







 本文是关于论文《Is Space-Time Attention All You Need for Video Understanding?》的阅读笔记,探讨了如何将Transformer扩展到视频理解,提出TimeSformer模型。TimeSformer通过时空注意力机制,包括联合空间时间注意力和分散注意力架构,实现了对视频的高效建模。实验显示,分散注意力架构在视频理解任务中表现出较高的精度和较低的计算成本,且能有效处理长期视频建模。
本文是关于论文《Is Space-Time Attention All You Need for Video Understanding?》的阅读笔记,探讨了如何将Transformer扩展到视频理解,提出TimeSformer模型。TimeSformer通过时空注意力机制,包括联合空间时间注意力和分散注意力架构,实现了对视频的高效建模。实验显示,分散注意力架构在视频理解任务中表现出较高的精度和较低的计算成本,且能有效处理长期视频建模。
目录
3.1experiment 1 不同架构在K400与SSv2的精度比较
3.2experiment 2 joint space-time和divided space-time的成本比较
3.4experiment 4增加帧数/增加patch个数对结果的影响
3.6experiment 6Long-Term Video Modeling验证
写在前面:
要从Transformer在NLP领域的一举成名说起,这种简单只使用注意力机制(attention)的结构在机器翻译等等方向都取得了不错的效果。顾名思义,这篇文章的方法基于Transformer提出了一种用于视频理解的框架,是Google提出的用于图像的Transformer-ViT(VisionTransformer)的扩展,将该方法命为TimeSformer(Time-Space Transformer)。
对于基本的Transformer不再赘述,对于 ViT进行简单介绍。ViT的目标是将标准 Transformer 直接应用于图片,做最少的修改,不做任何针对视觉任务的特定的改变。做法是将一幅图片(224*224)划分成很多 patches,每个 patch 元素 是 16 * 16,序列长度 14 * 14 = 196个元素。每一个 patch 经过一个 FC layer(fully connected layer)得到一个 linear embedding,但图片的 patches 是有顺序的,Patch embedding + position embedding == token ,包含 图片 patch 信息 和 patch 在原图中的位置信息。得到 tokens 之后,对其进行 NLP 操作。tokens 传入 Transformer encoder,得到很多输出。就将vision问题转化为NLP问题。
附ViT模型图:
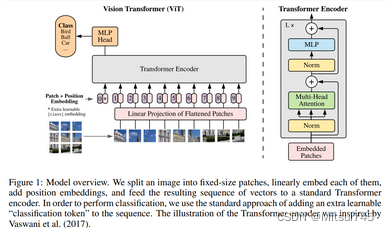
总结ViT
- 打通了 CV 和 NLP 之间的鸿沟
- 挖了一个更大的多模态的坑 视频、音频、基于 touch 的信号 各种 modality 的信号都可以拿来用
ViT证明了Transformer可以应用于图片,对于具有时空信息的视频,文章《Is Space-Time Attention All You Need for Video Understanding?》提出了几种基于时空容量(space-time volume)的可扩展自我注意设计结构。这其中最好的设计是“分散注意力(divided attention)”架构,它分别在网络的每个区块内应用时间注意力和空间注意力。
论文阅读笔记:
1.Introduction
视频理解任务和NLP的相同点:
- Sequential 连续性:视频和句子基本上都是连续的。
- Contextual 具有上下文联系:句子中某个单词的意思通常需要通过将其与句子中的其他单词联系起来来理解;对于视频来说,为了消除歧义,片段中的行为也需要与视频的其余部分结合起来。
所以,NLP的自注意模型可能会对视频建模有效。因为其不仅可以捕捉跨时序的依赖关系,还可以通过对不同空间位置的特征进行两两比较,从而揭示每一帧中的上下文信息。
尽管在GPU硬件加速方面取得了进步,但训练深度cnn仍然非常昂贵,特别是当应用于高分辨率和长视频时。基于这些观察结果,文章提出了一个完全建立在self-atention之上的视频架构。通过将自注意力机制从图像空间扩展到时空三维体积,将图像模型“Vision Transformer”(ViT)应用于视频。提出的模型名为“TimeSformer”,将视频视为从单个帧中提取的patches序列。与ViT一样,每个patch都被线性映射到一个embedding中,并添加了位置信息。
自我注意的一个缺点是,它需要计算所有tokens的相似性度量。由于视频中存在大量的patches,这一计算成本很高。为了解决这一问题,文章提出了几种可扩展的时空自我注意设计,并在大规模行动分类数据集上对它们进行了实证评估。在所提出的方案中,发现最佳设计由一个“divided attention”架构表示,该架构在网络的每个区块内分别应用时间注意和空间注意。它实现的精度可与该领域的最先进技术相媲美,而且在某些情况下更先进。实验还表明,模型可以用于持续数分钟的视频的long-range 建模。
2.TimeSformer model
2.1Joint Space-Time
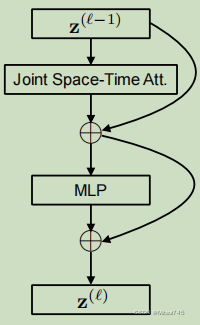
Input clip(模型输入):
![]()
代表F帧的RGB图像,每张图片尺寸为H×W。
![]()
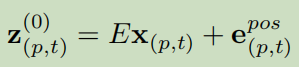
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









