unique_lock而不是std::lock_guard,是因为后者不能在wait阻塞中解锁,并在之后重新锁定
// 如果互斥元在线程休眠期间始终被锁定,enqueue就无法锁定互斥元往下执行,则造成死锁
// 一个条件变量的等待操作。它会阻塞当前线程,直到满足指定的条件。
// this->stop || !this->tasks.empty(),即线程池被关闭或者有待执行的任务。
// 在等待期间,会释放 lock 所持有的锁,允许其他线程访问共享资源。
this->condition.wait(
lock, [this] { return this->stop || !this->tasks.empty(); });
// 如果线程池被关闭且没有待执行的任务,则退出当前线程的执行。
if (this->stop && this->tasks.empty())
return;
// 从任务队列中取出一个任务,并将其移动到 task 对象中。
// std::move 函数将任务对象的所有权转移给 task 对象,避免了不必要的拷贝操作。
task = std::move(this->tasks.front());
// 从任务队列中移除已经取出的任务
this->tasks.pop();
}
// 执行取出的任务
task();
}
});
}
// 关闭线程池:设置 stop 标志为 true。
inline void ThreadPool::close(){
stop = true;
}
// add new work item to the pool
// 将任务添加到线程池:接受一个可调用对象和其参数,并返回一个 std::future 对象,用于获取异步任务的结果。
template <class F, class... Args>
auto ThreadPool::enqueue(F &&f, Args &&...args)
-> std::future<typename std::result_of<F(Args...)>::type> {
// 类型别名 return_type,表示函数 f 的返回值类型。
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared<std::packaged_task<return_type()>>(
std::bind(std::forward<F>(f), std::forward<Args>(args)...));// 完美转发,构造任务仿函数的指针
std::future<return_type> res = task->get_future();// 获得函数执行的future返回
{ //这加一个作用域的作用是出了这个作用域就解锁
std::unique_lock<std::mutex> lock(queue_mutex);
if (stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
tasks.emplace([task]() { (*task)(); }); // 塞入任务队列
} // 入队列后即可解锁
condition.notify_one(); // 仅唤醒一个线程,避免无意义的竞争
return res;
}
// the destructor joins all threads
// 析构函数的定义,清理资源并等待所有线程退出。
inline ThreadPool::~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
condition.notify_all(); // 唤醒所有线程,清理任务
}
for (std::thread &worker : workers)
worker.join(); // 阻塞,等待所有线程执行结束
}
#endif(5)sudoku_dancing_links.cc
(a)数独变换为精确覆盖问题:
算法实践——舞蹈链(Dancing Links)算法求解数独 - 万仓一黍 - 博客园 (cnblogs.com)
- 数独的约束规则的转换
-
1、每个格子只能填一个数字
-
2、每行1-9的这9个数字都得填一遍(也就意味着每个数字只能填一遍)
-
3、每列1-9的这9个数字都得填一遍
-
4、每宫1-9的这9个数字都得填一遍
-
-
约束条件对应列:
-
第1-81列完成了约束条件1:每个格子只能填一个数字;
第N列(1≤N≤81)定义成:(X,Y)填了一个数字: X=INT((N-1)/9)+1;Y=((N-1) Mod 9)+1;N=(X-1)×9+Y
-
第82-162列(共81列)完成了约束条件2:每行1-9的这9个数字都得填一遍;
第N列(82≤N≤162)定义成: 在第X行填了数字Y:
X=INT((N-81-1)/9)+1;Y=((N-81-1) Mod 9)+1;N=(X-1)×9+Y+81
-
第163-243列(共81列)完成了约束条件3:每列1-9的这9个数字都得填一遍;
第N列(163≤N≤243)定义成:在第X列填了数字Y:
X=INT((N-162-1)/9)+1;Y=((N-162-1) Mod 9)+1;N=(X-1)×9+Y+162
-
第244-324列(共81列)完成了约束条件4:每宫1-9的这9个数字都得填一遍;
第N列(244≤N≤324)定义成:在第X宫填了数字Y。
X=INT((N-243-1)/9)+1;Y=((N-243-1) Mod 9)+1;N=(X-1)×9+Y+243
-
- 有数字的格子
举例来说,在(4,2)中已经填了7,解释成4个约束条件,并转换成矩阵对应的列为
1、在(4,2)中填了一个数字。对应的列N=(4-1)×9+2=29
2、在第4行填了数字7。对应的列N=(4-1)×9+7+81=115
3、在第2列填了数字7。对应的列N=(2-1)×9+7+162=178
4、在第4宫填了数字7。对应的列N=(4-1)×9+7+243=277
于是,(4,2)中填的是7,转成矩阵的一行就是,第29、115、178、277列是1,其余列是0。把这1行插入到矩阵中去。
- 没数字的格子
还是举例说明,在(5,8)中没有数字
把(5,8)中没有数字转换成
(5,8)中填的是1,转成矩阵的一行就是,第44、118、226、289列是1,其余列是0。
(5,8)中填的是2,转成矩阵的一行就是,第44、119、227、290列是1,其余列是0。
(5,8)中填的是3,转成矩阵的一行就是,第44、120、228、291列是1,其余列是0。
(5,8)中填的是4,转成矩阵的一行就是,第44、121、229、292列是1,其余列是0。
(5,8)中填的是5,转成矩阵的一行就是,第44、122、230、293列是1,其余列是0。
(5,8)中填的是6,转成矩阵的一行就是,第44、123、231、294列是1,其余列是0。
(5,8)中填的是7,转成矩阵的一行就是,第44、124、232、295列是1,其余列是0。
(5,8)中填的是8,转成矩阵的一行就是,第44、125、233、296列是1,其余列是0。
(5,8)中填的是9,转成矩阵的一行就是,第44、126、234、297列是1,其余列是0。
把这9行插入到矩阵中。
由于这9行的第44列都是1(不会有其他行的44列会是1),也就是说这9行中必只有1行(有且只有1行)选中(精确覆盖问题的定义,每列只能有1个1),是最后解的一部分。这就保证了最后解在(5,8)中只有1个数字。
(b)舞蹈链算法求解精确覆盖问题:
跳跃的舞者,舞蹈链(Dancing Links)算法——求解精确覆盖问题 - 万仓一黍 - 博客园 (cnblogs.com)
- 数据结构:交叉十字循环双向链
- 六个分量:Left、Right、Up、Down指向左/右/上/下的元素、Col指向列标元素、Row指示当前元素所在的行
- 举例:

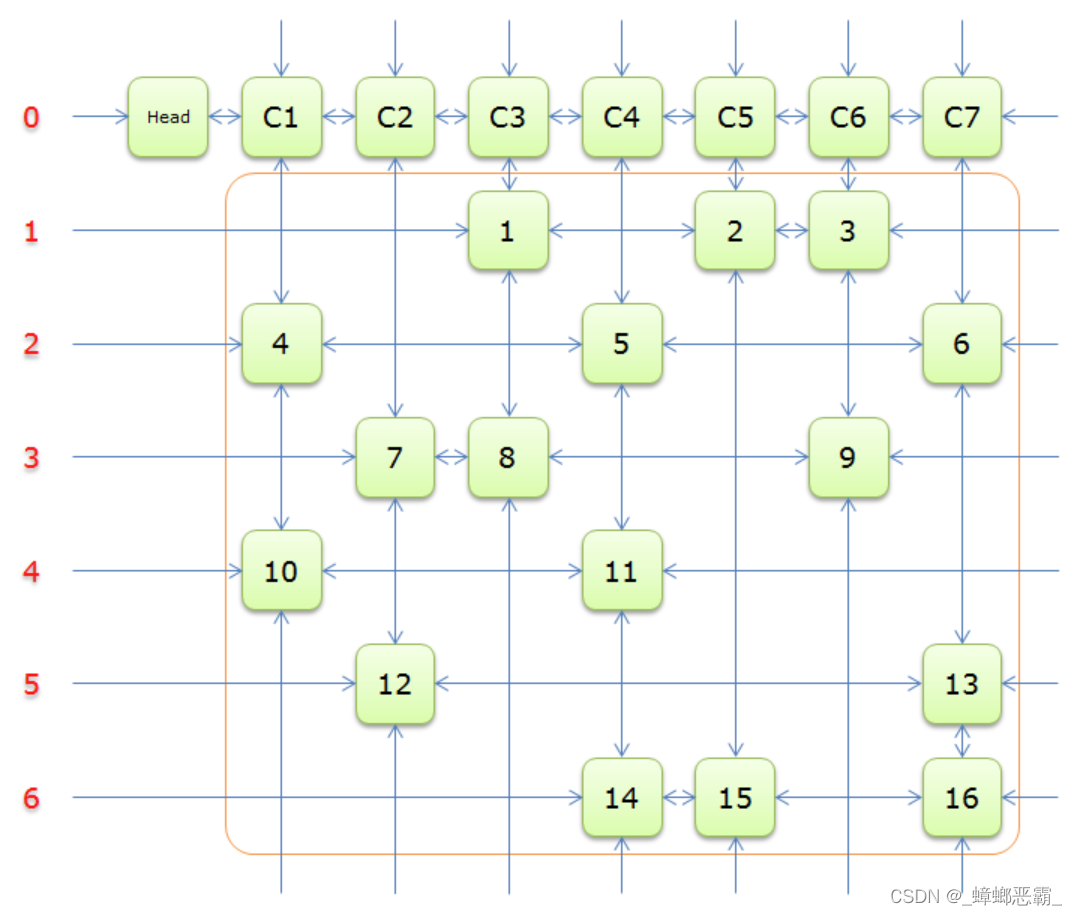
- 算法
-
判断Head.Right=Head?,若是,输出答案,返回True,退出函数。
-
获得Head.Right的元素C,并标示元素C
-
获得元素C所在列的一个元素,标示该元素同行的其余元素所在的列首元素。橙色标识同行同列的元素,紫色为备选行
-
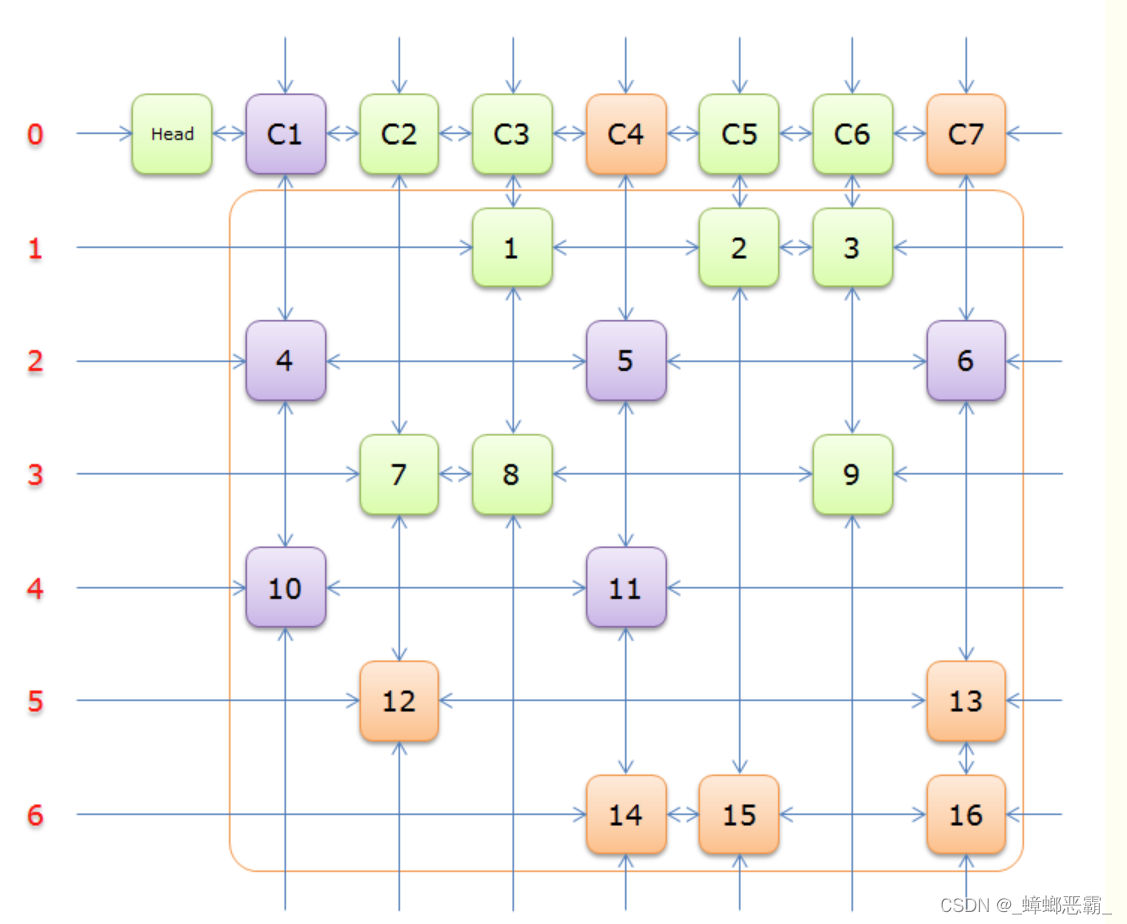
-
(删去紫色、橙色元素)获得一个简化的问题,递归调用Daning函数,若返回的True,则返回True,退出函数
-
若返回的是False,则回标该元素同行的其余元素所在的列首元素,回标的顺序和之前标示的顺序相反
-
获得元素C所在列的下一个元素,若有,跳转到步骤
-
若没有,回标元素C,返回False,退出函数。
-
#include <assert.h>
#include <map>
#include <memory.h>
#include <vector>
#include "sudoku.h"
using namespace std;
struct Node;
typedef Node Column;
struct Node {
Node *left;
Node *right;
Node *up;
Node *down;
Column *col;
int name;
int size;
};
const int kMaxNodes = 1 + 81 * 4 + 9 * 9 * 9 * 4;
const int kMaxColumns = 400;
const int kRow = 100, kCol = 200, kBox = 300;
struct Dance {
Column *root_;
int *inout_;
Column *columns_[400];
vector<Node *> stack_;
Node nodes_[kMaxNodes];
int cur_node_;
Column *new_column(int n = 0) {
assert(cur_node_ < kMaxNodes);
Column *c = &nodes_[cur_node_++];
memset(c, 0, sizeof(Column));
c->left = c;
c->right = c;
c->up = c;
c->down = c;
c->col = c;
c->name = n;
return c;
}
void append_column(int n) {
assert(columns_[n] == NULL);
Column *c = new_column(n);
put_left(root_, c);
columns_[n] = c;
}
Node *new_row(int col) {
assert(columns_[col] != NULL);
assert(cur_node_ < kMaxNodes);
Node *r = &nodes_[cur_node_++];
// Node* r = new Node;
memset(r, 0, sizeof(Node));
r->left = r;
r->right = r;
r->up = r;
r->down = r;
r->name = col;
r->col = columns_[col];
put_up(r->col, r);
return r;
}
int get_row_col(int row, int val) { return kRow + row * 10 + val; }
int get_col_col(int col, int val) { return kCol + col * 10 + val; }
int get_box_col(int box, int val) { return kBox + box * 10 + val; }
Dance(int inout[81]) : inout_(inout), cur_node_(0) {
stack_.reserve(100);
root_ = new_column();
root_->left = root_->right = root_;
memset(columns_, 0, sizeof(columns_));
bool rows[N][10] = {false};
bool cols[N][10] = {false};
bool boxes[N][10] = {false};
for (int i = 0; i < N; ++i) {
int row = i / 9;
int col = i % 9;
int box = row / 3 * 3 + col / 3;
int val = inout[i];
rows[row][val] = true;
cols[col][val] = true;
boxes[box][val] = true;
}
for (int i = 0; i < N; ++i) {
if (inout[i] == 0) {
append_column(i);
}
}
for (int i = 0; i < 9; ++i) {
for (int v = 1; v < 10; ++v) {
if (!rows[i][v])
append_column(get_row_col(i, v));
if (!cols[i][v])
append_column(get_col_col(i, v));
if (!boxes[i][v])
append_column(get_box_col(i, v));
}
}
for (int i = 0; i < N; ++i) {
if (inout[i] == 0) {
int row = i / 9;
int col = i % 9;
int box = row / 3 * 3 + col / 3;
// int val = inout[i];
for (int v = 1; v < 10; ++v) {
if (!(rows[row][v] || cols[col][v] || boxes[box][v])) {
Node *n0 = new_row(i);
Node *nr = new_row(get_row_col(row, v));
Node *nc = new_row(get_col_col(col, v));
Node *nb = new_row(get_box_col(box, v));
put_left(n0, nr);
put_left(n0, nc);
put_left(n0, nb);
}
}
}
}
}
Column *get_min_column() {
Column *c = root_->right;
int min_size = c->size;
if (min_size > 1) {
for (Column *cc = c->right; cc != root_; cc = cc->right) {
if (min_size > cc->size) {
c = cc;
min_size = cc->size;
if (min_size <= 1)
break;
}
}
}
return c;
}
void cover(Column *c) {
c->right->left = c->left;
c->left->right = c->right;
for (Node *row = c->down; row != c; row = row->down) {
for (Node *j = row->right; j != row; j = j->right) {
j->down->up = j->up;
j->up->down = j->down;
j->col->size--;
}
}
}
void uncover(Column *c) {
for (Node *row = c->up; row != c; row = row->up) {
for (Node *j = row->left; j != row; j = j->left) {
j->col->size++;
j->down->up = j;
j->up->down = j;
}
}
c->right->left = c;
c->left->right = c;
}
bool solve() {
if (root_->left == root_) {
for (size_t i = 0; i < stack_.size(); ++i) {
Node *n = stack_[i];
int cell = -1;
int val = -1;
while (cell == -1 || val == -1) {
if (n->name < 100)
cell = n->name;
else
val = n->name % 10;
n = n->right;
}
// assert(cell != -1 && val != -1);
inout_[cell] = val;
}
return true;
}
Column *const col = get_min_column();
cover(col);
for (Node *row = col->down; row != col; row = row->down) {
stack_.push_back(row);
for (Node *j = row->right; j != row; j = j->right) {
cover(j->col);
}
if (solve()) {
return true;
}
stack_.pop_back();
for (Node *j = row->left; j != row; j = j->left) {
uncover(j->col);
}
}
uncover(col);
return false;
}
void put_left(Column *old, Column *nnew) {
nnew->left = old->left;
nnew->right = old;
old->left->right = nnew;
old->left = nnew;
}
void put_up(Column *old, Node *nnew) {
nnew->up = old->up;
nnew->down = old;
old->up->down = nnew;
old->up = nnew;
old->size++;
nnew->col = old;
}
};
bool solve_sudoku_dancing_links(int *board) {
Dance d(board);
return d.solve();
}二、模型机的设计实现(体系结构)
- 成果:使用 EDA 工具设计一台用硬连线逻辑控制的简易计算机,并成功在FPGA板上通过测试
- 负责:实现指令译码器、算术逻辑单元,8重3-1多路复用器等部件的实现,模型机的整体汇总与波形测试
1.基本概念
(1)选择芯片
选择的芯片为family=Cyclone II;name=EP2C5T144C8
FPGA芯片:Cyclone II EP2C5T144C8
开发软件: Quartus II 9.0 Build 184 04/29/2009 SP 1SJ Web Edition
操作系统: Windows 11 家庭中文版
(2)EDA工具
EDA是电子设计自动化(Electronics Design AutomaTIon)
2.数据通路、数据格式、指令系统
(1)数据格式
数据字采用 8 位二进制定点补码表示,其中最高位(第 7 位)为符号位,小数点可视为最左或最右,其数值表示范围分别为:-1≤X<+1 或-128≤X<+127。
(2)寻址方式
指令的高 4 位为操作码,低 4 位分别用 2 位表示目的寄存器和源寄存器的编号,或表示寻址方式。共有 2 种寻址方式。
① 寄存器直接寻址
| 操作码 | R1 | R2 |
当R1和R2均不是“11”时,R1 和 R2 分别表示两个操作数所在寄存器的地址,其中R1为目标寄存器地址,R2为源寄存器地址。
由 R2 的编码,通过 RAA1、RAA0 从通用寄存器组 A 口读出 R2 的内容;
由 R1 的编码,通过 RWBA1、RWBA0 从通用寄存器组 B 口读出 Rq 的内容;
由/WE 和 R1 选择 RWBA1、RWBA0,将 BUS上的数据写入通用寄存器 R1。
② 寄存器间接寻址
| 操作码 | R1/11 | R2/11 |
当R1 或R2 中有一个为“11”时,表示相应操作数的地址在C寄存器中。
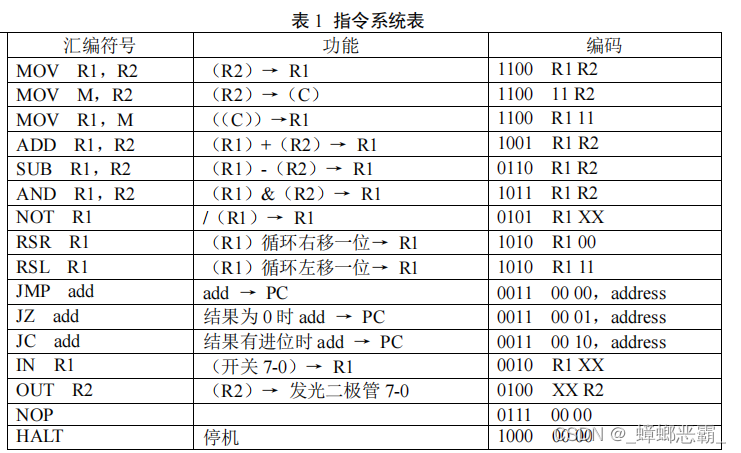
(3)指令系统
指令系统有 16 条。下面采用汇编符号对指令进行描述,其中 R1 和 R2 分别表示“目标”和“源”寄存器,M 表示地址在寄存器 C 中的存贮单元。
| 汇编符号 | 功能 | 编码 |
| MOV R1,R2 | (R2)→ R1 | 1100 R1 R2 |
| MOV M ,R2 | (R2)→ (C) | 1100 11 R2 |
| MOV R1,M | ((C)) → R1 | 1100 R1 11 |
| ADD R1,R2 | (R1)+(R2)→R1 | 1001 R1 R2 |
| SUB R1,R2 | (R1)-(R2)→R1 | 0110 R1 R2 |
| AND R1,R2 | (R1)&(R2)→R1 | 1011 R1 R2 |
| NOT R1 | /(R1)→R1 | 0101 R1 XX |
| RSR R1 | (R1)循环右移一位→R1 | 1010 R1 00 |
| RSL R1 | (R1)循环左移一位→R1 | 1010 R1 11 |
| JMP add | add→PC | 0011 00 00 address |
| JZ add | 结果为0时add→PC | 0011 00 01 address |
| JC add | 结果有进位时add→PC | 0011 00 10 address |
| IN R1 | (开关7-0)→R1 | 0010 R1 XX |
| OUT R2 | (R2)→发光二极管7-0 | 0100 XX R2 |
| NOP | 0111 00 00 | |
| HALT | 停机 | 1000 00 00 |
(4)数据通路
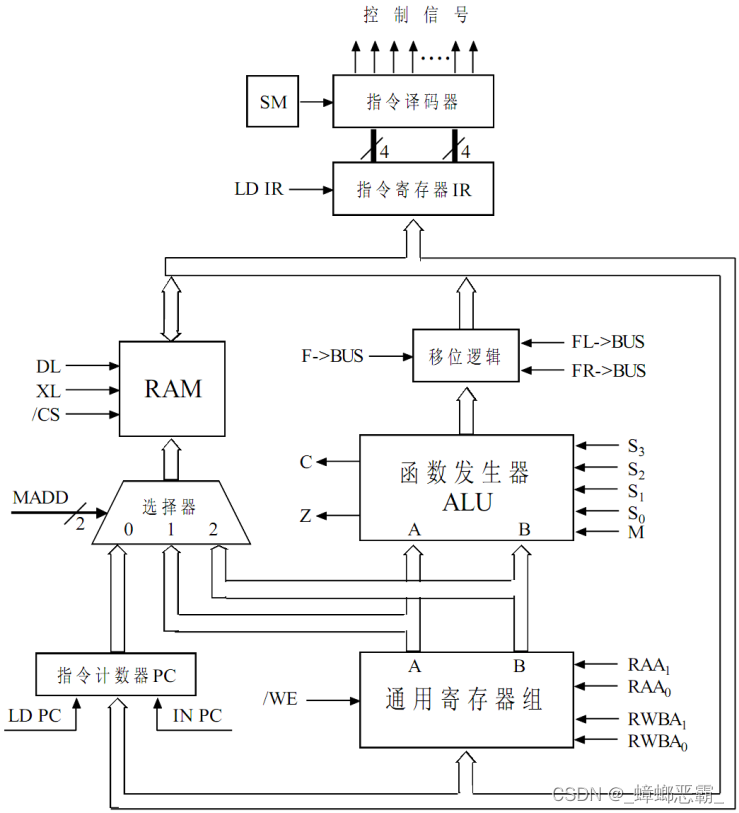
计算机的工作过程可以看作是许多不同的数据流和控制流在机器各部分之间的流动,数据流所经过的路径称作机器的数据通路。
(5)指令周期、工作脉冲设置

3.详细设计
1. 指令译码器
(1)接口设计
指令译码器的输入输出引脚如图所示;
输入:n 为使能信号,ir[7..0]是 8 位指令编码;
输出:对应的 16 条指令。

(2)功能实现
指令译码器是根据指令系统表中的指令编码,对输入的 8 位指令进行解析,判定是哪条指令,则对应指令的输出为 1,否则输出为 0。

指令译码器不是必须16个输出:
可以将MOVA、MOVB、MOVC合并,因为其指令编码的前4位数相同,只有后面4位表示寄存器的不同,但是实现都是寄存器的之间的赋值。
Verilog代码:
module ins_decode(EN,ir,MOVA,MOVB,MOVC,ADD,SUB,AND1,NOT1,RSR,RSL,JMP,JZ,JC, IN1,OUT1,NOP,HALT);
input [7:0] ir;
input EN;
output MOVA,MOVB,MOVC,ADD,SUB,AND1,NOT1,RSR,RSL,JMP,JZ,JC,IN1,OUT1,NOP,HALT;
reg MOVA,MOVB,MOVC,ADD,SUB,AND1,NOT1,RSR,RSL,JMP,JZ,JC,IN1,OUT1,NOP,HALT;
always@(ir,EN)
begin
MOVA=0;MOVB=0;MOVC=0;ADD=0;SUB=0;AND1=0;NOT1=0;RSR=0;RSL=0;JMP=0;JZ=0;JC=0;IN1=0; OUT1=0;NOP=0;HALT=0;
if (EN)
begin
if(ir[7:4]==4'b1100)
begin
if(ir[3]&ir[2]) MOVB=1;
else if(ir[1]&ir[0]) MOVC=1;
else MOVA=1'b1;
end
else if(ir[7:4]==4'b1001) ADD=1;
else if(ir[7:4]==4'b0110) SUB=1;
else if(ir[7:4]==4'b1011) AND1=1;
else if(ir[7:4]==4'b0101) NOT1=1;
else if(ir[7:4]==4'b1010)
begin
if(~ir[1]&~ir[0]) RSR=1;
else RSL=1;
end
else if(ir[7:4]==4'b0011)
begin
JC=ir[1];
JZ=ir[0];
JMP=!ir[1]&&!ir[0];
end
else if(ir[7:4]==4'b0010)IN1=1;
else if(ir[7:4]==4'b0100)OUT1=1;
else if(ir[7:4]==4'b0111)NOP=1;
else if(ir[7:4]==4'b1000) HALT=1;
else ;
end
else ;
end
endmodule2. 算术逻辑单元ALU
(1) 接口设计
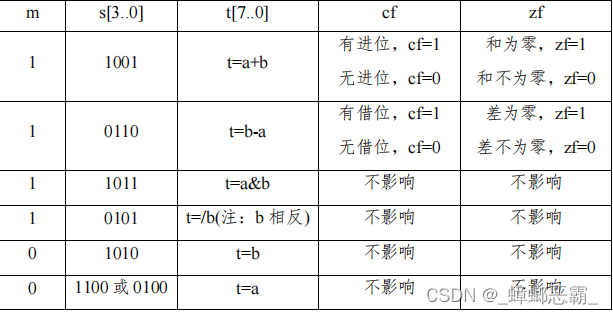
m和s[3..0]是控制信号,控制a[7..0]和b[7..0]输入的数据进行什么操作;
产生的结果输出到t[7..0]、cf和zf。

(2) 功能实现
在 S3~S0和 M 的控制下,实现运算,经移位逻辑送入总线 BUS;
由/WE 控制和 R1 的编码选择 RWBA1、RWBA0,将 BUS 上的数据写入通用寄存器 R1。
其中 ADD 和 SUB 指令影响状态位 Cf 和 Zf。
Verilog代码:
module simple(a,b,s,m,t,cf,zf);
input [7:0] a,b;
input [3:0] s;
input m;
output cf,zf;
output [7:0] t;
reg cf,zf;
reg [7:0] t;
always@(m,s,a,b)
begin
t=8'b0;
cf=1'b0;
zf=1'b0;
if(m==1)
begin
if(s==4'b1001)
begin
{cf,t}=a+b;
if(t==0) zf=1;
else zf=1'b0;
end
else if(s==4'b0110)
begin
{cf,t}=b-a;
if(t==0) zf=1'b1;
else zf=0;
end
else if(s==4'b1011) t=a&b;
else if(s==4'b0101) t=~b;
end
else
begin
if(s==4'b1010) t=b;
if(s==4'b1100||s==4'b0100)t=a;
end
end
endmodule3. 8重3-1多路复用器
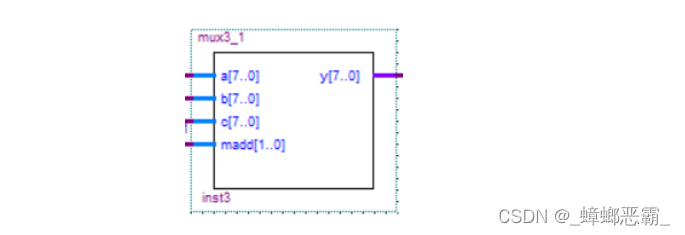
(1)接口设计
8 重 3-1 多路复用器有 3 个输入 1 个输出,每个输入和输出都是 8 位,所以称之为 8 重.
MADD 选择将哪个输入传至输出,8 重 3-1 多路复用器的引脚如图所示:
(2)功能实现
多路复用器是一个组合电路,可以从多个输入中选择一个输入,并将信息直接传输到输出。
选择哪一条输入线由一组输入变量控制,它们被称为选择输入。通常, 2^n条输入线要 n 个选择输入,选择输入的位组合决定选择哪个输入线。
Verilog代码:
module mux3_1(a,b,c,madd,y);
input [7:0] a,b,c;
input [1:0] madd;
output reg [7:0] y;
always@(madd)
begin
if(madd==2'b00) y=a;
else if(madd==2'b01) y=b;
else if(madd==2'b10) y=c;
else y=8'b00000000;
end
endmodule

4. 移位逻辑
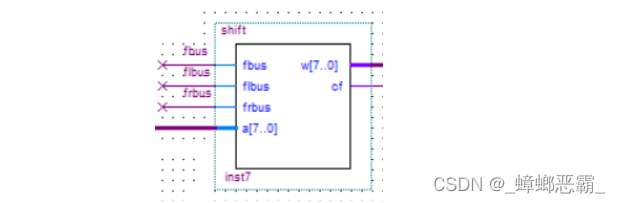
(1)接口设计
输入端口:来自 ALU 的数据,以及三个控制信号;
输出:通向总线的数据和 C 标志的控制。
(2)功能实现
经移位逻辑循环右移或循环左移后送入总线BUS;
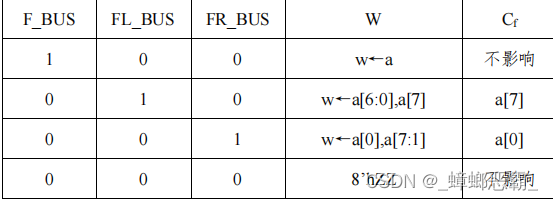
移位逻辑不工作时,输出高阻:
为了预防移位逻辑输出数据到总线中,和其他位置输出到总线中的数据起冲突,应该阻止移位逻辑向总线输出数据,故此时移位逻辑输出应该为高阻。
Verilog代码:
module shift(fbus,flbus,frbus,a,w,cf);
input fbus,flbus,frbus;
input [7:0] a;
output reg [7:0] w;
output reg cf;
initial
begin
w=0;cf=0;
end
always @ (fbus,flbus,frbus,a)
begin
if(fbus==1'b1) w=a;
else if(flbus==1'b1)
begin cf=a[7];
w[7:1]=a[6:0];
w[0]=a[7];
end
else if(frbus==1'b1)
begin cf=a[0];
w[7]=a[0];
w[6:0]=a[7:1];
end
else w=8'hZZ;
end
endmodule
5. 控制信号产生逻辑
(1)接口设计
输入端口:来自指令译码器的 16 个指令信号;控制取址和执行周期的 SM 信号;指令码的直接输入 IR;cf,zf 状态位的输入;
输出端口:各个模块的一些控制信号,在图中均已标明。

(2)功能实现
控制信号产生逻辑接收指令译码器的输出,在 SM、IR[7..0]以及状态位 Cf 和 Zf 的配合下产生每个模块所需要的控制信号。
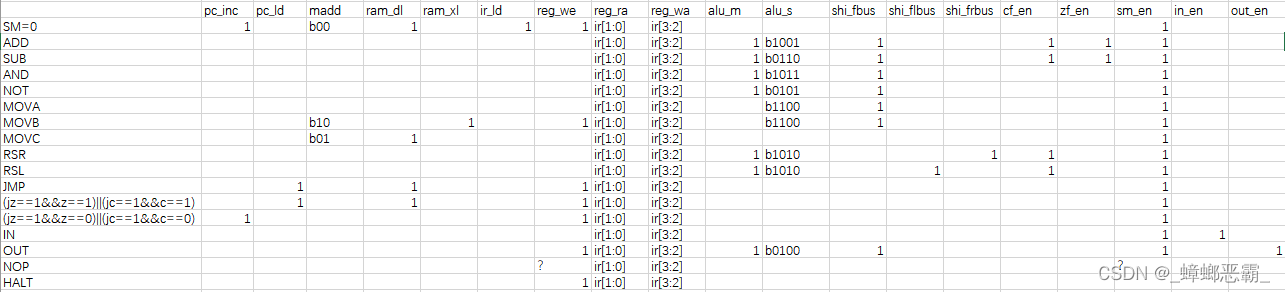
Verilog代码:
module con_signal(
mova,movb,movc,add,sub,and1,not1,rsr,rsl,jmp,jz,z,jc,c,in1,out1,nop,halt,ir,sm,
reg_ra,reg_wa,madd,alu_s,pc_ld,pc_inc,reg_we,ram_xl,ram_dl,alu_m,shi_fbus,shi_flbus,shi_frbus,
ir_ld,cf_en,zf_en,sm_en,in_en,out_en);
input mova,movb,movc,add,sub,and1,not1,rsr,rsl,jmp,jz,z,jc,c,in1,out1,nop,halt,sm;
input [7:0] ir;
output pc_ld,pc_inc,reg_we,ram_xl,ram_dl,alu_m,shi_fbus,shi_flbus,shi_frbus,ir_ld,cf_en,zf_en,sm_en,in_en,out_en;
output [1:0] reg_ra,reg_wa,madd;
output [3:0] alu_s;
reg pc_ld,pc_inc,reg_we,ram_xl,ram_dl,alu_m,shi_fbus,shi_flbus,shi_frbus,ir_ld,cf_en,zf_en,sm_en,in_en,out_en;
reg [1:0] reg_ra,reg_wa,madd;
reg [3:0] alu_s;
always @(mova,movb,movc,add,sub,and1,not1,rsr,rsl,jmp,jz,z,jc,c,in1,out1,nop,halt,ir,sm)
begin
reg_ra = ir[1:0];
reg_wa = ir[3:2];
madd = 2'b00;alu_s = 4'b0000;pc_ld = 1'b0;pc_inc = 1'b0;reg_we = 1'b0;ram_xl = 1'b0;ram_dl = 1'b0;alu_m = 1'b0;
shi_fbus = 1'b0;shi_flbus = 1'b0;shi_frbus = 1'b0;ir_ld = 1'b0;cf_en = 1'b0;zf_en = 1'b0;sm_en = 1'b0;in_en = 1'b0;out_en = 1'b0;
if(sm == 1'b1)
begin
//DL
ram_dl = movc | jmp | (jz&z) | (jc&c);
//XL
ram_xl = movb;
//MADD
madd = {movb,movc};
//LD_PC
pc_ld = jmp | (jz&z) | (jc&c);
//IN_PC
pc_inc = (jz == 1'b1&&z == 1'b0)|(jc == 1'b1&&c == 1'b0);
//LD_IR
//ir_ld = sm;
//F_BUS
shi_fbus = add | sub | and1 | not1 | out1 | mova | movb ;
//FL_BUS
shi_flbus = rsl;
//FR_BUS
shi_frbus = rsr;
//M
alu_m = add | sub | and1 | not1 ;
//alu_s=ir[7:4];
//S
if(add == 1'b1) alu_s = 4'b1001;
else if(sub == 1'b1) alu_s = 4'b0110;
else if(and1 == 1'b1) alu_s = 4'b1011;
else if(not1 == 1'b1) alu_s = 4'b0101;
else if(rsr == 1'b1 ||rsl ==1'b1) alu_s = 4'b1010;
else if(out1 == 1'b1) alu_s = 4'b0100;
else if(mova == 1'b1||movb == 1'b1) alu_s = 4'b1100;
// /WE
reg_we = out1 | movb | jmp | jz | jc | halt|nop;
//RAA
//if(add == 1'b1||sub == 1'b1||and1 == 1'b1||mova == 1'b1||movb == 1'b1) reg_ra = ir[1:0];
//RWBA
//if(add == 1'b1||sub == 1'b1||and1 == 1'b1||not1 == 1'b1||rsr ==1'b1||rsl == 1'b1||in1 == 1'b1||out1 == 1'b1||mova == 1'b1||movc == 1'b1) reg_wa = ir[3:2];
//CF_EN
cf_en = add | sub | rsr | rsl;
//ZF_EN
zf_en = add | sub;
//SM_EN
sm_en = ~halt;
//IN_EN
in_en = in1;
//OUT_EN
out_en = out1;
end
else //quzhi
begin
ram_dl = 1'b1; //DL
pc_inc = 1'b1; //IN_PC
ir_ld = 1'b1; //LD_IR
reg_we = 1'b1; // /WE
sm_en = 1'b1; //SM_EN
end
end
endmodule(3)功能仿真验证
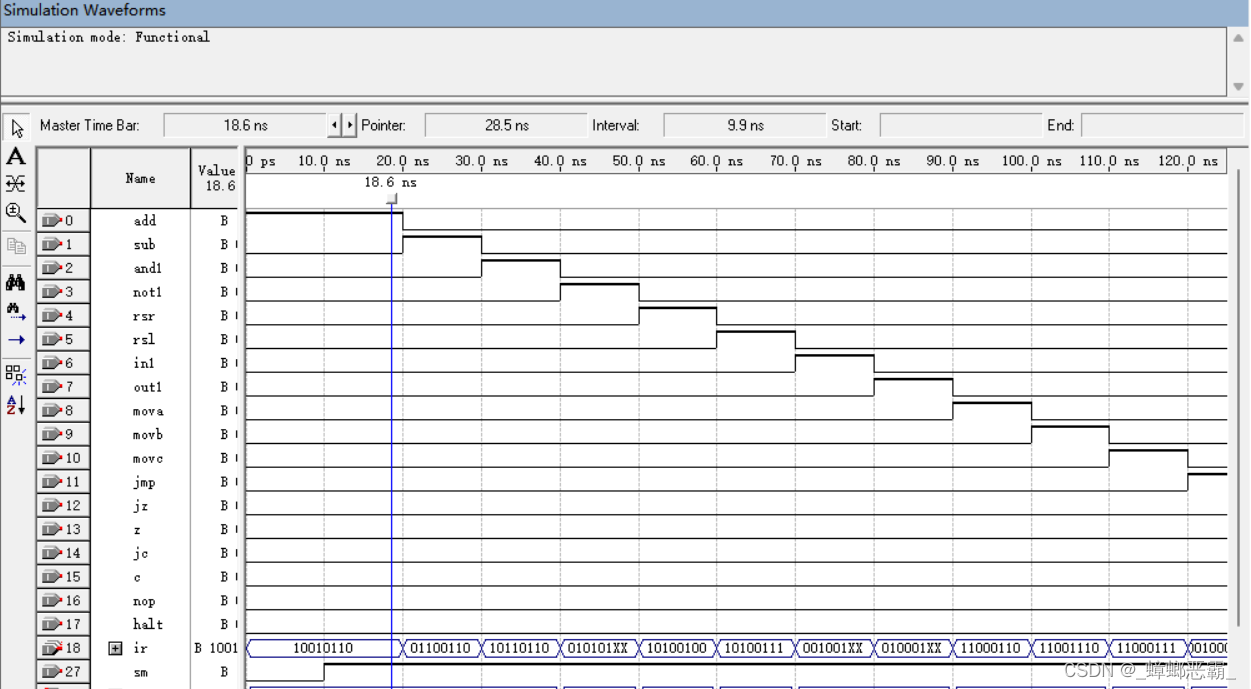

-
当 add 指令执行时,shi_fbus,alu_en,cf_en,zf_en,sm_en 输出为 1,其他输出为 0,alu_s 为 1001,reg_ra 输出 01,reg_wa 输出 00。
-
当 sub 指令执行时,shi_fbus 和 alu_m,cf_en,zf_en 和 sm_en 输出为 1,其他输出为 0,alu_s 输出 0110,reg_ra 输出 01,reg_wa 输出 00。
-
当 and1 指令执行时,shi_fbus 和 alu_m 和 sm_en 输出 1,其他输出 0,alu_s输出 1011,reg_ra 输出 01,reg_wa 输出 00。
-
当not1 指令执行时,shi_fbus 和 alu_m 和 sm_en 输出 1,其他输出 0,alu_s 输出 0101,reg_ra 输出 00,reg_wa 输出 00。
-
当rsl 指令执行时,shi_flbus 和 alu_m 和 cf_en 和 sm_en 输出 0,其他输出 0,alu_s 输出 1010,reg_ra 和 reg_wa 输出 00。
-
当rsr 指令执行时,shi_frbus 和 alu_m 和 cf_en 和 sm_en 输出 1,其他输出 0,alu_s 输出 1010,reg_ra 输出 11,reg_wa 输出 00。
-
当in1 指令执行时,sm_en 和 in_en 输出 1,其他输出 0。
-
当out1 指令执行时,sm_en 和 out_en 输出 1,其他输出 0。
-
当 mova 指令执行时,shi_fbus 和 sm_en 输出 1,其他输出为 0,madd 输出 00,alu_s 输出为 1100,reg_ra 输出 01,reg_wa 输出 00。
-
当 movb 指令执行时,ram_xl 和 shi_fbus 和 reg_we 和 sm_en 输出为 1,其他输出为 0,madd 输出为 10,alu_s 输出为 1100,reg_ra 输出 01,reg_wa 输出 11。
-
当 movc 指令执行时,ram_dl 和 sm_en 输出为 1,其他输出为 0,madd 输出 01,alu_s 输出 1100,reg_ra 输出 11,reg_wa 输出 01。
-
当jmp 指令执行时,ram_dl,pc_ld,reg_we 和 sm_en 输出 1,其他输出 0,alu_s输出 0001,reg_ra 和 reg_wa 输出 00。
-
当jz 指令为 1 和 jc 指令为 1 时,若 z 和 c 为 1 时,ram_dl 和 pc_ld 和 reg_we和 sm_en 输出为 1,其他输出为 0。若 z 和 c 为 0 时,pc_inc 和 reg_we 和 sm_en 输出 1,其他输出 0,正确
-
当nop 指令执行时,sm_en 输出 1,其他输出为0。
-
当halt指令执行时,输出全为0。
所以,仿真验证正确。
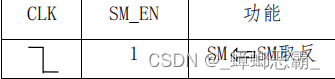
6. SM
(1)接口设计
输入端口:时钟信号和使能信号;
输出:当前是取 指周期还是执行指令周期。
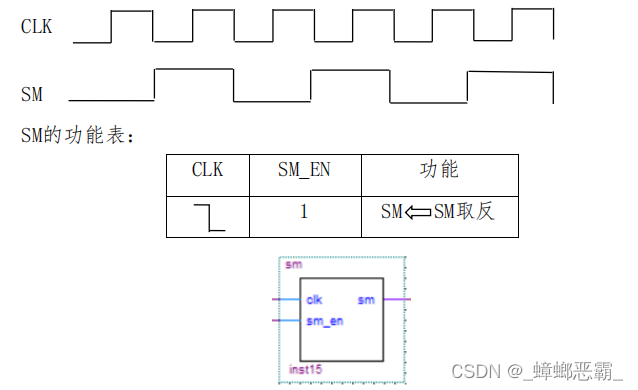
(2)功能实现
SM为0 是取指令周期;SM为1是执行指令周期。
Verilog代码:
module sm(clk,sm_en,sm);
input clk,sm_en;
output reg sm;
initial sm=1;
always@ (negedge clk)
begin
if(sm_en==1'b1)
sm<=~sm;
else sm<=sm;
end
endmodule7. 指令寄存器IR
(1)接口设计
输入端口:时钟信号 clk,控制读入信号 ir_ld,来自 总线的信号 d;
输出: ir。
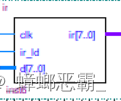
(2)功能实现
指令寄存器用于暂存当前正在执行的指令。
当控制信号IR_LD为1时,指令寄存器在CLK的下降沿将总线传输的指令写入寄存器。
指令寄存器IR是一个8位寄存器。

Verilog代码:
module ir(clk,ir_ld,d,ir);
input clk,ir_ld;
input [7:0] d;
output reg [7:0] ir;
always@(negedge clk)
begin
ir=0;
if(ir_ld==1'b1)
ir<=d;
end
endmodule
8. 状态寄存器PSW
(1)接口设计
输入端口:时钟信号,c/z 使能信号; alu 和移位逻 辑传输过来的 cf,zf 信号。
输出: c,z 信号
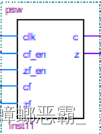
(2)功能实现
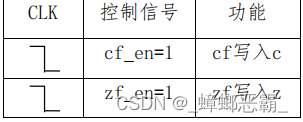
PSW用来存放ADD、SUB、RSR、RSL指令执行结果的状态标志,如有无借位进位(C)、结果是否为零(Z)。
本模型机PSW是一个2位寄存器。
Verilog代码:
module psw(clk,cf_en,zf_en,cf,zf,c,z);
input clk,cf_en,zf_en,cf,zf;
output reg c,z;
always@(negedge clk)
begin
if(cf_en==1'b1) c<=cf; //jinwei wei 1
if(zf_en==1'b1) z<=zf; //jieguo wei 0
end
endmodule9. 指令计数器PC
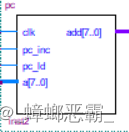
(1)接口设计
输入端口:来自总线上的数据 a;来自控制信号发生逻辑的加载信号 pc_ld;自加信号 pc_inc;时钟信号 clk。
输出端口:通向选择器的地址输出 add。
(2)功能实现
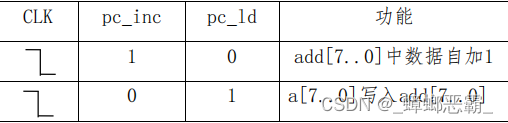
CPU执行一条指令,根据PC中存放的指令地址,将指令从RAM读出写入指令寄存器IR中,此过程称为“取指令”。
在每条指令读取后,PC中的地址自动加1,指向下一条指令在RAM中的存放地址。
跳转指令如JMP、JZ、JC让程序跳转至指定地址去执行,这时PC需要装载跳转地址。
Verilog代码:
module pc(input clk,pc_ld,pc_inc,
input [7:0] a,
output reg [7:0] add);
always @ (negedge clk)
begin
if(pc_inc==1 && pc_ld==0) add<=(add+8'h00000001);
else if(pc_inc==0 && pc_ld==1) add<=a;
else add<=add;
end
endmodule10. 通用寄存器组
(1)接口设计
输入端口:控制信号发生单元的写使能信号 WE;源寄存器地址 raa,目的寄存器地址 rwba;来自总线上的数据输入 i 和系统时钟信号 clk。
输出: s 和 d。

(2)功能实现
寄存器主要用来保存操作数和运算结果等信息,从而节省从RAM中读取操作数所需占用总线和访问存储器的时间。

Verilog代码:
module reg_group(input clk,we,
input [1:0] raa,rwba,
input [7:0] i,
output [7:0] s,d); //xie cheng 'reg' hui bao cuo
reg [7:0] a,b,c;
initial
begin
a=8'b0000_0001;
b=8'b0000_0010;
c=8'b1000_0000;
end
assign s=(raa==2'b00)?a:
(raa==2'b01)?b:
(raa==2'b10)?c:0;
assign d=(rwba==2'b00)?a:
(rwba==2'b01)?b:
(rwba==2'b10)?c:0;
always @ (negedge clk)
begin
if(we==0)
begin
if(rwba==2'b00) a<=i;
else if(rwba==2'b01) b<=i;
else if(rwba==2'b10) c<=i;
else begin a<=a;b<=b;c<=c;end
end
end
endmodule
11. RAM的使用
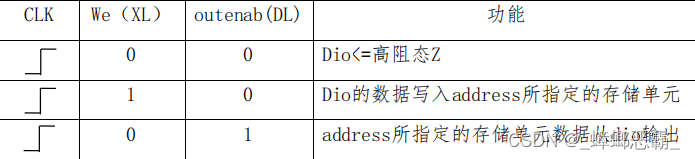
(1)接口设计
ADDR[7..0]指定访问RAM的地址,时钟CLK上升沿,XL为1,将外部输入DATAIN[7..0]写入RAM的对应存储单元。不改变ADDR[7..0]的值,这时DL为1,读取RAM,查看DATAOUT[7..0]中的输出是否跟前面写入的数据是否一致,从而学习对RAM的读写操作。
(2)功能实现
电路图:
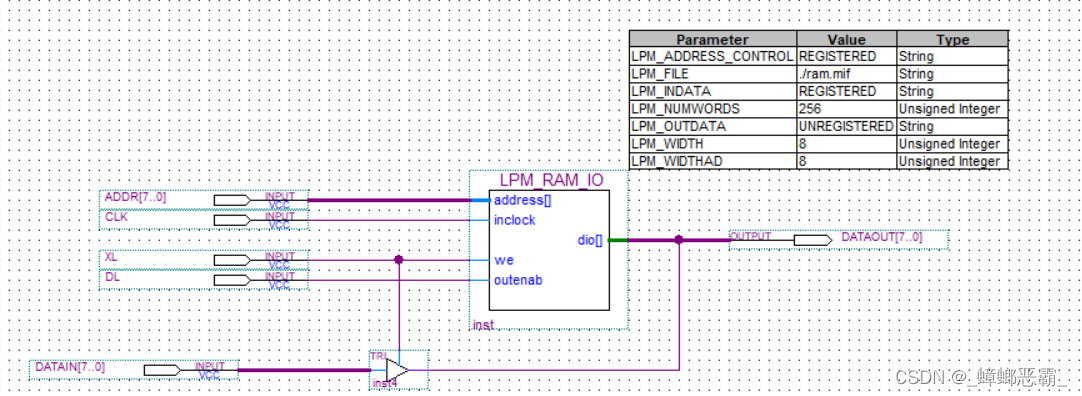
4.系统测试
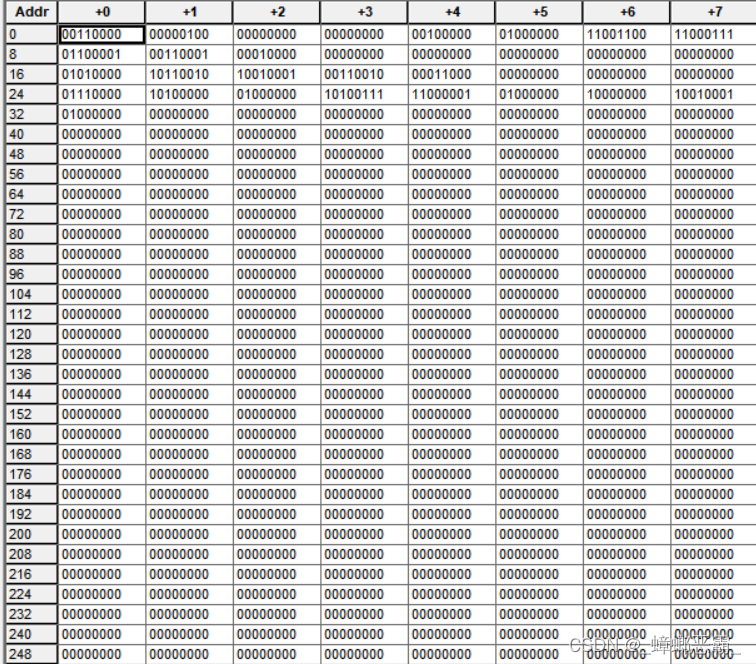
(1)仿真的测试程序
| 地址 | 指令码 | 汇编符号 | 作用 | 信号变化 |
| 0 | 00110000 | JMP | 跳转 | |
| 1 | 00000100 | JMP 04H | 跳转到 0000 0100 | |
| 4 | 00100000 | IN A | 输入 1000 0011 | A=1000 0011 |
| 5 | 01000000 | OUT A | 输出 1000 0011 | |
| 6 | 11001100 | MOV M,A | A->M | C=1000 0011 |
| 7 | 11000111 | MOV B M | M->B | B=1000 0011 |
| 8 | 01100001 | SUB A B | (A-B) ->A | A=0000 0000,Z=1 |
| 9 | 00110001 | JZ | 条件跳转(Z==1) | |
| 10 | 00010000 | JZ 10H | 条件跳转到0001 0000 | |
| 16 | 01010000 | NOT A | /A -> A | A=1111 1111 |
| 17 | 10110010 | AND A C | (A&C) ->A | A=1000 0000 |
| 18 | 10010001 | ADD A B | (A+B) ->A | A=0000 0011,C=1 |
| 19 | 00110010 | JC | 条件跳转(C==1) | |
| 20 | 00011000 | JC 18H | 条件跳转到0001 1000 | |
| 24 | 01110000 | NOP | ||
| 25 | 10100000 | RSR A | A循环右移一位 ->A | A=1000 0001 |
| 26 | 01000000 | OUT A | 输出A | |
| 27 | 10100111 | RSL B | B 循环左移一位 ->B | B=0000 0111 |
| 28 | 11000001 | MOV A B | B->A | A=0000 0111 |
| 29 | 01000000 | OUT A | ||
| 30 | 10000000 | HALT | 停机 | |
| 31 | 10010001 | ADD A B | ||
| 32 | 01000000 | OUT A |
Mif文件:
(2)仿真的测试结果


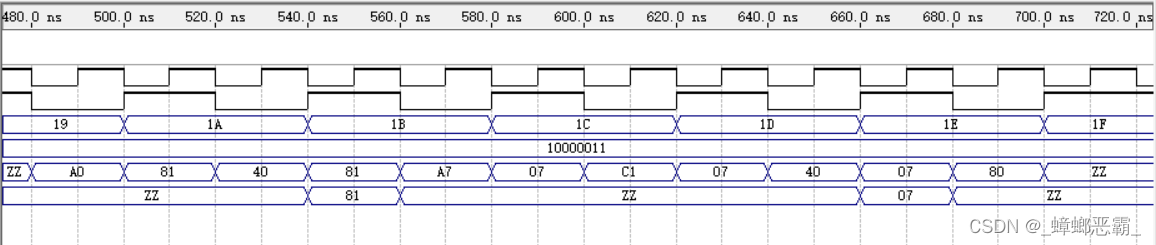
三个out信号,对应的输出结果为83H,81H,07H;
结果与预期一致,故测试成功。
(3)下板的测试程序

Mif文件:
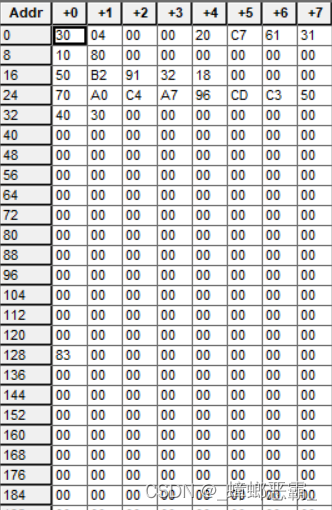
(4)下板的测试结果
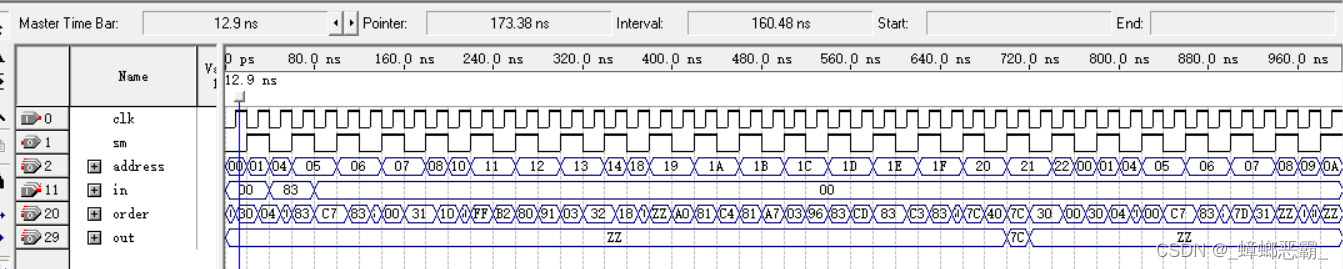
外部输入为10000011,那么 JZ 和 JC 都跳转成功,执行输出 OUT A,输出为 01111100(7CH)
改变外部输入,使其不为 10000011,那么 JZ 不成功,实现停机 HALT。
将程序下载到FPGA板后,功能成功实现。

















 2158
2158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









