






目前已经complete作者的stage1部分代码的改写与理解,后续打算训练一下看看效果。在看第二部分reconstruction之前开一篇新文章,因为我发现作者的第一部分alignment实际就是之前学者们在做的图像的配准(对齐)工作,因此这里打算去再看几篇文献加深对该方面的理解,便于后续着手进行改进。在这个时候接触到了RTALK上刘帅成教授的学术报告,因此就根据此进行相关理解。
注:教授首先提出了stitching过程中的主要问题(个人感觉还是很精辟的,可以作为自己研究重点):重复纹理;无纹理/弱纹理;大前景干扰;夜景(噪声)干扰;大视差。而homography作为stitching重要的part也有如下问题:
Depth parallax:即画面存在深度视差。如果场景画面不是纯平面,则使用1个Homography不能让图像准确匹配。(Mesh Warps可以解决,后续有空更新一手)
Quality of image features:即Homography非常依赖图像的特征质量,因为它的工作基于特征点。(Deep Homography解决,即下面提到的)
RANSAC challenge:Homography会依赖RANSAC算法的鲁棒度,如果RANSAC失败,对齐工作也相应失败。
一、Deep Image Homography Estimation
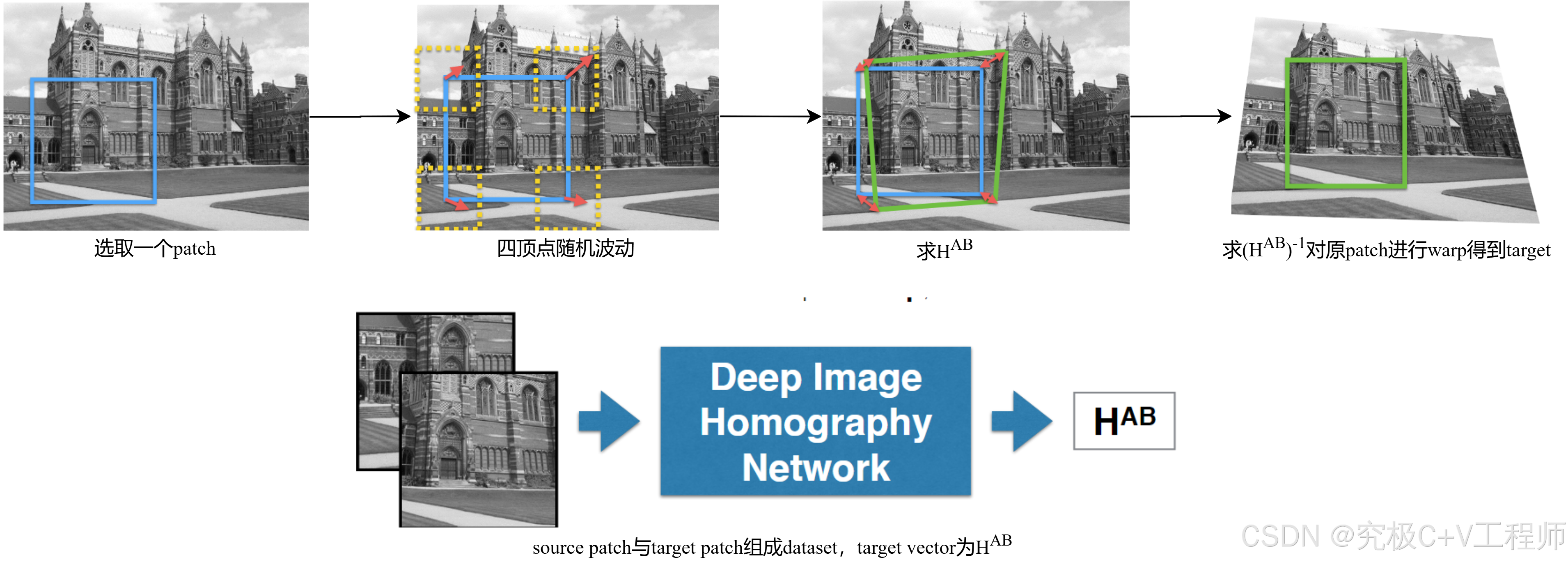
数据准备:他是一个supervised learning的过程,因此需要guidance,作者在这里首先对图片选取了一个patch,四个顶点在一定范围随机波动得到target,sourece与target正好构成四组点对可以进行求解,之后逆运算就可以得到target patch,最终信息即可组成dataset来进行Deep Hmography的estimation。如下图所示:
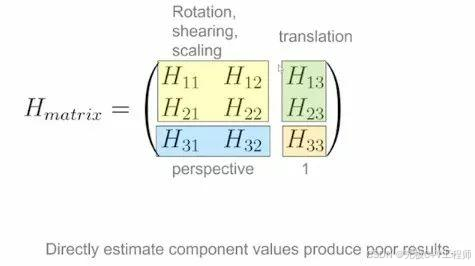
关于homography估计细节:因为不同区域代表的线性变换不同,即存在量纲问题。
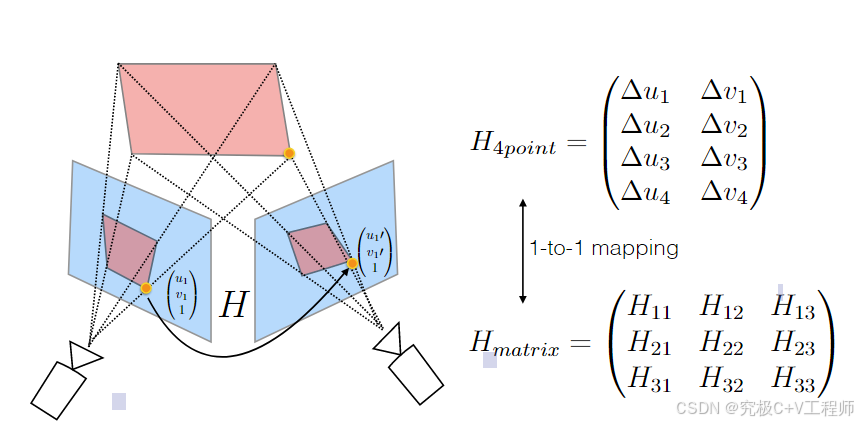
作者在这里用相对位移的估计代替homography的估计,对这2个点作差得到位移向量,使用4个顶点的位移向量就可以等效表示homography。与其回归homography中的8个参数,不如回归4个顶点的位移向量 。
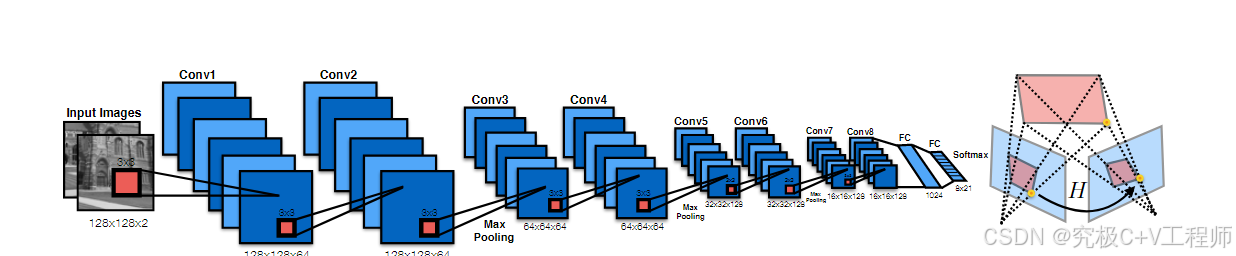
网络架构:经典VGG-style的CNN网络。3×3 conv layer+BN+ReLu构成的convblock,kernel size分别为64, 64, 64, 64, 128, 128, 128, 128,最后使用Fully connected layer(第一个全连接层有 1024 个cell。在最终的卷积层和第一个全连接层之后应用概率为 0.5 的 Dropout。)做连接。
同时基于损失函数以及最后一层的Fully connect的维度将网络分成了Classification Homography Net 与 Regression Homography Net.结构如下:
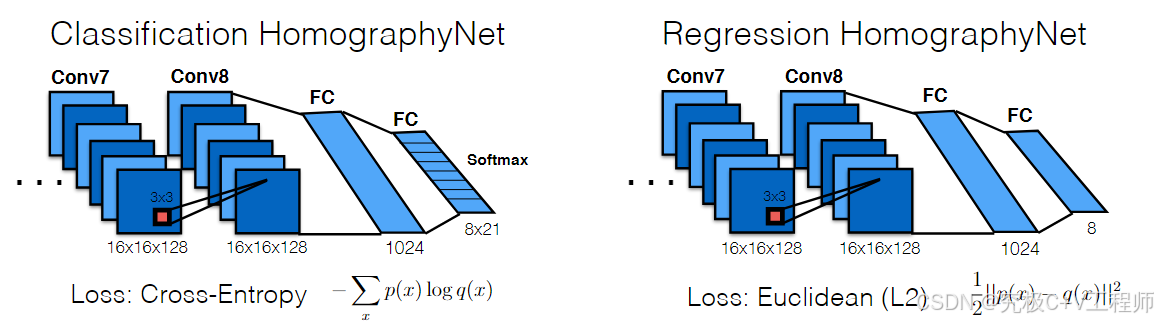
主要差别,分类网络对四个点进行了离散量化,作者将每个角点的二维偏移量的取值范围用离散的方式进行表示。具体来说:将连续的的
取值范围分成21个固定的区间(称为"量化区间"或"quantization bins")。
二、Unsupervised Deep Homography
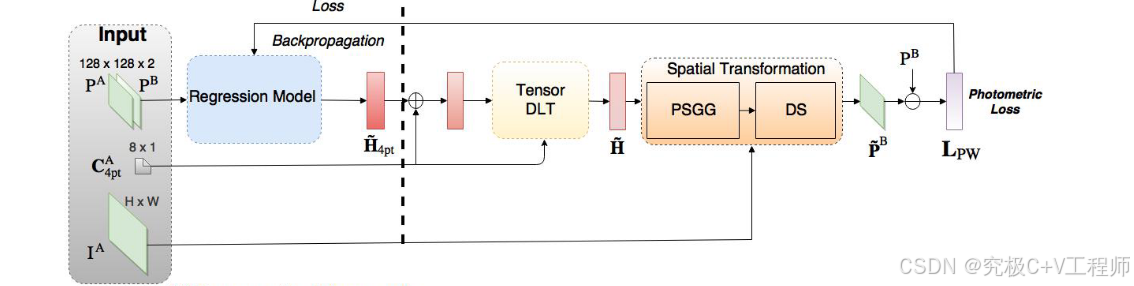
一种典型无监督学习方法,我大概看了下,实际跟UDIS作者的思路很相像,这里先说作者的思路,利用regression model进行偏移矩阵求解,之后与
相加得到最终矩阵之后与原始矩阵进行DLT,之后STN对
操作得到
,最后与
进行Loss求解。Loss公式:
不过UDIS作者是直接给出辅助矩阵M来进行求解DLT,通过类FPN结构进行三张特征图的生成,且在不同层次的特征进行进一步卷积,并求解DLT,同时通过空间变换(STN)逐层对齐,通过对齐操作,让特征图在每一阶段的误差逐步减小,使后续网络的输入更加精确。UDIS作者用的L1范数之前查阅文献,有印象看到了一句话,说的是L1范数在进行stitching问题处理上优势更大。大体来看思路上还是非常的相似。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









