







事先需要下载
!pip install -U langchain-community
!pip install -U langchain
!pip install -U pyPDF
!pip install tiktoken
!pip install langchain_openai
!pip install unstructured
!pip install gradio相关代码
from langchain.document_loaders import UnstructuredURLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
url='https://news.sina.com.cn/zx/gj/2024-12-20/doc-ineaarnv9239635.shtml'
def url3News(url):
text_splitter=RecursiveCharacterTextSplitter(separators=["正文","统筹"],chunk_size=1000,chunk_overlap=20,length_function=len)
loader=UnstructuredURLLoader(urls=[url])
data=loader.load_and_split(text_splitter=text_splitter)
return data[1:2]
new_data=url3News(url)
print(new_data)
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from pydantic import BaseModel,Field
from langchain.output_parsers import PydanticOutputParser
class Line(BaseModel):
character:str =Field(description="说这句台词的角色的名字")
content:str = Field(description="台词的具体内容,其中不再包括角色的名字")
class XiangSheng(BaseModel):
script:list[Line]=Field(description="一段相声的台词剧本")
def news2scripte(new_data):
prompt_template = """总结这段新闻的内容:
"{text}"
总结:"""
chinese_template = PromptTemplate(template=prompt_template, input_variables=["text"])
llm = ChatOpenAI(base_url="http://chatapi.littlewheat.com/v1", openai_api_key="",max_tokens=1500)
# Use map_prompt and combine_prompt instead of prompt
chain = load_summarize_chain(llm, chain_type="map_reduce", map_prompt=chinese_template, combine_prompt=chinese_template)
summary = chain.run(new_data)
openaichat=ChatOpenAI(base_url="http://chatapi.littlewheat.com/v1", openai_api_key="",max_tokens=1500)
template="""\
我将给你一段新闻的概况,请按照要求把这段新闻改写成郭德纲和于谦的对口相声剧本
新闻:{新闻}
要求:{要求}
{output_instructions}
"""
parser=PydanticOutputParser(pydantic_object=XiangSheng)
prompt=PromptTemplate(template=template,input_variables=["新闻","要求"],partial_variables={"output_instructions":parser.get_format_instructions()})
msg=[HumanMessage(content=prompt.format(新闻=summary,要求="风趣幽默,十分讽刺,剧本对话角色为郭德纲和于谦,以他们的自我介绍为开头"))]
res=openaichat(msg)
xiangsheng=parser.parse(res.content)
return xiangsheng
re=news2scripte(new_data)
print(re)封装
def url2xiangsheng(url):
doc=url3News(url)
xiangsheng=news2scripte(doc)
return xiangsheng交互界面
import gradio as gr
with gr.Blocks() as demo:
url = gr.Textbox()
chatbot = gr.Chatbot()
submit_btn = gr.Button("生成相声")
def generate_conversation(url):
xiangsheng: XiangSheng = url2xiangsheng(url)
chat_history = []
def parse_line(line: Line):
if line is None:
return ""
return f"{line.character}:{line.content}"
for i in range(0, len(xiangsheng.script), 2):
line1 = xiangsheng.script[i]
line2 = xiangsheng.script[i+1] if (i+1) < len(xiangsheng.script) else None
chat_history.append((parse_line(line1), parse_line(line2)))
return chat_history
submit_btn.click(fn=generate_conversation, inputs=url, outputs=chatbot)
demo.launch()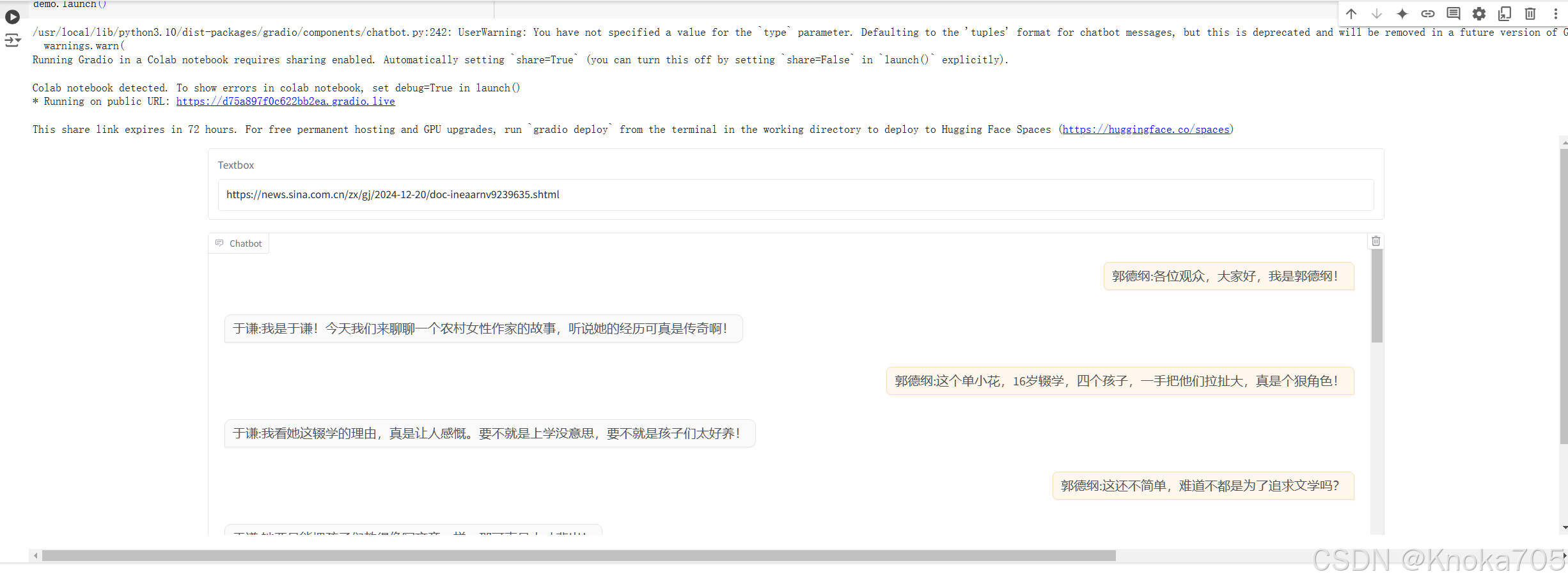



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











