






上一篇写了如何在DataGrip上使用hive的数据源编写Spark代码的部署流程
一般来说错误有两种
1.hive或者spark的安装配置有问题,须自行解决
上一篇种使用的时linux集群三台机器搭建了spark_Yarn模式以及hive远程模式
如果配置相同,可以参考
如何在DataGrip上使用hive的数据源编写sparksql![]() https://blog.youkuaiyun.com/qq_62049041/article/details/1435777122.配置文件错误
https://blog.youkuaiyun.com/qq_62049041/article/details/1435777122.配置文件错误
(1)、一直连接不上datagrep
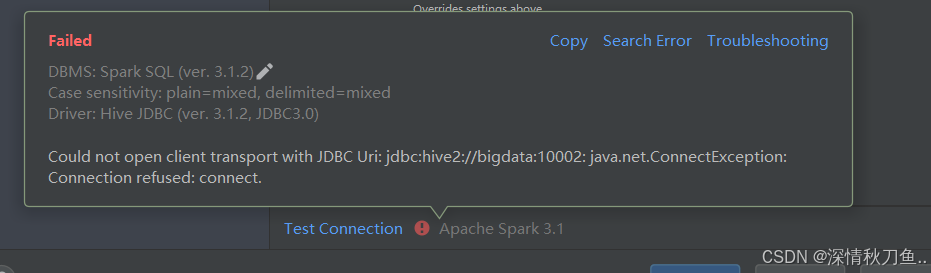
这个是连接的端口号配置有问题
可能的原因在hive下的hive-site.xml里就直接配置了
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>然后保留下来了,会导致你的端口号只能是10001
运行以下代码启动spark远程服务的时候配置不会生效
/opt/installs/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=bigdata \
--master yarn \
--conf spark.sql.shuffle.partitions=2其次连接不上还可能是因为没有将spark下的hive-site.xml分发出去
其他机器上没有会导致连接不上hive的数据源
还有编辑完配置以后没有重新启动
关闭thrift服务:
/opt/installs/spark/sbin/stop-thriftserver.sh启动:
/opt/installs/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=bigdata \
--master yarn \
--conf spark.sql.shuffle.partitions=2
















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









