







目录
HashMap的数据结构(1.7和1.8的区别)
HashMap 是基于哈希表的 Map 接口实现的,以 key-value 存储形式存在。HashMap的实现不是同步的,也就是说,HashMap 不是线程安全的。除此之外,它的 key、value 都可以为null,而且 HashMap 中的映射不是有序的。
JDK1.8 之前的 HashMap 是由数组+链表组成的,数组是 HashMap 的主体,链表则是为了解决哈希碰撞而存在的。JDK7 链表中插入新结点的方式是头插法。
JDK1.8 之后的 HashMap 是由数组+链表+红黑树组成的,引入红黑树是为了更好的解决哈希碰撞,当链表长度大于阈值(或者红黑树的边界值,默认为8),并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。JDK8 链表插入新结点的方式是尾插法。
注:数组里面都是 key-value 的实例,在 JDK1.8 之前叫做 Entry,在 JDK1.8 之后叫做 Node。
将链表转换成红黑树前会判断,如果阈值大于8,但是数组长度小于64,此时并不会将链表变为红黑树。而是选择数组扩容。这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色等操作来保持平衡。同时数组长度小于64时,搜索时间相对快一些。
总结:
1、HashMap的 key-value 存取无序
2、键和值都可以为 null,但是键只能有一个为 null
3、键的位置是唯一的,是由底层的数据机构控制的
4、jdk1.8 之前的数据结构是:链表+数组,jdk1.8 之后的数据结构是:建表+数组+红黑树
5、阈值(边界值)> 8 并且数组长度大于64时,链表转换成红黑树,变成红黑树是为了更加高效的查询
HashMap的实现原理
HashMap中散列表数组初始长度
为什么 HashMap 的初始化容量为 16?

关于为什么 HashMap 的初始化容量为16,JDK官方并没有给出明确的解释,一般来说,既然要设置一个2^n的值,那么这个值应该不能太大,也不能太小,如果太大的话会造成空间的浪费,如果太小的话,频繁扩容会对效率造成影响,综合考虑就选择16来作为初始容量大小是比较合适的。
HashMap的默认负载因子
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
*默认的负载因子是0.75f,也就是75% 负载因子的作用就是计算扩容阈值用,比如说使用
*无参构造方法创建的HashMap 对象,他初始长度默认是16 阈值 = 当前长度 * 0.75 就
*能算出阈值,当当前长度大于等于阈值的时候HashMap就会进行自动扩容
*/为什么 HashMap 的默认负载因子是0.75,而不是0.5或者是1呢?
通常情况有两种答案:
1.阈值 = 负载因子 x 容量,根据 HashMap 的扩容机制,它会保证容量的值永远都是2 的次幂,为了保证负载因子x容量的结果是一个整数,这个值是0.75(3/4)是比较合理的,因为这个数和任何2的次幂乘积结果都是整数。
2.理论上来说,负载因子越大,导致哈希冲突的概论也就越大;负载因子越小,则浪费的空间越大。因此负载因子无论是大还是小,总是会有一定的弊端,为了能尽可能减小这个不足,可以采用折中的方式,一方面能降低哈希冲突的概率,另一方面不至于造成过多空间的浪费,所有将负载因子定为0.75比较合理。
HashMap的扩容机制
阈值 = 负载因子 x 容量
当 HashMap 中 table 数组长度大于等于阈值时就会自动进行扩容。扩容的规则如下:
table 数组的长度必须是2的n次方,所以扩容其实都是按照当前的 table 的长度为基准,例如当前 tableSize = 16,那么扩容之后的 tableSize = 32,需要注意的是,这里的32并不由原来的 tableSize x 2所得到的,而是由原来的 tableSize 左移一位得到。
HashMap扩容为什么是2^n-1
从前文我们已经知道HashMap的初始容量是16(2^4),每次扩容都是在原来的容量上增加一倍,扩容之后容量仍然是2次幂的形式。接下来我们分析一下为什么采取这种形式进行扩容,首先我们来看两段源码:

图一
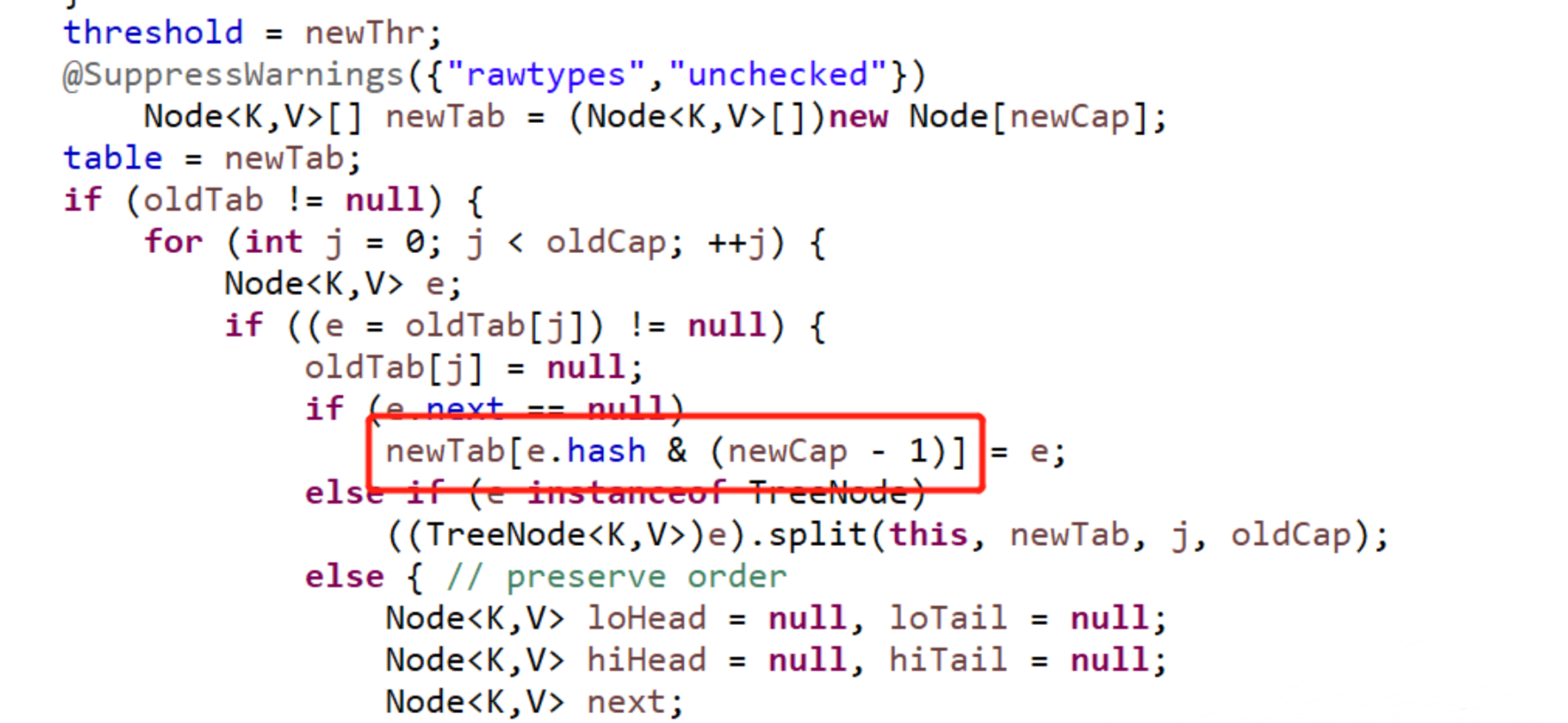
图二
图一是向 HashMap 中添加元素 putVal() 方法的部分源码,可以看到,向集合中添加元素时,每次都会使用(n-1) & hash,的计算方法来得到该元素在集合中的位置。图二是 HashMap 扩容时调用 resize() 方法中的部分源码,可以看到,首先会新建一个 tab,然后遍历旧的 tab,将旧的 tab 中的元素经过e.hash & (newCap - 1)操作,添加进新的 tab中,也就是(n-1) & hash的计算方法,其中 n 是集合的容量,hash 是添加的元素经过 hash 函数计算出来的 hash 值。
HashMap 的容量为什么是 2 的 n 次幂,与(n - 1) & hash的计算方法有着重要的联系," & "是按位与运算符号,属于位运算,计算机能够直接运行,特别高效,按位与 & 的计算方法是:只有当两个数的二进制数对应位置的上的数据都为 1 时,运算结果才为1。当 HashMap 的容量是 2 的 n 次幂时,(n-1) 的 2 进制也就是 111***111这样的形式,这样与添加元素的 hash 值进行位运算时,能够充分的散列,使得添加的元素均匀分布在 HashMap 的每个位置上,减少 hash 碰撞,下面举例说明。
当 HashMap 的容量是 16 时,它的二进制数是 10000,(n-1) 的二进制数是 01111,与hash 值的计算结果如下:
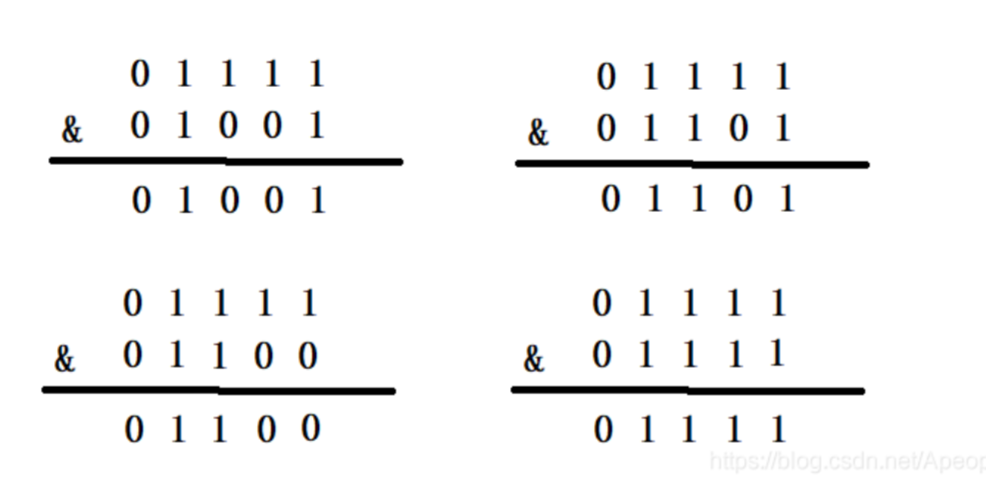
上面的四种情况我们可以看出,不同的 hash 值,和 (n-1) 进行位运算后,能够得出不同的值,使得添加的元素能够均匀分布在集合中的不同位置上,避免 hash 碰撞。下面我们再来看一下 HashMap 的容量不是 2 的 n 次幂的情况,假设容量为 10,则二进制为 01010,(n-1) 的二进制是 01001,我们再次用刚才的数据与 01001 进行按位与运算,结果如下:

可以看出,有三个不同的元素经过 & 运算却得到了相同的结果,出现了严重的 hash 碰撞。
总结:
HashMap 计算添加元素的位置时,使用的 & 运算是特别高效的运算,除此之外,HashMap 的初始容量是 2 的 n 次幂,扩容也是使用 2 倍的形式进行扩容,因为容量是 2 的 n 次幂可以使得添加的元素均匀分布在 HashMap 的数组上,减少 hash 碰撞,避免形成链表的结构。

















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









