






在小批量随机梯度下降(Mini-batch Stochastic Gradient Descent, SGD)中,将梯度除以批量大小(batch_size)的主要原因是对梯度进行平均化处理,从而保持更新步伐的一致性。下面详细说明这个过程的原因和意义:
1. 梯度是损失函数的总和的导数
在机器学习中,模型的损失函数通常是关于整个数据集的。比如在最小化均方误差(MSE)时,损失函数的计算公式为:
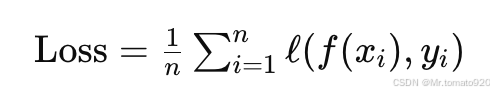
其中,n是数据集的大小,ℓ(f(xi),yi)\ell(f(x_i), y_i)ℓ(f(xi),yi) 是单个数据点的损失。为了高效计算,SGD 在每个迭代中并不是计算整个数据集的损失,而是基于一个小批量数据进行估计。假设批量大小为 batch_size,那么我们计算的损失是:
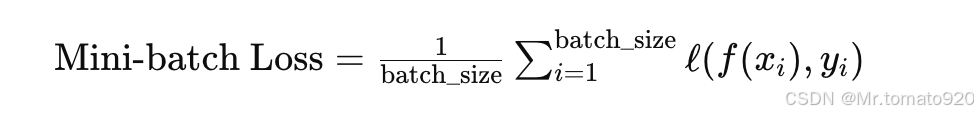
因此,梯度计算也是基于这部分小批量数据的总损失。不过,如果我们直接使用这个总梯度进行参数更新,梯度的大小将会与批量大小成正比。为了避免这个问题,我们需要将梯度除以 batch_size,即:
![]()
2. 梯度的平均化
梯度的大小与批量大小直接相关。假设我们没有除以 batch_size,那么当批量大小变大时,梯度的值也会随之增大,导致参数更新幅度过大,甚至可能导致优化过程不稳定。因此,我们需要对梯度进行平均化,以确保每次参数更新的步伐不依赖于批量大小:
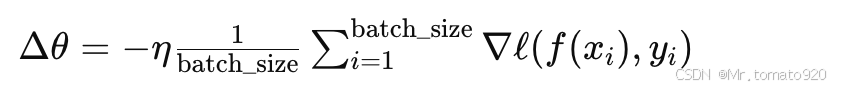
其中,η是学习率,θ 是模型的参数,Δθ\Delta \thetaΔθ 是参数更新值。通过这种方式,我们确保无论批量大小是多少,参数的更新幅度主要由学习率控制,而不是由批量大小决定。
3. 一致性和稳定性
除以 batch_size 还能带来以下几个好处:
- 保持一致性:当我们在不同的
batch_size设置下训练模型时,平均梯度能够保证学习率与批量大小无关,从而可以更容易地调节和设置学习率。 - 稳定性:如果不进行平均化,当
batch_size较大时,未归一化的梯度会使参数更新过大,可能导致模型在优化过程中发散;而当batch_size较小时,更新步伐又可能过小,导致收敛速度变慢。
4. 与全局梯度的关系
当我们使用小批量数据计算梯度时,实际上是对全局梯度的一种估计。如果小批量中的样本足够具有代表性,平均梯度会与整个数据集的梯度相近。因此,通过对小批量数据的梯度进行平均化处理,我们可以在更少的计算量下获得类似全局梯度的更新效果。
结论
在小批量随机梯度下降中,除以 batch_size 可以使梯度更新更加稳定,保持与批量大小无关的学习率调节效果,并有助于优化算法的收敛速度和稳定性。
梯度本质是损失函数loss的导数,模拟下山的方法,用参数params减去梯度除以batch_size
而不是除以全局样本量n,可以有效保证梯度下降的幅度不受小批量样本量batch_size的影响。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









