






opencv银行卡号识别是对学习opencv,个个操作的总结与检验,对于银行卡号识别需要用到大部分所学知识,以及对opencv的一系列图像处理操作;更能够有进一步的理解。
大致思路如下:
1、建立银行卡数字识别的标准模版,处理模板图片,将每个模板数字单独提取出来
2,准确定位银行卡卡号的数字区域
3、通过图像处理,分割等一系列操作,将银行卡每个卡号数字单独提取出来形成待测试区域
4、通过模板匹配来找到最大相似度的图像,识别每个卡号,从而得出银行卡号
# 读取模板图片
img_m = cv2.imread("tu.jpg")
img_m_g = cv2.cvtColor(img_m,cv2.COLOR_BGR2GRAY)
# 反二值化处理,常见的二值图像一般前景为白色,背景为黑色
img_m_g = cv2.threshold(img_m_g,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY_INV)[1]
# 查找图像的轮廓
img_m_g_con = cv2.findContours(img_m_g,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)[0]
img_m_g_dst = cv2.drawContours(img_m.copy(),img_m_g_con,-1,(0,0,255),2)
plt.imshow(img_m_gdst[:,:,::-1])
plt.show()
对银行卡处理如下:
def cv_show(img,windows="fig"):
cv.imshow(windows,img)
cv.waitKey(0)
cv.destroyWindow(windows)
img=cv.imread('card.jpg')
#转换颜色空间,便于后续处理
img_gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
plt.imshow(img_gray,cmap=plt.cm.gray)
plt.show()
#cv_show(img_gray)
#图像阈值处理为二值图像,然后进行反阈值处理
ret1,img_threshold=cv.threshold(img_gray,20,255,cv.THRESH_BINARY)
# plt.imshow(img_threshold,cmap=plt.cm.gray)
# plt.show()
ret2,re_img_threshold=cv.threshold(img_threshold,20,255,cv.THRESH_BINARY_INV)
plt.imshow(re_img_threshold,cmap=plt.cm.gray)
plt.show()
#
contours,hierarchay=cv.findContours(img_threshold,cv.RETR_LIST,cv.CHAIN_APPROX_NONE)
#
# mask=cv.drawContours(img,contours,-1,(0,0,255),5)
# plt.imshow(mask[:,:,::-1])
# plt.show()
x,y,w,h=cv.boundingRect(contours[0])
bound_img=cv.rectangle(img_threshold, (x,y), (x+w,y+h), (0,255,0), 2)
plt.imshow(img_threshold,cmap=plt.cmgray)
plt.show()

(不便展示)
对进行银行卡找到数字区域进行一系列图像的形态学操作,然后绘图找到带识别区域,进行图像分割(我感觉对于银行卡的数字区域应该都是在特定的一个范围内,如果这样的话可以设定一个大多数银行卡卡号的一个图像的区域,当然对于不同的图像大小可能不同这会导致识别出现错误,甚至不能进行,但是在实际中我们可以在特定的摄像距离下,得到大小相近的照片,可以通过放缩处理图像的大小进行识别,这样可以直接判断出来减少大部分操作,直接可以分割梳理数字图像进进行模版匹配,用字典储存信息最后打印出keys即可)
#求图像梯度或使用Canny边缘检测,
grady = cv2.Sobel(tophat,ddepth = cv2.CV_32F,dx=0,dy=1,ksize = 3)
grady = cv2.convertScaleAbs(grady)
# imshow(grady)
gradx = cv2.Sobel(tophat,ddepth = cv2.CV_32F,dx=1,dy=0,ksize=3)
gradx = cv2.convertScaleAbs(gradx)
# imshow(gradx)
grad = cv2.addWeighted(gradx,0.5,grady,0.5,0)
imshow(grad)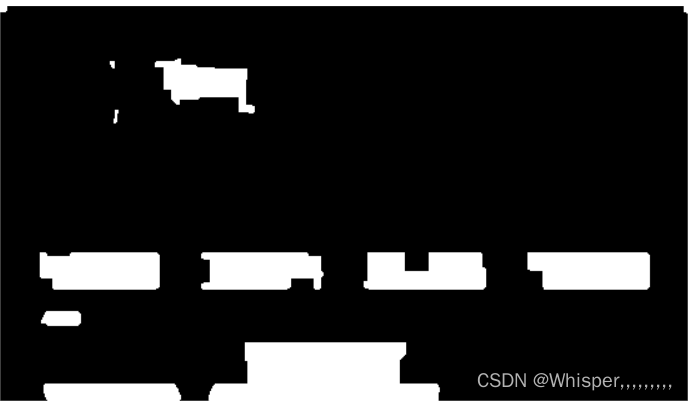
digital = []
def f(img):
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img_2 = cv2.threshold(img_gray,0,255,cv2.THRESH_OTSU)[1]
imgcon = cv2.findContours(img_2,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)[0]
new_con = []
 ************************************
************************************
for con in imgcon:
(x,y,w,h) = cv2.boundingRect(con)
if h>35 or w<15:
continue
new_con.append((x,y,w,h)
sort_con = sorted(new_con,key = lambda x:x[0])
for i in sort_con:
x,y,w,h = i[0],i[1],i[2],i[3]
con = np.array([[[x,y],[x+w,y],[x+w,y+h],[x,y+h]]])
roi = img_2[y-1:y+h+1,x-1:x+w+1]
digital.append(cv2.resize(roi,(57,88)))
for i in img_part:
最后打印列表
【6,2,3,0,5,2,**************】
对于在识别的过程最主要的是个个API参数的设定怎样才能达到一个理想的效果

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









