









前言
常见的二进制文件特征码识别定位是基于硬编码指令定位、逻辑偏移量等方法,这种方法对于定位字符串等相对固定的数据非常友好。但是,对于编译程序中经常更新的组件,定位其中的指令代码就会因为版本更新而需要同步更新定位方法。文本介绍传统的特征码匹配算法,以及一种基于控制流程和函数调用链导向的特征码匹配定位方法,并从个人有限的角度去分析如何更好地选择特征码。(注:全文给出的都不是远程内存定位代码)
一、什么是特征码?
特征码是一串二进制字符串,可以用来定位数据、判断字段、识别病毒等。特征码通常是从文件或汇编代码中提取。特征码可以被杀毒软件用来扫描病毒,也可以被病毒用来修改或掩码,实现免杀。
二、如何选择特征码
2.1 传统的特征码选择方法
通常情况下,特征码的选择需要逆向工程手工分析目标指令段的上下文特征,并从中提取目标部分的指令字节。也有很多工具可以辅助提取文件的特征码。
一个软件厂商一般会随着更新,发布同一个程序的不同编译版本,这些二进制文件可以没有发生结构、指令的修改,也可能因为修复 BUG、扩展功能,而使得文件中被修改数据附近的数据发生显著变化。这就要求选取特征码时候,要尽可能精准,特征码要选取不易于变化的部分,同时又要兼顾与目标的距离。 为了提升效率,一般只会对修补版本进行新的分析,并根据文件版本号差异性定位目标指令。
例如下面的 Demo1 程序代码,程序实现输出 10~20 之间的数字。
#include <stdio.h>
int main()
{
// for 循环执行
for (int a = 10; a < 20; a++)
{
printf("a: %d \n", a);
}
return 0;
}这段代码编译之后,在 IDA 中反汇编如下:
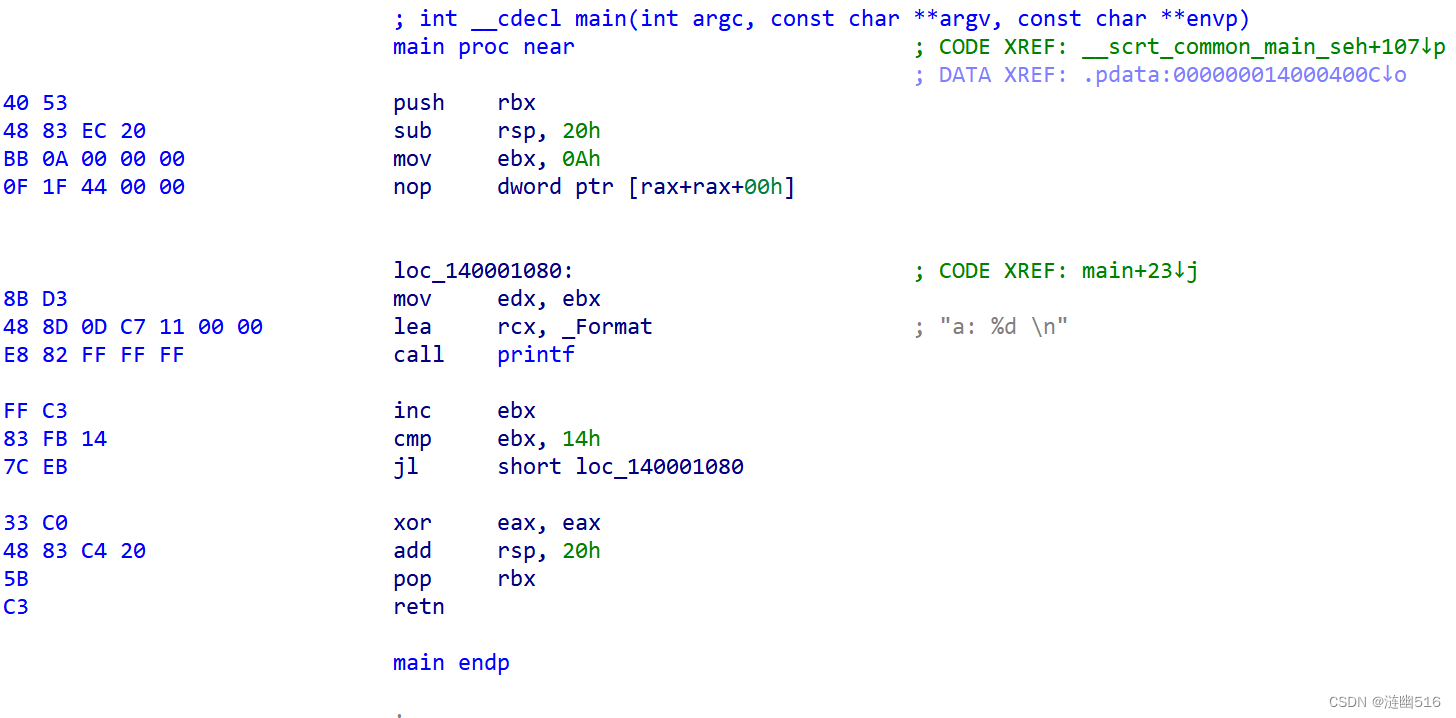
我们可以看到,如果我们想要修改这里循环中的的 call printf 指令,则需要匹配如下的特征码:
8B XX 48 8D XX XX XX XX XX E8 XX XX XX XX
这样子的特征可能存在很多干扰,尤其是对于复杂的程序,类似的函数调用方式可能存在多处。
比如下面的 Demo2 程序代码:
#include <stdio.h>
int main()
{
printf("Test StringB\n");
printf("Test StringA\n");
// for 循环执行
for (int a = 10; a < 20; a++)
{
printf("a: %d \n", a);
}
for (int b = 10; b < 20; b++)
{
printf("b: %d \n", b);
}
printf("Test StringC\n");
return 0;
}经过反汇编,我们可以观察到相似的指令序列:
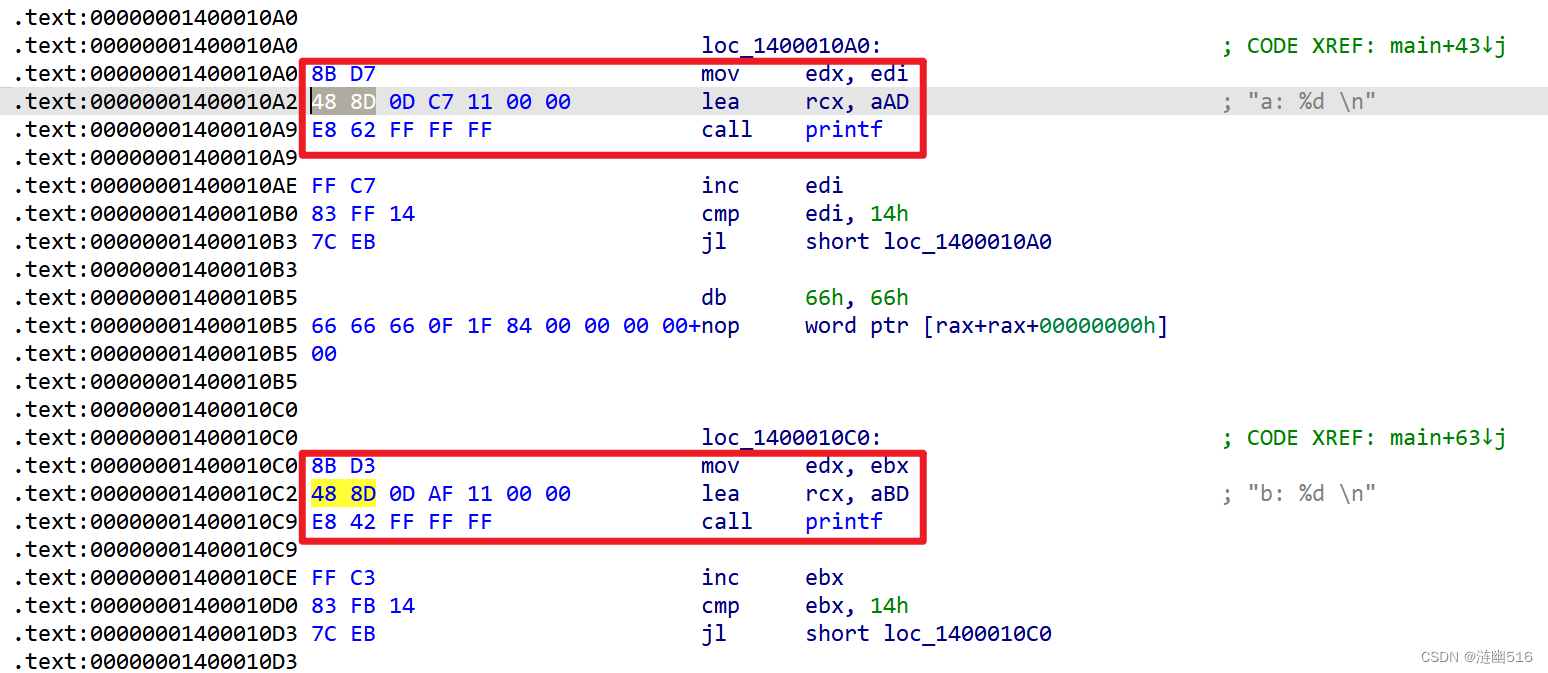
此时,我们可以按照匹配的顺序,来定位我们需要的那个位置,或者以函数的参数来判断我们需要定位的位置,或者结合多处特征码来确定需要的目标位置。
详细的程序特征码选择方法可以参考:详解定位特征码方法附带源码|kanxue.com。
下面摘录部分内容:
1)如果机器码序列对应的代码带有特殊的常量,并且这个常量不是目标程序的内存地址时,优先选取其为特征码。一般常量在程序中很少会改变。
例如如下为某函数的反汇编代码,获取这个函数的地址,选取"83 FE 2E 74 38"为特征码是比较合适的。-5 地址处就为函数起始地址。
$-5 > . 56 PUSH ESI ;函数地址
$-4 > . 8B7424 08 MOV ESI,DWORD PTR SS:[ESP+8]
$ ==> > . 83FE 2E CMP ESI,2E ;2e 为特殊常量
$+3 > . 74 38 JE 0BCCCCA2 ;短跳转
$+5 > . 83FE 2D CMP ESI,2D
$+8 > . 74 33 JE 0BCCCCA2
$+A > . 83FE 33 CMP ESI,33
2)优先选取带有短跳转的机器码序列作为特征码。因为只要选取的特征码以及从选取的特征码地址到跳转的地址之间随目标程序更新变化的概率较少,就可以作为定位用的特征码。例如上面的短跳转指令。
3)如果特征码带有结构体或者类变量的对应偏移的机器码序列,可以选取。一般只要结构体或者类变量不增加成员,就不会改变。
例如如下代码,要获取全局变量 "106d83b8"的地址,选取"88 46 40 74 45"为特征码是比较合适的。+0x22 偏移处就为目标全局变量地址。
$ ==> > 8846 40 MOV BYTE PTR DS:[ESI+40],AL ;结构体成员变量
$+3 > 74 45 JE 10572F00 ;短跳转指令
$+5 > 8B11 MOV EDX,DWORD PTR DS:[ECX]
$+7 > 8B42 30 MOV EAX,DWORD PTR DS:[EDX+30]
$+A > 53 PUSH EBX
$+B > 8B1D AC406E10 MOV EBX,DWORD PTR DS:[106E40AC]
$+11 > FFD0 CALL EAX
$+13 > 83BB E4010000 0>CMP DWORD PTR DS:[EBX+1E4],0
$+1A > 894424 18 MOV DWORD PTR SS:[ESP+18],EAX
$+1E > 74 29 JE 10572EFF
$+20 > 8B0D B8836D10 MOV ECX,DWORD PTR DS:[106D83B8] ;目标全局变量
4)如果需要定位的位置没有满足以上条件的机器码序列,则可以采用特殊指令,且不带有绝对地址的机器码序列为特征码。
下面是某个程序的消息处理函数的代码,可以采用"53 55 8B 6C 24 2C 56 57 FF D2"为特征码。
$-19 >/$ 83EC 20 SUB ESP,20
$-16 >|. A1 6881E40B MOV EAX,DWORD PTR DS:[BE48168]
$-11 >|. 33C4 XOR EAX,ESP
$-F >|. 894424 1C MOV DWORD PTR SS:[ESP+1C],EAX
$-B >|. 8B0D 6007EA0B MOV ECX,DWORD PTR DS:[BEA0760]
$-5 >|. 8B01 MOV EAX,DWORD PTR DS:[ECX]
$-3 >|. 8B50 0C MOV EDX,DWORD PTR DS:[EAX+C]
$ ==> >|. 53 PUSH EBX ;特征码
$+1 >|. 55 PUSH EBP
$+2 >|. 8B6C24 2C MOV EBP,DWORD PTR SS:[ESP+2C]
$+6 >|. 56 PUSH ESI
$+7 >|. 57 PUSH EDI
$+8 >|. FFD2 CALL EDX
注意事项:
1)特征码中不能带有绝对地址。
2)特征码必须在对应模块中是唯一的,否则搜索到的特征码地址可能是错误的。
2.2 基于特征码的代码定位算法
在文件中对特征码的模糊匹配定位就是将模块的每一个字节读取到向量中,作为主串,用于定位的特征码作为模式串, 在主串中搜索和模式串字节完全一致的位置。这样,问题就转化为求解字符串快速搜索的问题。
字符串匹配搜索算法有很多,例如下面的:
- 朴素字符串匹配算法(Naive String Matching Algorithm):
也称为暴力搜索算法,是最简单的字符串匹配算法之一。
通过逐个比较文本中的字符与模式中的字符来进行匹配。
- Knuth-Morris-Pratt 算法(KMP Algorithm):
用于在一个文本串 S 内查找一个模式串 P 的出现位置。
利用模式串 P 的信息来避免文本串 S 中不必要的回溯。
- Boyer-Moore 算法:
一种高效的字符串搜索算法,尤其适用于大文本和小模式的情况。
通过对比文本和模式串的最后一个字符,跳过尽可能多的不匹配的字符。
- Rabin-Karp 算法:
一种基于哈希的字符串匹配算法。
将文本串中可能匹配的子串的哈希值与模式串的哈希值进行比较,以确定是否匹配。
- Aho-Corasick 算法:
用于在一个文本中查找多个模式串出现的位置。
构建了一个有限状态自动机(Finite State Machine),可以在线性时间内搜索文本串。
- Boyer-Moore-Horspool 算法:
Boyer-Moore 的变体,采用固定的步长进行跳跃。
在某些情况下,比标准的 Boyer-Moore 算法更快。
- Sunday 算法:
Boyer-Moore 的改进版本,采用模式串中最后一个字符在模式串中从右往左查找的结果作为移动距离。
简化了 Boyer-Moore 算法中的坏字符规则。
- Shift-And 算法:
一种适用于固定模式串的位操作算法。
将模式串转换成位向量,利用位运算进行匹配。
其中,比较常见的算法有 BF 算法、 KMP 算法、Sunday 算法、BM 算法等。下面我将逐一介绍这三种算法。
1)BF 暴力搜索
暴力搜索就是两个循环,主串和子串一一比较的过程。
举例( Demo 3 ):比如对于 winlogon.exe 可执行模块,通过 IDA 我们知道要想拦截到该进程的消息回调,可以通过找到 WMsgClntInitialize 作为切入点。这个函数的反汇编如下:
int64_t __fastcall WMsgClntInitialize(WLSM_GLOBAL_CONTEXT *WSMGlobalContext, int IsPresentKey)
{
int64_t WMsgHandlerList[9]; // [rsp+30h] [rbp-48h] BYREF
memset(WMsgHandlerList, 0, 0x40);
if ( !IsPresentKey )
return StartWMsgServer();
WMsgHandlerList[0] = (int64_t)WMsgMessageHandler;
WMsgHandlerList[1] = (int64_t)WMsgKMessageHandler;
WMsgHandlerList[5] = (int64_t)WMsgNotifyHandler;
WMsgHandlerList[2] = (int64_t)WMsgPSPHandler;
WMsgHandlerList[3] = (int64_t)WMsgReconnectionUpdateHandler;
WMsgHandlerList[4] = (int64_t)WMsgGetSwitchUserLogonInfoHandler;
RegisterWMsgServer(WMsgHandlerList);
return StartWMsgKServer(*WSMGlobalContext + 0xCC);
}他有什么特征呢?就是这里的函数指针表,它的汇编非常有规律:
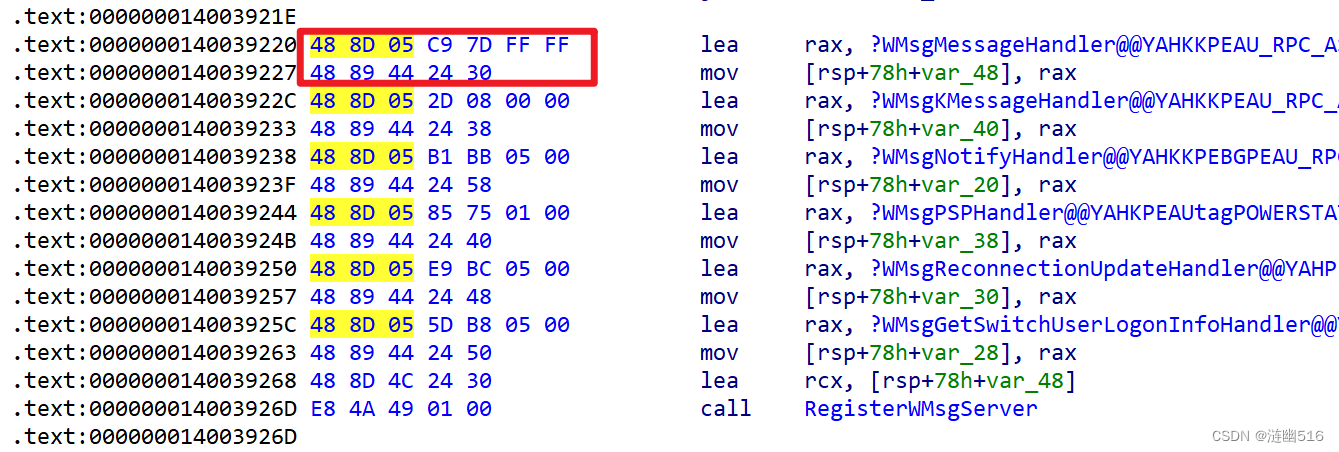
这里通过将栈上的函数指针通过 lea 指令传入地址到 rax 上,再通过 mov 数据传输指令来准备后面函数的调用需要用到的参数。
- lea rax, 0x0 对应机器码序列是: { 0x48, 0x8D, 0x05, 0, 0, 0, 0 };
- mov [rsp + 0x0], rax 对应机器码序列是: { 0x48, 0x89, 0x44, 0x24, 0 }
你可以观察出这里的代码可以总结为一个不变的签名特征:
{ 0x48, 0x8D, 0x05, 0, 0, 0, 0, 0x48, 0x89, 0x44, 0x24, 0 } X~3
注意:0 表示可变值, X~3 表示重复次数不小于 3 次。
因为 winlogon.exe 的代码编写习惯,所有的回调函数都在这里注册。虽然单次匹配特征码在全文中存在多处,但是这样的连续重复匹配特征码超过 3 次的有且仅有一处。
所以,当使用少于 15 字节且没有明显对称特征的模式串进行定位的时候,可以优先使用 BF 算法。
下面代码是暴力搜索特征码的一个模板,算法支持设置只返回第一个结果:
#include <stdio.h>
#include <windows.h>
#include <vector>
#include <Psapi.h>
#include <time.h>
inline int BFTracePatternInModule(
LPCWSTR moduleName,
PBYTE pattern,
SIZE_T patternSize,
DWORD dwRepeat,
DWORD dwSelect = 1
)
{
if (pattern == 0 || moduleName == 0 || patternSize == 0 || dwRepeat <= 0)
{
return 0;
}
HMODULE hModule = LoadLibraryW(moduleName);
if (hModule == nullptr) {
printf("Failed to load module: %ws.\n", moduleName);
return 0;
}
MODULEINFO moduleInfo;
if (!GetModuleInformation(GetCurrentProcess(), hModule, &moduleInfo, sizeof(moduleInfo))) {
printf("Failed to get module information.\n");
FreeLibrary(hModule);
return 0;
}
std::vector<uint64_t> vcMachList;
BYTE* moduleBase = reinterpret_cast<BYTE*>(hModule);
SIZE_T moduleSize = moduleInfo.SizeOfImage;
printf("模块基址:%I64X.\n", reinterpret_cast<uint64_t>(hModule));
printf("模块大小:%I64d Bytes.\n", moduleSize);
if (moduleSize == 0)
{
printf("Failed to get module information.\n");
FreeLibrary(hModule);
return 0;
}
uint64_t thisMatch = 0;
DWORD SelectCase = (dwSelect < 256) && dwSelect ? dwSelect: 256; // 最大结果记录次数
SIZE_T MatchLimit = patternSize * dwRepeat - 1; // 连续重复匹配次数限制
int cwStart = clock();
if (dwRepeat == 1)
{
for (SIZE_T i = 0; i < moduleSize - patternSize; i++)
{
thisMatch = 0;
SIZE_T j = 0;
for (j; j < patternSize - 1; j++)
{
if (moduleBase[i + j] != pattern[j] && pattern[j] != 0u)
{
break;
}
}
if (j == patternSize - 1)
{
if (moduleBase[i + j] == pattern[j] || pattern[j] == 0u)
{
thisMatch = i;
SelectCase--;
vcMachList.push_back(thisMatch);
if(!SelectCase) break;
}
}
}
}
else {
for (SIZE_T i = 0; i < moduleSize - MatchLimit - 1; i++)
{
thisMatch = 0;
SIZE_T j = 0;
for (j; j < MatchLimit; j++)
{
if (moduleBase[i + j] != pattern[j % patternSize] && pattern[j % patternSize] != 0u)
{
break;
}
}
if (j == MatchLimit)
{
if (moduleBase[i + MatchLimit] == pattern[patternSize - 1] || pattern[patternSize - 1] == 0u)
{
thisMatch = i;
SelectCase--;
vcMachList.push_back(thisMatch);
if (!SelectCase) break;
}
}
}
}
int cwEnd = clock();
for (SIZE_T i = 0; i < vcMachList.size(); i++)
{
printf("匹配到模式字符串位于偏移: [0x%I64X] 处,动态地址:[0x%I64X]。\n",
vcMachList[i], reinterpret_cast<uint64_t>(moduleBase) + vcMachList[i]);
}
if (vcMachList.size() == 0)
{
printf("No Found.\n");
}
FreeLibrary(hModule);
return cwEnd - cwStart;
}
int main() {
// 暴力算法
const wchar_t* moduleName = L"winlogon.exe";
BYTE pattern[] =
{ 0x48u, 0x8Du, 0x05u, 0, 0, 0, 0, 0x48u, 0x89u, 0x44u, 0x24u , 0 };
SIZE_T patternSize = 12;
DWORD dwRepeat = 3, dwSelect = 1;
int TimeCost = 0;
TimeCost = BFTracePatternInModule(moduleName, pattern, patternSize, dwRepeat, dwSelect);
printf("算法耗时:%d ms.\n", TimeCost);
return 0;
}测试的效果如下,可以稳定在 3ms 耗时内。
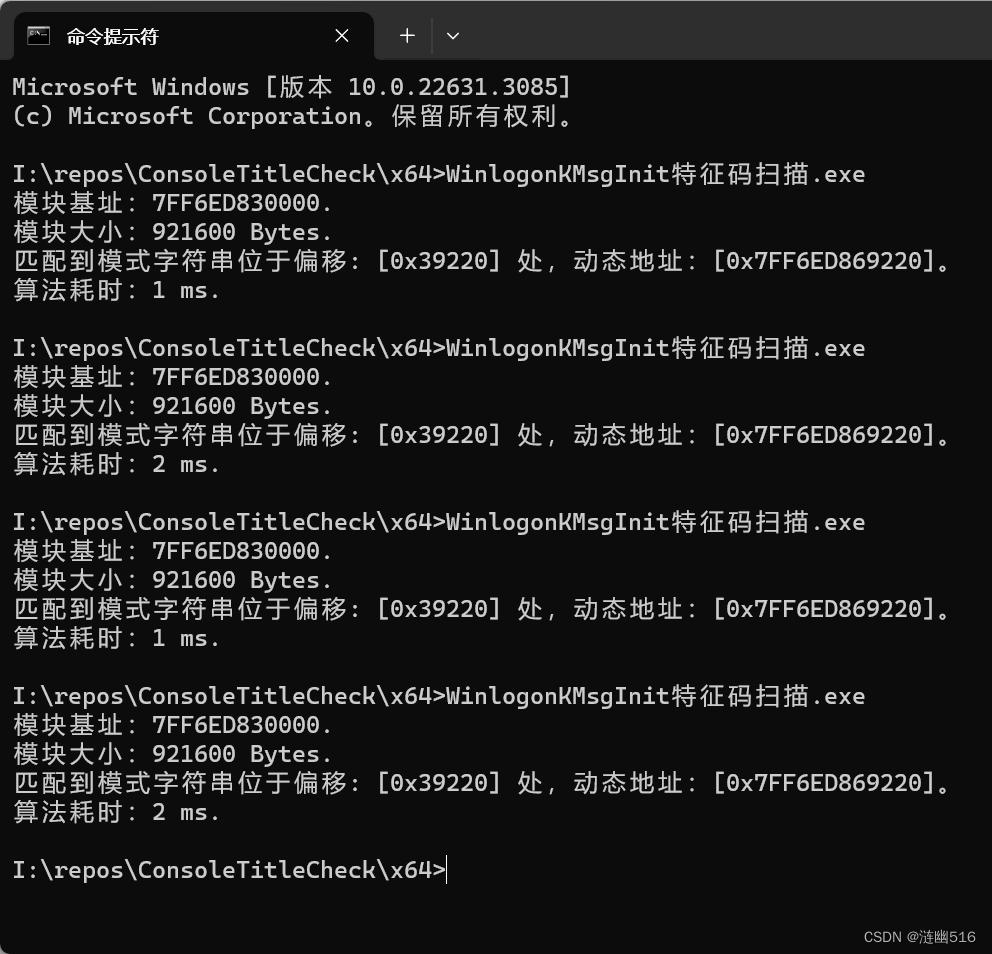
下面就是欢愉的检验环节了:
首先设置 IDA 的模块加载基址,使其和测试环境对齐(Edit > Segments > Rebase Program):
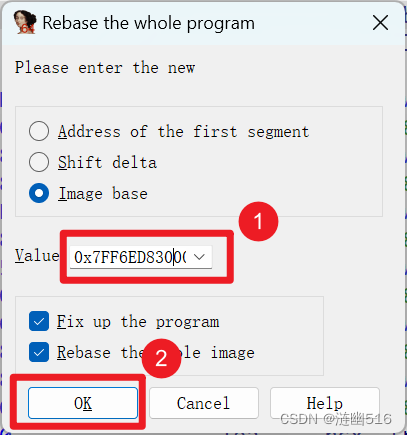
随后,地址对齐被修正了,和算法计算的结果一致:
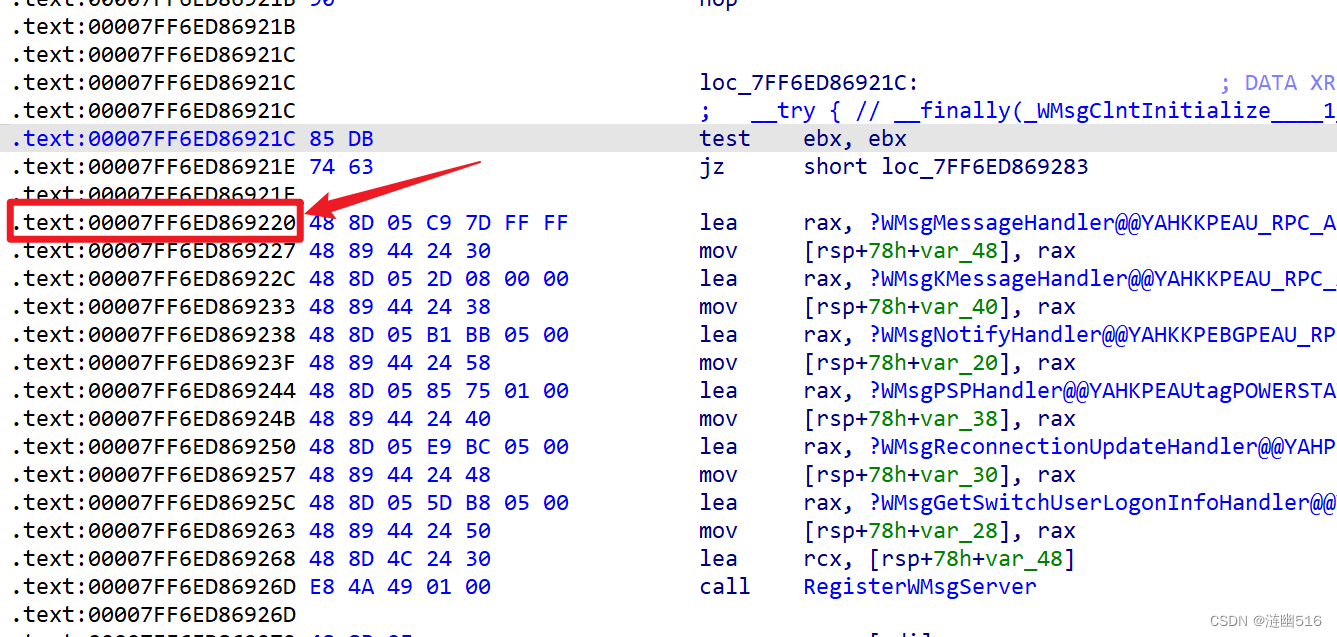
说明算法没有失误。
2) KMP 算法
KMP 算法是 D.E.Knuth、J.H.Morris 和 V.R.Pratt 共同提出的,简称 KMP 算法。该算法较 BF 算法有较大改进,主要是消除了目标串指针的回溯,从而使算法效率有了某种程度的提高。
算法原理就不多说了,网上资料很多(B 站)。下面给出求解该问题的模板代码:
#include <iostream>
#include <Windows.h>
#include <vector>
#include <string>
#include <Psapi.h>
#include <sstream>
#include <iomanip>
/* P 为模式串,下标从 0 开始 */
void GetNextval(std::vector<BYTE> SubString, SSIZE_T nextval[])
{
SSIZE_T SubStringLen = SubString.size();
SSIZE_T i = 0;
SSIZE_T j = -1;
nextval[0] = -1;
while (i < SubStringLen)
{
if (j == -1 || SubString[i] == SubString[j])
{
i++; j++;
if ((SubString[i] != SubString[j] && SubString[j] != 0x00))
nextval[i] = j;
else
nextval[i] = nextval[j];
}
else
{
j = nextval[j];
}
}
}
/* 在 MainString 中找到 SubString 所有出现的位置 下标从0开始*/
void KMPSearchString(
PBYTE MainString,
SIZE_T bufferSize,
std::vector<BYTE> SubString,
DWORD dwListSize,
std::vector<SSIZE_T>& matches
)
{
SSIZE_T next[100] = { 0 };
GetNextval(SubString, next);
SSIZE_T MainStringIndex = 0; // 存储主字符串下标
SSIZE_T SubStringIndex = 0; // 存储子字符串下标
SSIZE_T MainStringLen = bufferSize; // 主字符串大小
SSIZE_T SubStringLen = SubString.size(); // 子字符串大小
// 循环遍历字符串,因为末尾 '\0' 的存在,所以不会越界
while (MainStringIndex < MainStringLen)
{
// MainString 的第一个字符不匹配或 MainString[] == SubString[]
if (SubStringIndex == -1 ||
MainString[MainStringIndex] == SubString[SubStringIndex] ||
SubString[SubStringIndex] == 0x00)
{
MainStringIndex++; SubStringIndex++;
}
else // 当字符串匹配失败则跳转
{
SubStringIndex = next[SubStringIndex];
}
// 最后匹配成功直接返回位置
if (SubStringIndex == SubStringLen)
{
if (dwListSize == matches.size()) return;
matches.push_back(MainStringIndex - SubStringIndex);
SubStringIndex = next[SubStringIndex];
}
}
}
int main(int argc, char* argv[])
{
std::string pattern = "48 8D 05 ?? ?? ?? ?? 48 89 44 24 ?? 48 8D 05 ?? ?? ?? ?? 48 89 44 24 ?? 48 8D 05";
std::vector<SSIZE_T> matches;
const wchar_t* moduleName = L"winlogon.exe";
HMODULE hModule = LoadLibraryW(moduleName);
if (hModule == nullptr) {
printf("Failed to load module: %ws.\n", moduleName);
return 0;
}
MODULEINFO moduleInfo;
if (!GetModuleInformation(GetCurrentProcess(), hModule, &moduleInfo, sizeof(moduleInfo))) {
printf("Failed to get module information.\n");
FreeLibrary(hModule);
return 0;
}
std::vector<BYTE> patternBytes;
std::istringstream iss(pattern);
std::string byteStr;
while (iss >> byteStr) {
if (byteStr == "??") {
patternBytes.push_back(0x00); // Placeholder for "??" in the pattern
}
else {
int byteValue;
std::istringstream(byteStr) >> std::hex >> byteValue;
patternBytes.push_back(static_cast<BYTE>(byteValue));
}
}
uint64_t moduleBase = reinterpret_cast<uint64_t>(hModule);
ULONG moduleSize = moduleInfo.SizeOfImage;
printf("模块基址:%I64X.\n", reinterpret_cast<uint64_t>(hModule));
printf("模块大小:%ld Bytes.\n", moduleSize);
int start = clock();
KMPSearchString(
reinterpret_cast<BYTE*>(moduleBase),
moduleSize, patternBytes,
1, // 限制只搜索第一个结果
matches);
int end = clock();
printf("用时:%d ms.\n", end - start);
if (matches.size() == 0)
{
printf("搜索失败,找不到模式字符串。\n");
system("pause");
return 0;
}
for (SIZE_T i = 0; i < matches.size(); i++) {
printf("[%I64d] 匹配到模式字符串位于地址:0x%I64X\n",
i, moduleBase + matches[i]);
}
system("pause");
return 0;
}
这里的代码参考了该文章:内存遍历与KMP特征搜索 - lyshark - 博客园。为适应当前需求,本文使用的代码有所改动。
定位结果如下:
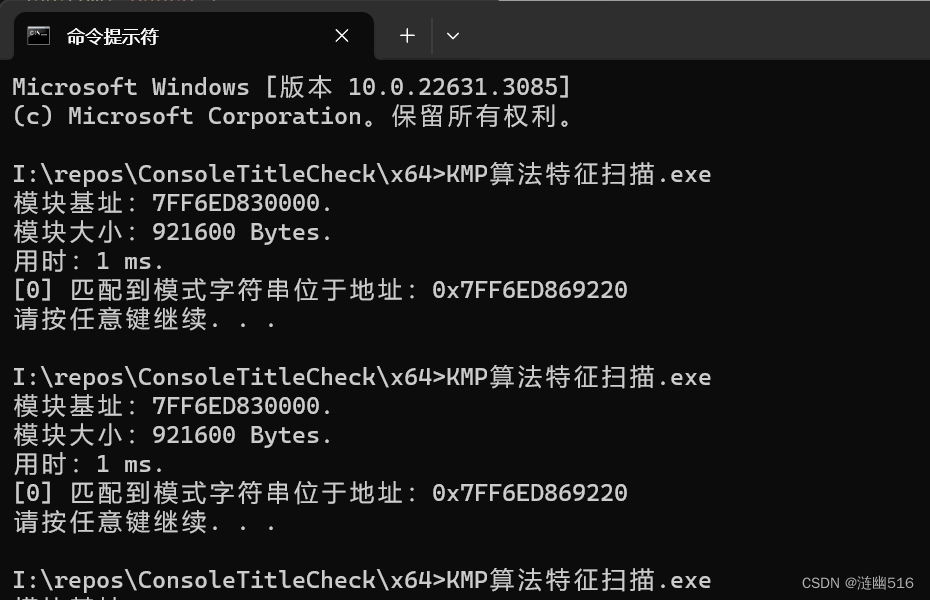
注意:KMP 算法在模式字符串长度比较小的情况下(<10 字节),匹配分布不均匀的多个地址效果可能不如 BF 和 Sunday 算法。 但是,三个算法查找首次匹配的模式字串效果很接近。
3)Sunday 算法
Sunday 算法是一种用于字符串匹配的算法,它在某些情况下可以比传统的字符串匹配算法(如暴力搜索、KMP 算法等)更快。Sunday 算法的主要思想是利用字符不匹配时的信息来跳过尽可能多的字符比较。
对于特征码(签名)在 PE 文件中的匹配,Sunday 算法的效率可能取决于特征码的长度、特征码在文件中的位置分布、以及文件的大小等因素。如果特征码较短且分布均匀,那么 Sunday 算法可能会有比较高的匹配效率,因为它可以通过尽可能多的跳过字符比较来加快搜索速度。然而,如果特征码较长或者分布不均匀,Sunday 算法的效率可能会降低,因为它可能需要进行更多的字符比较来找到匹配。
求解该问题的代码如下:
#include<Windows.h>
#include<iostream>
#include<vector>
#include<time.h>
#include <Psapi.h>
using namespace std;
#define BLOCKMAXSIZE 409600 // 每次读取内存的最大大小
BYTE* MemoryData;// 每次将读取的内存读入这里
short Next[260] = { 0 };
// 特征码转字节集
SIZE_T GetpatternArray(PCHAR strPattern, WORD* patternArray)
{
int len = 0;
SIZE_T strPatternLength = strlen(strPattern) / 3 + 1;
for (int i = 0; i < strlen(strPattern); )// 将十六进制特征码转为十进制
{
char num[2] = { 0 };
num[0] = strPattern[i++];
num[1] = strPattern[i++];
i++;
if (num[0] != '?' && num[1] != '?')
{
int sum = 0;
WORD a[2] = { 0 };
for (int i = 0; i < 2; i++)
{
if (num[i] >= '0' && num[i] <= '9')
{
a[i] = num[i] - '0';
}
else if (num[i] >= 'a' && num[i] <= 'z')
{
a[i] = num[i] - 87;
}
else if (num[i] >= 'A' && num[i] <= 'Z')
{
a[i] = num[i] - 55;
}
}
sum = a[0] * 16 + a[1];
patternArray[len++] = sum;
}
else
{
patternArray[len++] = 256;
}
}
return strPatternLength;
}
// 获取 Next 数组
void GetNext(short* next, WORD* strPattern, SIZE_T strPatternLength)
{
// 特征码(字节集)的每个字节的范围在0-255(0-FF)之间,256用来表示问号,到260是为了防止越界
for (int i = 0; i < 260; i++)
next[i] = -1;
for (int i = 0; i < strPatternLength; i++)
next[strPattern[i]] = i;
}
// 搜索一块内存
void SearchMemoryBlock(
WORD* strPattern,
SIZE_T strPatternLength,
uint64_t StartAddress,
SIZE_T bufferSize,
SIZE_T ListLimit,
vector<uint64_t>& ResultArray
)
{
memcpy(MemoryData, (LPCVOID)StartAddress, bufferSize);
for (SIZE_T i = 0, j, k; i < bufferSize; )
{
j = i; k = 0;
for (; k < strPatternLength && j < bufferSize && (strPattern[k] == MemoryData[j] || strPattern[k] == 256); k++, j++);
if (k == strPatternLength)
{
if (ResultArray.size() == ListLimit) return;
ResultArray.push_back(StartAddress + i);
}
if ((i + strPatternLength) >= bufferSize)
{
return;
}
int num = Next[MemoryData[i + strPatternLength]];
if (num == -1)
i += (strPatternLength - Next[256]);// 如果特征码有问号,就从问号处开始匹配,如果没有就i+=-1
else
i += (strPatternLength - num);
}
}
// 搜索整个程序
SIZE_T SearchMemory(
PCHAR strPattern,
uint64_t StartAddress,
ULONG bufferSize,
SIZE_T ListLimit,
vector<uint64_t>& ResultArray
)
{
int i = 0;
SIZE_T strPatternLength = strlen(strPattern) / 3 + 1;
WORD* patternArray = new WORD[strPatternLength];
GetpatternArray(strPattern, patternArray);
GetNext(Next, patternArray, strPatternLength);
// 初始化结果数组
ResultArray.clear();
i = 0;
// 搜索这块内存
while (bufferSize >= BLOCKMAXSIZE)
{
SearchMemoryBlock(
patternArray, strPatternLength,
StartAddress + (BLOCKMAXSIZE * i),
BLOCKMAXSIZE, ListLimit, ResultArray);
if (ResultArray.size() == ListLimit) return ResultArray.size();
bufferSize -= BLOCKMAXSIZE; i++;
}
SearchMemoryBlock(
patternArray, strPatternLength,
StartAddress + (BLOCKMAXSIZE * i),
bufferSize, ListLimit, ResultArray);
free(patternArray);
return ResultArray.size();
}
int main()
{
// 初始化 MemoryData 大小
MemoryData = new BYTE[BLOCKMAXSIZE];
vector<uint64_t> ResultArray;
const wchar_t* moduleName = L"winlogon.exe";
HMODULE hModule = LoadLibraryW(moduleName);
if (hModule == nullptr) {
printf("Failed to load module: %ws.\n", moduleName);
return 0;
}
MODULEINFO moduleInfo;
if (!GetModuleInformation(GetCurrentProcess(), hModule, &moduleInfo, sizeof(moduleInfo))) {
printf("Failed to get module information.\n");
FreeLibrary(hModule);
return 0;
}
uint64_t moduleBase = reinterpret_cast<uint64_t>(hModule);
ULONG moduleSize = moduleInfo.SizeOfImage;
printf("模块基址:%I64X.\n", reinterpret_cast<uint64_t>(hModule));
printf("模块大小:%ld Bytes.\n", moduleSize);
if (moduleSize == 0)
{
printf("Failed to get module information.\n");
FreeLibrary(hModule);
return 0;
}
SIZE_T ListLimit = 1; // 返回结果个数限制
int start = clock();
SearchMemory(
(char*)"48 8D 05 ?? ?? ?? ?? 48 89 44 24 ?? 48 8D 05 ?? ?? ?? ?? 48 89 44 24 ?? 48 8D 05",
moduleBase,
moduleSize, ListLimit, ResultArray);
int end = clock();
printf("用时:%d ms.\n", end - start);
printf("搜索到 %ld 个结果, 要求搜索前 %ld 个匹配项。\n", ResultArray.size(), ListLimit);
for (vector<uint64_t>::iterator it = ResultArray.begin(); it != ResultArray.end(); it++)
{
printf("匹配到模式字符串位于地址:[0x%I64X]。\n", *it);
}
return 0;
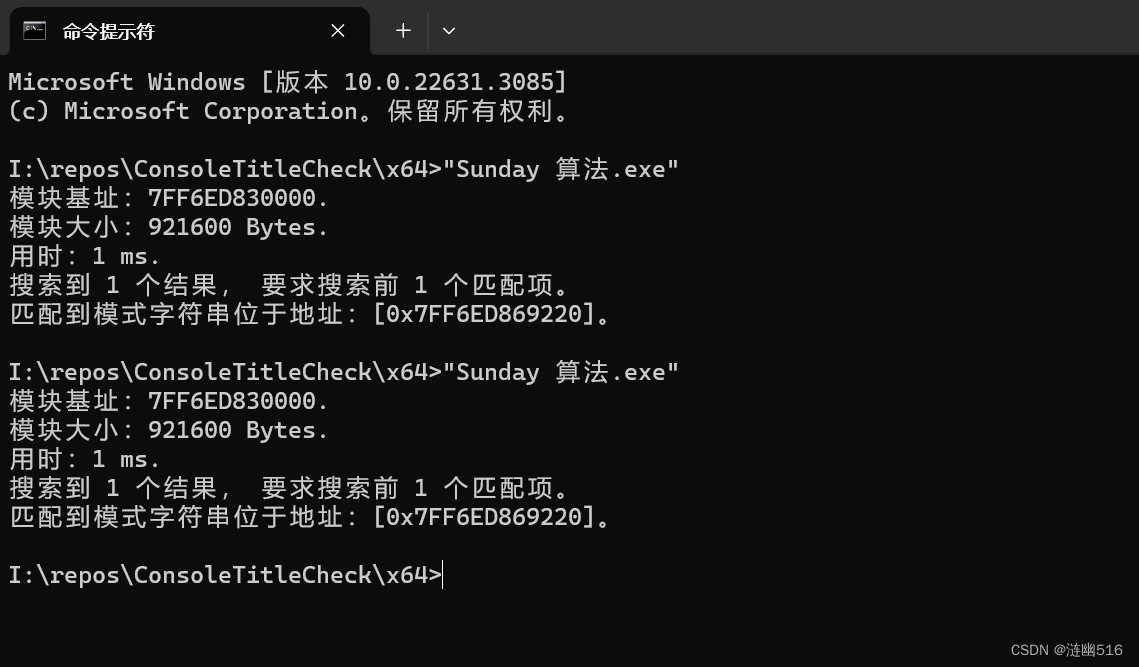
}测试结果如图,时间上不超过 1ms。在只匹配首次结果时,略快于 BF 、KMP 算法;在匹配全部结果时,远快于 KMP 算法。
4)BM 算法
各种文本编辑器的"查找"功能(Ctrl+F),大多采用 Boyer-Moore算法。Boyer-Moore 算法不仅效率高,而且构思巧妙,容易理解。1977 年,德克萨斯大学的 Robert S. Boyer 教授和 J Strother Moore 教授发明了这种算法。该算法的原理讲解可以参考:字符串匹配的 Boyer-Moore 算法 - 阮一峰。
下面是测试数据和代码,检查主串中是否包含模式串,按照道理转换为实际测试的代码应该比 KMP 快不少。
测试数据
BYTE str[] = { 0x12, 0x23, 0x45, 0x48u, 0x8Du, 0x05u, 0x25, 0x12, 0x23, 0x45, 0x48u, 0x89u, 0x44u, 0x24u , 0x56 };
BYTE pattern[] = { 0x48u, 0x8Du, 0x05u, 0, 0, 0, 0, 0x48u, 0x89u, 0x44u, 0x24u, 0 };
BM 代码(支持通配符,string 转 BYTE 数组的代码可以见我前面给出的其他算法代码):
#include <iostream>
#include <string>
#include <Windows.h>
using namespace std;
#define ASIZE 256 // ASCII 字母的种类
// 1. 坏字符数组建立,类似于字典(map),用于判断坏字符在 pattern 中的位置
void generateBC(PBYTE str, SSIZE_T strlen, SSIZE_T bc[]) {
for (int i = 0; i < ASIZE; i++) {
bc[i] = -1;
}
for (SSIZE_T i = 0; i < strlen; i++) {
bc[str[i]] = i;
}
}
// 2. 好后缀数组的建立, suffix 为后缀字符对应前面的位置, prefix 存储:是否存在匹配的前缀字串
void generateGS(PBYTE str, SSIZE_T strlen, SSIZE_T suffix[], bool prefix[]) {
SSIZE_T n = strlen;
for (SSIZE_T i = 0; i < n - 1; i++) {
suffix[i] = -1;
prefix[i] = false;
}
for (SSIZE_T i = 0; i < n - 1; i++) {
SSIZE_T j = i; // 从第一个字符开始遍历,str[j]
SSIZE_T k = 0; // 最后一个字符的变化,对应下面的 str[n - 1 - k]
while (j >= 0 && str[j] == str[n - 1 - k]) // 和最后一个字符对比,相等则倒数第二个
{
j--;
k++;
suffix[k] = j + 1; // 如果 k=1,则是一个字符长度的后缀对应匹配位置的值
}
if (j == -1) // 说明有前缀字符对应
prefix[k] = true;
}
}
// 3. 返回好后缀移动的次数,index 为坏字符位置-其后面就是好后缀,size 为 str 大小
SSIZE_T getGsMove(SSIZE_T suffix[], bool prefix[], SSIZE_T index, SSIZE_T size) {
SSIZE_T len = size - index - 1; // 好字符的长度,因为 index 为坏字符位置,所以要多减 1
if (suffix[len] != -1) // 当前 len 长度的后缀坏字符串前边有匹配的字符
{
return index + 1 - suffix[len]; // 后移位数 = 好后缀的位置(index + 1) - 搜索词中的上一次出现位置
}
// index 为坏字符,index+1 为好后缀,index+2 为子好后缀
for (SSIZE_T i = index + 2; i < size; i++) {
if (prefix[size - i]) // 因为 prefix 从 1 开始
return i; // 移动当前位置离前缀位置,acba-对应a移动3
}
return 0;
}
// 4. 返回找到匹配字符串的头,否则返回 -1
SSIZE_T BMSearchForModule(PBYTE str, PBYTE pattern, SIZE_T strLen, SIZE_T patternLen) {
SSIZE_T n = strLen;
SSIZE_T m = patternLen;
SSIZE_T bc[ASIZE]; // 坏字符数组
SSIZE_T* suffix = (SSIZE_T*)malloc(sizeof(SSIZE_T) * m);
bool* prefix = (bool*)malloc(sizeof(bool) * m);
long start = clock();
generateBC(pattern, strLen, bc);
generateGS(pattern, strLen, suffix, prefix);
SSIZE_T i = 0;
while (i <= n - m) {
SSIZE_T j = 0;
for (j = m - 1; j >= 0; j--) {
if (pattern[j] == 0) // 处理通配符
continue;
if (pattern[j] != str[i + j]) // 从后往前匹配 str 和 pattern
break;
}
if (j < 0)// 匹配结束
{
long end = clock();
printf("用时:%d ms.\n", end - start);
return i;
}
else {
SSIZE_T numBc = j - bc[str[i + j]]; // bc 移动的位数
SSIZE_T numGs = 0;
if (j < m - 1) // 最后一个字符就是坏字符,无需判断好字符
{
numGs = getGsMove(suffix, prefix, j, m); // Gs 移动的位数
}
i += numBc > numGs ? numBc : numGs;
}
}
return -1;
}
int main()
{
// 测试代码
BYTE str[] = { 0x12, 0x23, 0x45, 0x48u, 0x8Du, 0x05u, 0x25, 0x12, 0x23, 0x45, 0x48u, 0x89u, 0x44u, 0x24u , 0x56 };
BYTE pattern[] = { 0x48u, 0x8Du, 0x05u, 0, 0, 0, 0, 0x48u, 0x89u, 0x44u, 0x24u, 0 };
cout << BMSearchForModule(str, pattern, 15, 12) << endl;
return 0;
}运行结果如图,对应主串的索引确实是 3:
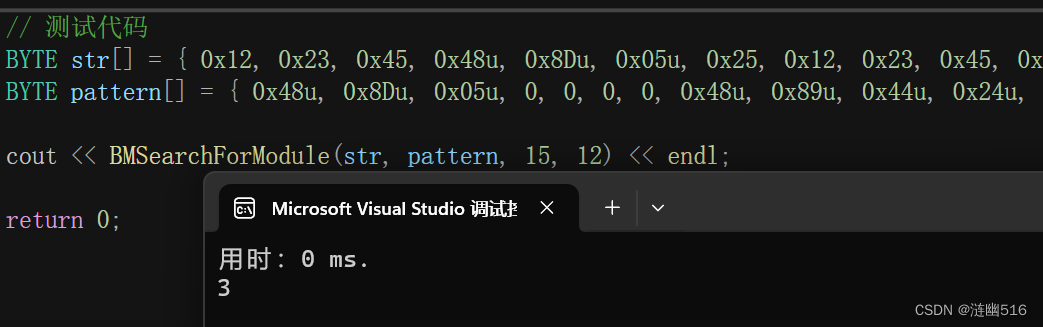
当然,实际问题求解过程中,需要选择恰当的算法,上文列举的只是最经典的几种算法模板。
2.3 基于控制流分析的特征码选择方法
控制流分析需要构建程序执行的控制流程图,并根据程序控制流程中的条件判断、分支、循环语句的特点,模拟程序执行的过程,并根据该过程链的导向,定位函数中目标指令。
Windows 的 Win32 API 属于导出函数,有很多导出函数是对内部调用细节进行二次封装的接口函数,由于隐藏了内部细节,内部函数可能实现更为复杂的功能,而导出的接口仅提供有限的功能。
提示:本文仅在测试环境下,提供学习目的使用的逆向细节和工具代码,使用未公开的接口和方法是微软不支持的行为,在实际发布软件中使用本文提供的测试代码需要开发者自行斟酌,或引起版权纠纷,本文作者概不负责。
(P.S. 其实,控制流程定位方法依赖于目标函数有调用方函数,并且调用方函数为导出函数这一条件。在大多数情况下由于分析过程复杂,不如一般的模式匹配特征码高效。目前该方法只是在学习过程中即兴想到的一种可行的定位方法,理论方面还很不成熟)
我们从 2.1 小节的 Demo2 程序挖掘,从这里可以看出 a 的数值是放在 edi 上的,调用 printf 时被复制到 edx 寄存器上,而这段 mov 指令在不同的优化模式下会有什么变化呢?
O2/ O1 优化:mov edx, edi
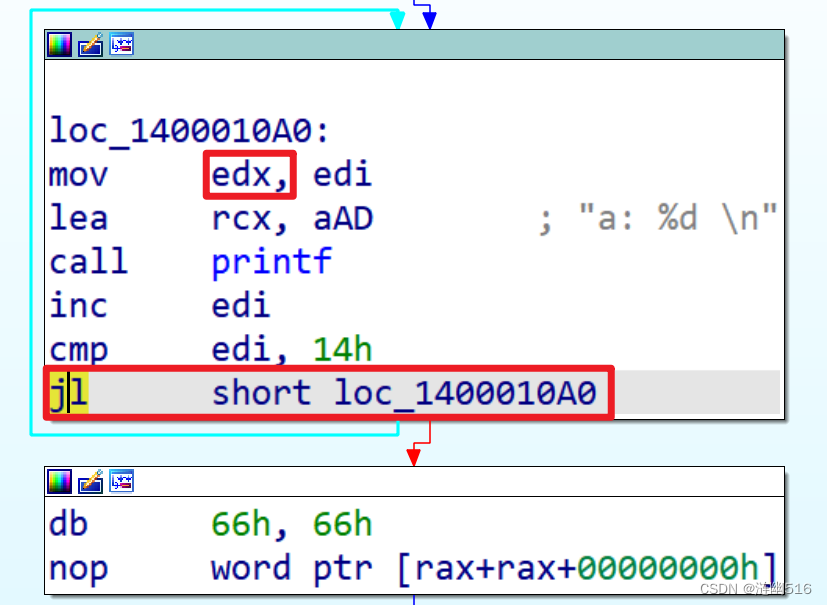
无优化:mov edx, [rsp+38h+var_18]
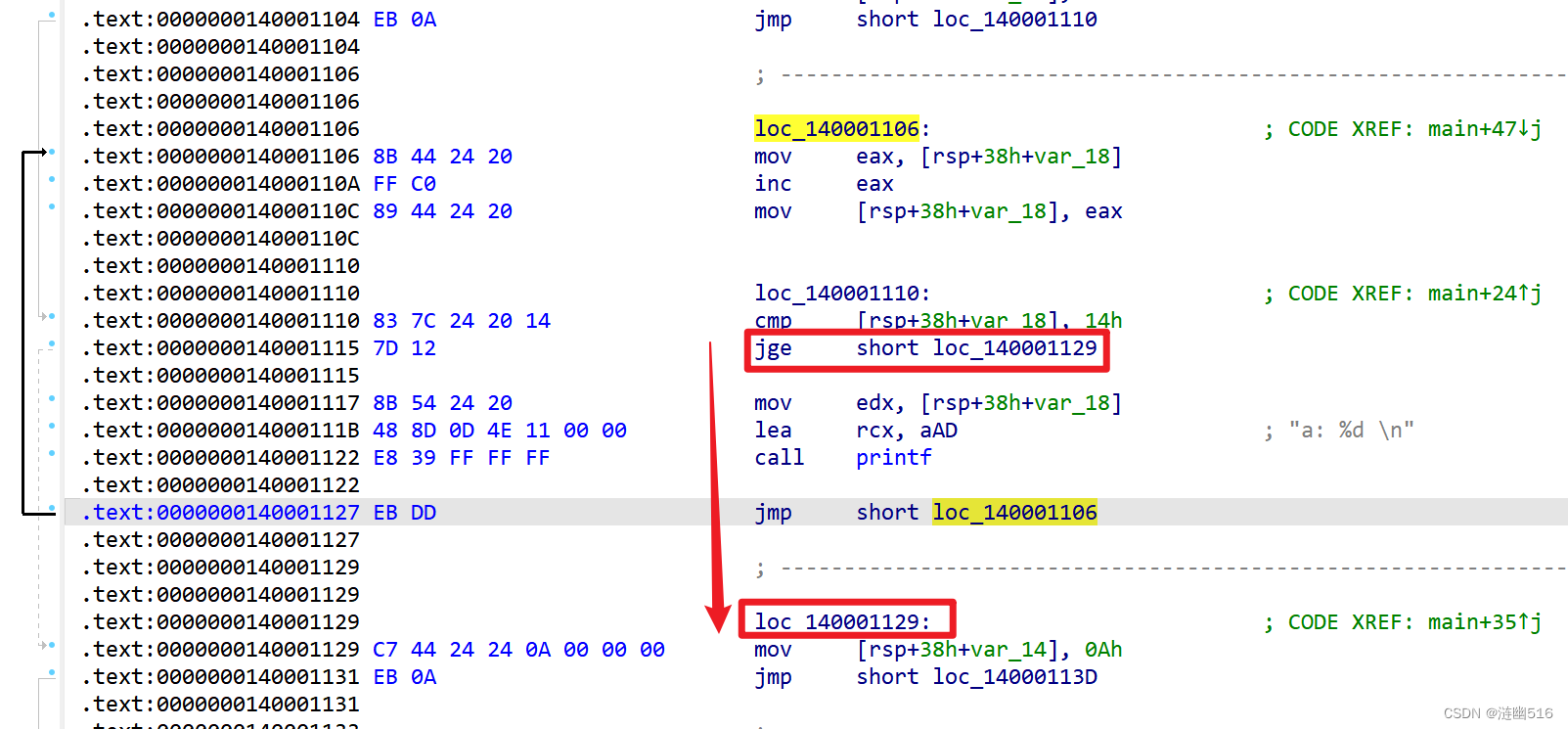
我们能够观察到,对于相对固定的 printf 的第一个参数,不同编译模式下都是 lea rcx, aAD.
而这条指令的前一条指令都是 mov 指令,不管你是优先寄存器传参还是从堆栈传参。但是 mov 指令的字节长度可能不同。
此时,我们考虑到存在循环外的 printf 和循环内的 printf,我们可以结合控制流的特征对搜索范围进行限制。如下图所示,我们可以首先在 main 函数内部一定范围内搜索 jmp 指令,并模拟真实的跳转,去计算跳转后的地址,跳转后的地址在目标范围的上届或者下界,这样可以在搜索时候越过一些指令字节。
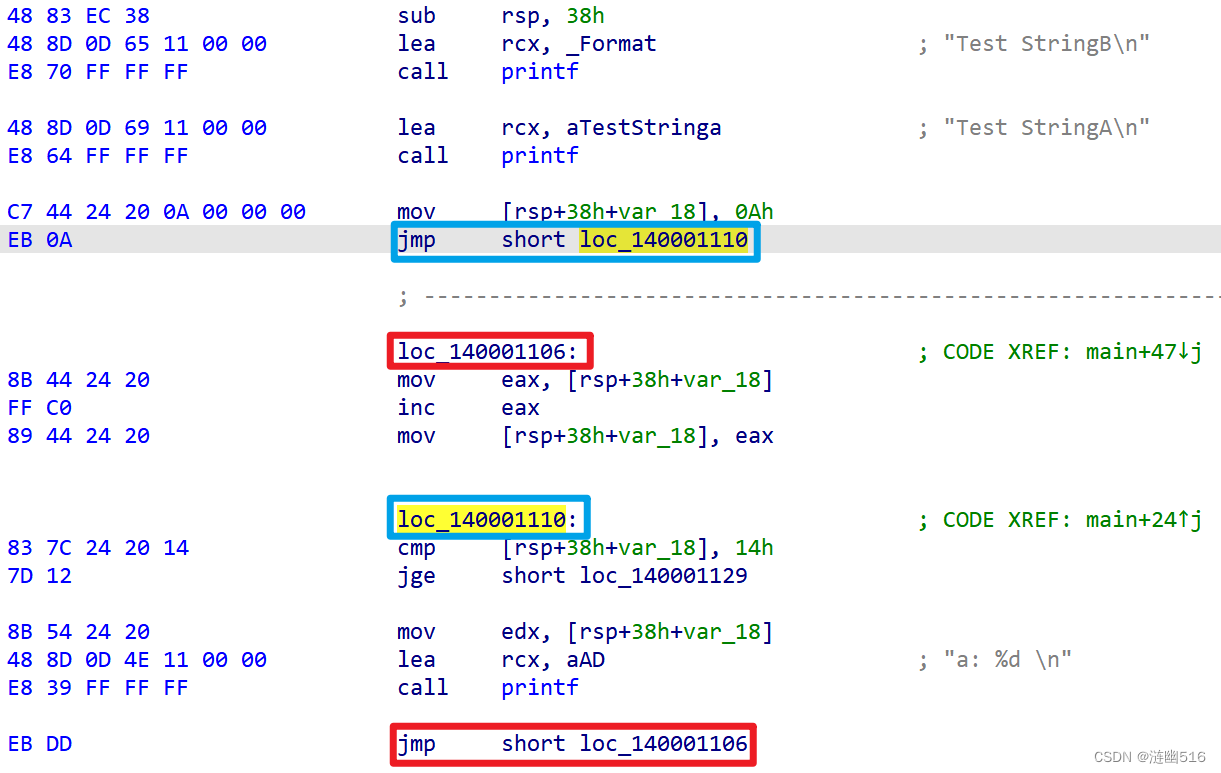
程序中,跳转地址常常被解释为分支,IDA 可以画出控制流程图:
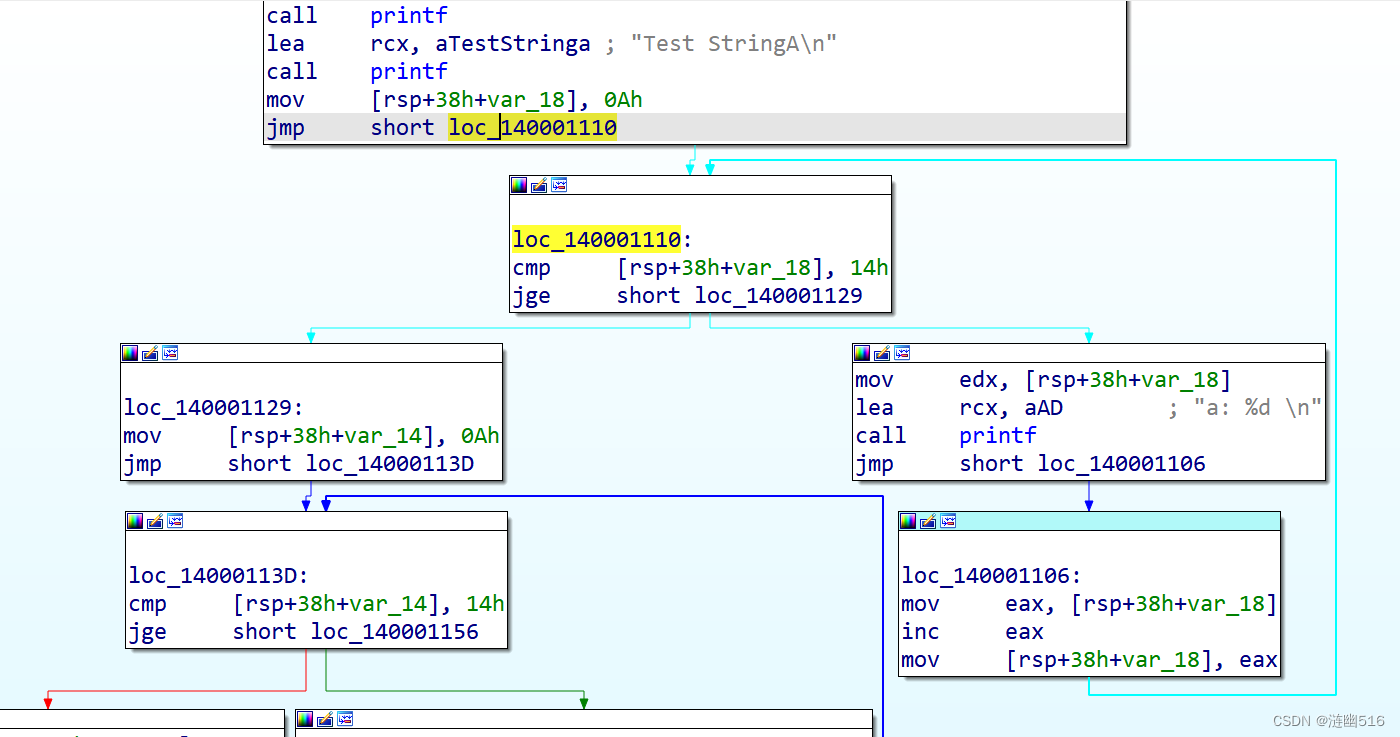
其实,上面的搜索逻辑结合控制流程和指令的特征,这种搜索其实就是基于对控制流程的理解来完成的。下面一节将利用一些 Windows API 来展示控制流程法定位的具体实现。
三、定位“消息框”接口函数
Windows 的消息框由 MessageBox 、MessageBoxEx、MessageBoxTimeout、MessageBoxIndirect 等实现。
而这些接口最终都是对 MessageBoxWorker 函数的封装,这个函数是未导出函数。
本文以 MessageBoxIndirectW 为例,分析如何通过该导出函数获取 MessageBoxWorker 函数的地址。
3.1 第一种情况(除了 Win 8/8.1 以外通用)
在 Windows 10/11 上, MessageBoxIndirectW 调用流程如下:
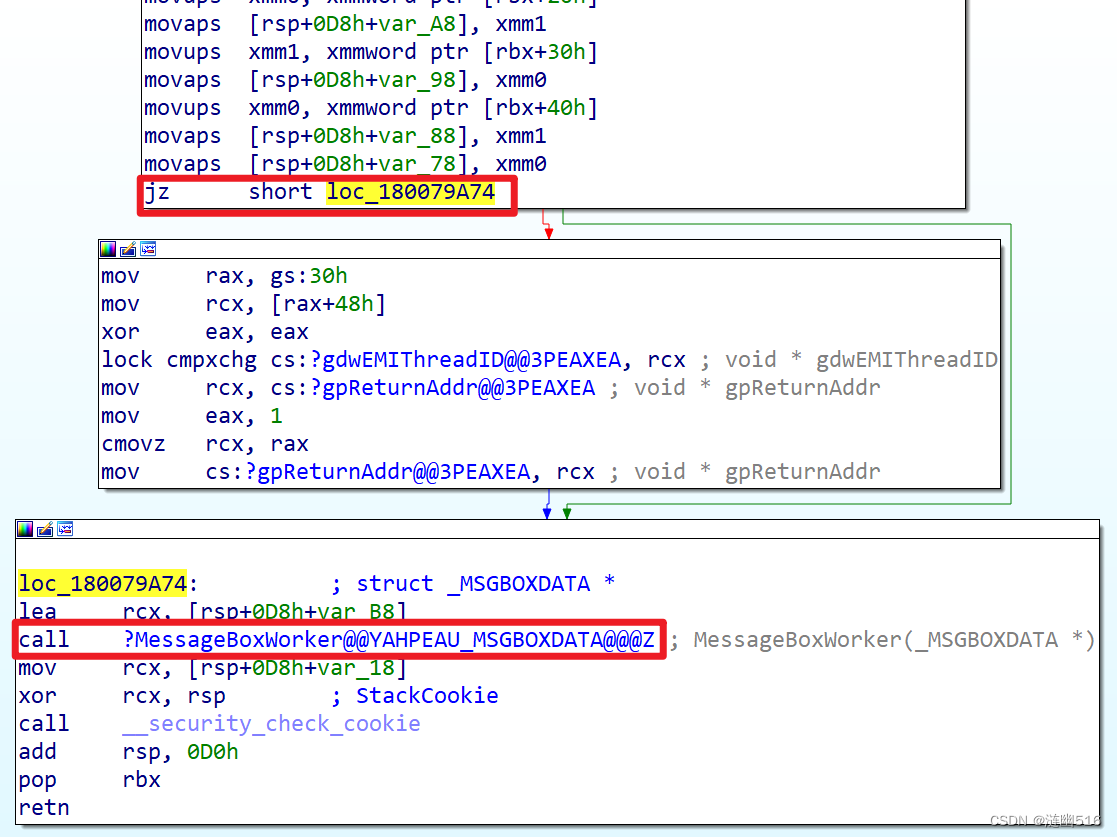
由此可以看出,我们可以通过 jz short 跳转转到调用分支,然后依赖参数传递的特征,比如这里的 lea rcx 指令,对于这种传递结构体指针的函数,基本上这里的传参指令不会变化。
定位 CALL (0xE8) 的顺序查找伪代码如下:
for (nIndex_A = 0; nIndex_A < rSearchLen; nIndex_A++)
{
// Win 10, 11
if (insSeqList[nIndex_A] == 0x74 && insSeqList[nIndex_A + 2] == 0x65)// jz
{
dwTargetPos = SUSPICIOUS_INSTRUCTION_CONTEXT; // 设置错误码
// lea rcx, [rsp+0D8h+var_B8] ; struct _MSGBOXDATA *
// 首先 i + 2 表示 jz short 下一条指令,然后根据 ((BYTE*)Proc)[i + 1] 表示的偏移量计算跳转地址
// 随后越过寄存器存储结构体struct _MSGBOXDATA *的指令,指令长度为 5 字节,找到 E8 Call指令
int nBaseShift = (nIndex_A + 2) + insSeqList[nIndex_A + 1];// E8 @ptr; Call @ptr
for (int k = 0; k < 8; k++)
{
if (insSeqList[++nBaseShift] == 0xE8)
{
dwTargetPos = nBaseShift;
break;
}
}
}
// 如果找到或者发生错误,就跳出外循环
if (dwTargetPos ||
dwTargetPos == SUSPICIOUS_INSTRUCTION_CONTEXT) break;
}当得到 CALL 指令的位置后,通过 CALL 指令后面 4 字节表示的偏移量(小端模式),用这个偏移量加上 CALL 指令的后一条指令的地址,就可以得到实际跳转地址。
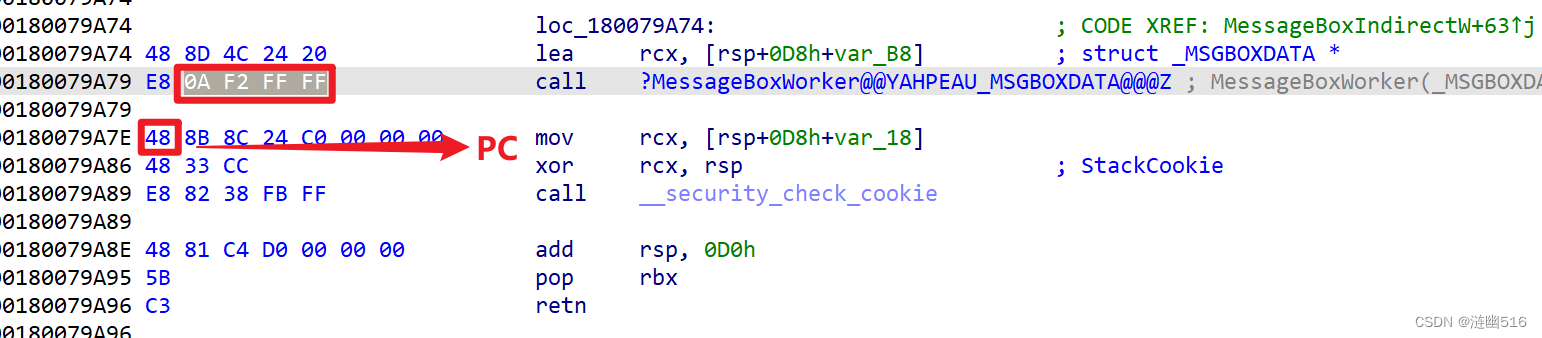
完整的核算方式为:跳转地址 = 0xE8 的地址 + 5 + 跳转偏移量。
3.2 第二种情况( Win 8/8.1 专用)
这种方法在适配 Win 8.1/8 时,需要一些额外的处理,但这种处理是可以接受的。
下面看一下 Win 8 的反汇编片段:
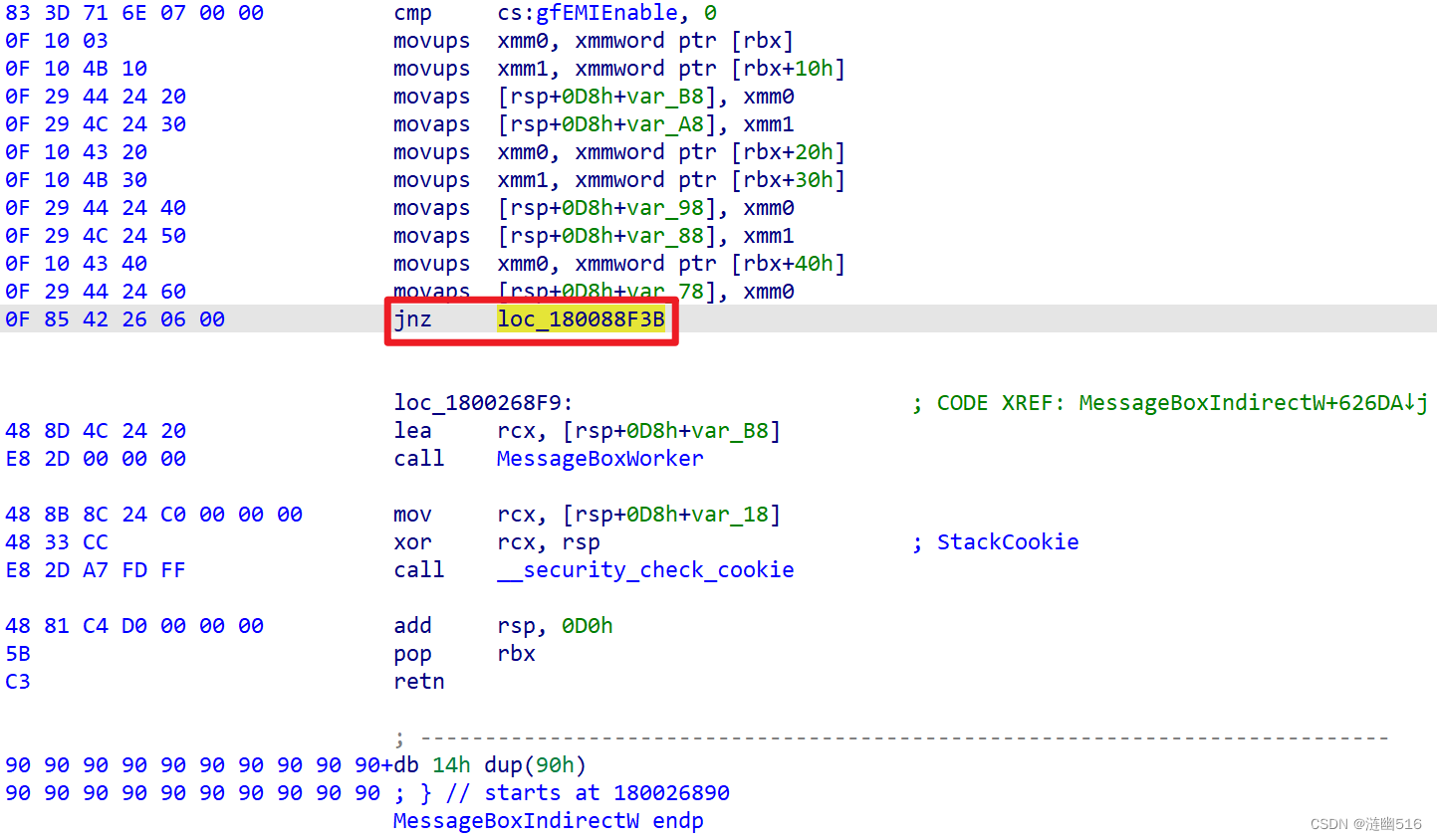
可以发现,不再是短跳了,而是长跳, jnz 属于条件跳转指令,最关键的是这个指令跳转到较远的地方,不过跳转地址是一个分支,他会跳回 loc_1800268F9 处的。
第一种方法,是直接顺序查找距离 jnz 跳转最近的 CALL,分析地址,并检测目标函数的特征。
第二种方法,是找到距离 jnz 最近的堆栈溢出检测(Cookie)处,即 48 8B 8C 24 C0 00 00 00 mov rcx, [rsp+0D8h+var_18]。在他们之间搜索 CALL 指令。
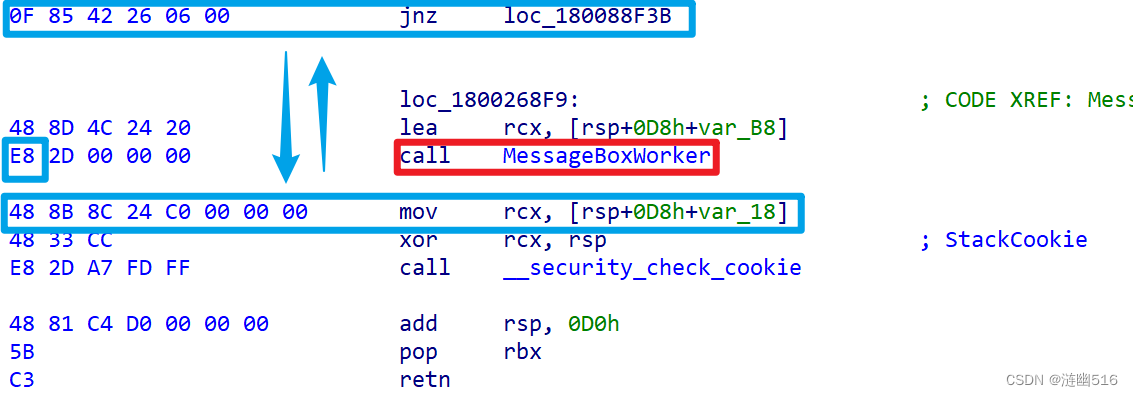
为什么要这样做呢,有人会问,为什么不去定位 lea 指令,因为它的指令长度有不同版本,这会导致定位不准,需要准备多个判断条件,消耗时间,且容易出错,并且观察多个版本就可以知道 48 8B 在短片段内重复出现的频率很低,这提供了很大的容错性。
搜索逻辑如下:
for (nIndex_A = 0; nIndex_A < rSearchLen; nIndex_A++)
{
// Win 8/8.1, 没有 jz 跳转 只有 jnz 跳转,属于大跳且跳到目标函数内部,不适合于定位
// 采用Call指令的上一条寄存器指令来判断,经检索,在一定范围内该指令不会出现重复
if (insSeqList[nIndex_A] == 0x0F && insSeqList[nIndex_A + 1] == 0x85)
{
for (nIndex_B = nIndex_A; nIndex_B < rSearchLen; nIndex_B++)
{
if (insSeqList[nIndex_B] == 0xC3)// retn
{
nIndex_B = static_cast<DWORD>(rSearchLen);
break;
}
if (insSeqList[nIndex_B] == 0x48 &&
insSeqList[nIndex_B + 1] == 0x8B)
{
break;
}
}
// 防止越界
if (nIndex_B >= rSearchLen)
break;
for (nIndex_A; nIndex_A < nIndex_B; nIndex_A++)
{
dwTargetPos = SUSPICIOUS_INSTRUCTION_CONTEXT; // 设置错误码
if (insSeqList[nIndex_A] == 0xE8)
{
dwTargetPos = nIndex_A; // 找到 E8,跳出循环
break;
}
}
// 如果找到或者发生错误,就跳出外循环
if (dwTargetPos ||
dwTargetPos == SUSPICIOUS_INSTRUCTION_CONTEXT) break;
}
}在 Win 7 和 XP,定位方法和 Win 10 相同,走的短跳路线。
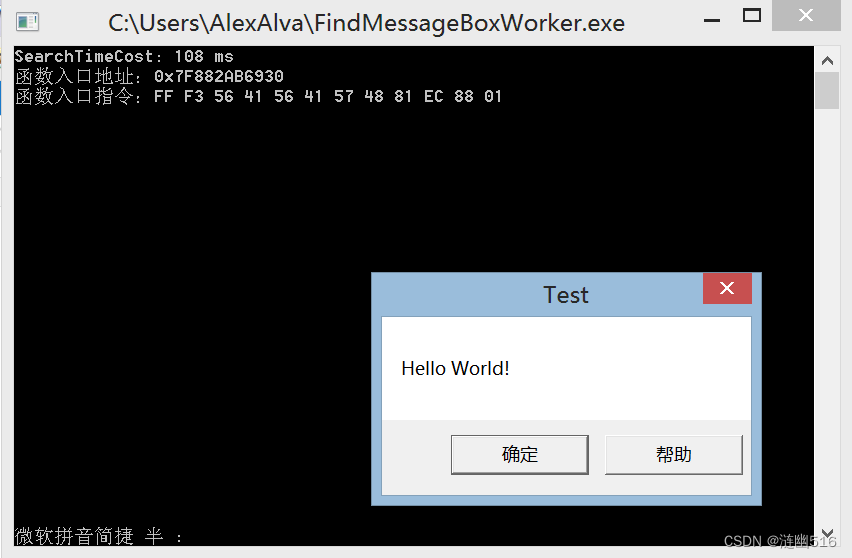
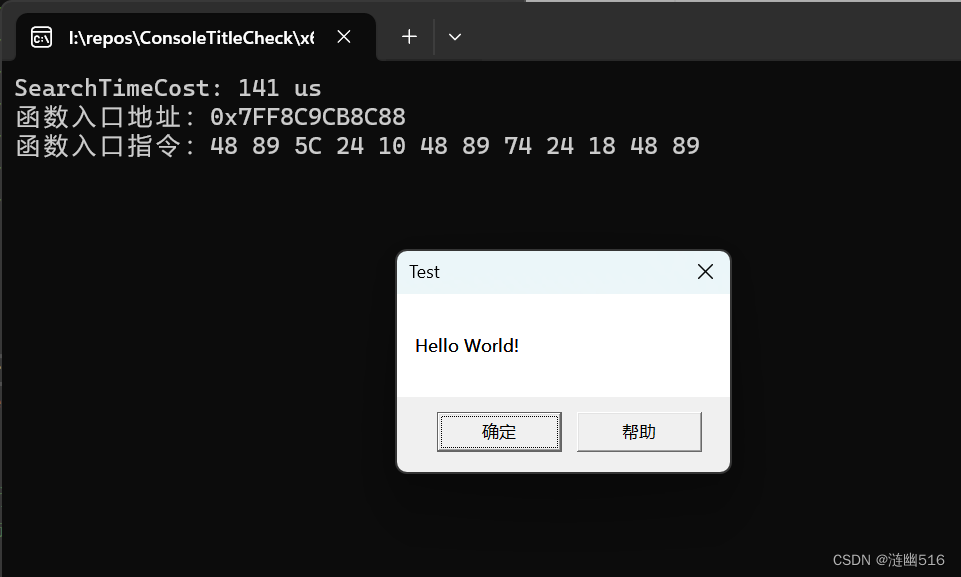
测试运行效果如图:
(1)Win 8(修正一下图片中的耗时,单位是 微秒 microseconds):
(2)Win 11:
3.3 完整代码
完整的测试代码我也提供一下。
需要设置附加程序清单:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0" xmlns:asmv3="urn:schemas-microsoft-com:asm.v3">
<asmv3:application>
<asmv3:windowsSettings>
<dpiAware xmlns="http://schemas.microsoft.com/SMI/2005/WindowsSettings">true</dpiAware>
<dpiAwareness xmlns="http://schemas.microsoft.com/SMI/2016/WindowsSettings">PerMonitorV2</dpiAwareness>
</asmv3:windowsSettings>
</asmv3:application>
</assembly>测试代码:
#include <iostream>
#include <Windows.h>
#include <TlHelp32.h>
enum CLOSE_BUTTON_FLAGS {
button_gray, // 关闭按钮灰显
button_enable_ID1, // 关闭按钮不灰显
button_enable_ID2 // 关闭按钮不灰显 MB_OK
};
typedef struct _MSGBOXDATA {
MSGBOXPARAMSW mbparams;
HWND hwndOwner; // *(HWND *)(a1 + 8)
WORD wLanguageId; // MessageBox显示语言
BYTE unknown1[2]; // 姑且不明,大概率只是对齐
PDWORD pdwButtonID; // 按钮ID数组的指针,按钮ID同MessageBox返回值。(ID_HELP是9)
LPCWSTR* pszButtonTextTable; // 按钮字符串数组的指针。
DWORD dwButtonSum; // 按钮的数量
DWORD dwButtonDef; // 默认按钮
CLOSE_BUTTON_FLAGS enCloseButtonFlag; // 关闭按钮状态,其实我觉得应该是bool类型才对
DWORD dwMilliseconds; // 窗口等待时间
BYTE unknown2[28]; // 仍然不明
}MSGBOXDATA, * LPMSGBOXDATA;
typedef int(_fastcall* MSGWORKERPROC)(LPMSGBOXDATA);
VOID CALLBACK MsgBoxCallback(LPHELPINFO lpHelpInfo);// 消息盒子帮助回调函数
typedef LONG MYSTATUS;
typedef MYSTATUS* LPMYSTATUS;
size_t WINAPI InstructionConvertToHexString(
_In_ char* pszData,
_In_ size_t inputSize,
_Inout_ char* Buffer,
_Inout_ size_t bufferSize
);
BOOL WINAPI ProcessModuleHandlerWorker(
HMODULE hModule
);
FARPROC WINAPI GetInternalProcAddress(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName,
_In_ DWORD dwSearchLen,
_Inout_ LPMYSTATUS dwResponse
);
/*
* 一些宏定义,为了便于标识错误
*/
constexpr LONG SUSPICIOUS_INSTRUCTION_CONTEXT = 0xFFFFFFFF; // 注意需要这里为 -1
constexpr auto MODULE_NOT_LOADED = 0x8C << 0x18 | 0x1;
constexpr auto ENTRY_ADDRESS_ERROR = 0x8C << 0x18 | 0x2;
constexpr auto HEAP_ALLOC_FAILED = 0x8C << 0x18 | 0x3;
constexpr auto BINARY_SEARCH_ERROR = 0x8C << 0x18 | 0x4;
constexpr auto BUFFER_OVERFLOW_ERROR = 0x8C << 0x18 | 0x5;
int main()
{
MYSTATUS nStatus = 0;
HMODULE hUser32 = 0;
FARPROC pFunMessageBoxWorker = NULL;
CHAR EntryIntV[13] = { 0 };
CHAR hexEntryIntV[37] = { 0 };
MSGBOXDATA mbdata = { 0 };
MSGBOXPARAMSW mbparams = { 0 };
MSGWORKERPROC MessageBoxWorker = NULL;
// 加载目标函数所在模块
hUser32 = LoadLibraryW(L"user32.dll");
if (!hUser32)
{
fprintf(stderr, "加载 user32.dll 动态链接库失败。\n");
return -1;
}
// 检索 MessageBoxWorker 函数地址
pFunMessageBoxWorker =
GetInternalProcAddress(hUser32, "MessageBoxIndirectW", 1000, &nStatus);
if (!pFunMessageBoxWorker)
{
fprintf(stderr, "检索 MessageBoxWorker 函数地址失败。Error: %01X\n", nStatus);
return -1;
}
// 拷贝入口附近指令
if (memcpy_s(EntryIntV, 12,
pFunMessageBoxWorker, 12) != 0)
{
fprintf(stderr, "写入缓冲区失败。\n");
return -2;
}
if (!InstructionConvertToHexString(EntryIntV, 12, hexEntryIntV, 37))
{
fprintf(stderr, "写入缓冲区失败。\n");
return -3;
}
// 输出解析结果
printf("函数入口地址:0x%I64X\n", reinterpret_cast<uint64_t>(pFunMessageBoxWorker));
printf("函数入口指令:%s\n", hexEntryIntV);
// 转换为函数指针
MessageBoxWorker = (MSGWORKERPROC)(pFunMessageBoxWorker);
// 准备调用参数
memset(&mbparams, 0, sizeof(MSGBOXPARAMSW));
mbparams.cbSize = sizeof(MSGBOXPARAMSW);
mbparams.dwStyle = MB_OK | MB_HELP;
mbparams.lpszText = TEXT("Hello World!");
mbparams.lpszCaption = TEXT("Test");
// 设置自定义图标
mbparams.hInstance = GetModuleHandleW(0);
// mbparams.lpszIcon = TEXT("USERICON");
// 设置帮助回文ID和回调函数
mbparams.dwContextHelpId = 0x1;
mbparams.lpfnMsgBoxCallback = MsgBoxCallback;
// 设置显示语言
mbparams.dwLanguageId = MAKELANGID(LANG_ENGLISH, SUBLANG_ENGLISH_US);
memset(&mbdata, 0, sizeof(MSGBOXDATA));
memcpy(&mbdata, &mbparams, sizeof(MSGBOXPARAMSW));
int msgResponse = MessageBoxWorker(&mbdata); // 调用目标函数
fprintf(stderr, "返回值:%d.\n", msgResponse);
system("pause");
return 0;
}
// 帮助回调函数
void CALLBACK MsgBoxCallback(LPHELPINFO lpHelpInfo) {
switch (lpHelpInfo->dwContextId) {
case 0x1:
MessageBox(NULL, TEXT("这是0x1的帮助"), TEXT("帮助"), MB_OK);
break;
default:
MessageBox(NULL, TEXT("这是默认帮助"), TEXT("帮助"), MB_OK);
break;
}
}
size_t WINAPI InstructionConvertToHexString(
_In_ char* pszData,
_In_ size_t inputSize,
_Inout_ char* Buffer,
_Inout_ size_t bufferSize
){
size_t needBufferSize = inputSize * 3;
// 检查缓冲区是否足够大
if (bufferSize < needBufferSize) {
// fprintf(stderr, "缓冲区大小不足以存储结果。\n");
bufferSize = inputSize * 3;
return 0;
}
// 遍历输入数组
for (size_t i = 0; i < inputSize; ++i) {
// 将每个字节的数字转换为十六进制,并存储到输出缓冲区
snprintf(Buffer + i * 3, 4, "%02X ", (unsigned char)pszData[i]);
}
// 在字符串末尾添加null终止符
Buffer[needBufferSize - 1] = '\0';
return needBufferSize;
}
BOOL WINAPI ProcessModuleHandlerWorker(HMODULE hModule)
{
HMODULE BaseAddress = NULL;
MODULEENTRY32W me32 = { 0 };
me32.dwSize = sizeof(MODULEENTRY32W);
// 获取指定进程全部模块的快照
HANDLE hModuleSnap = CreateToolhelp32Snapshot(TH32CS_SNAPMODULE, GetCurrentProcessId());
if (INVALID_HANDLE_VALUE == hModuleSnap)
{
// 创建快照失败
return FALSE;
}
// 获取快照中第一条信息
BOOL bResponse = Module32FirstW(hModuleSnap, &me32);
while (bResponse)
{
// 模块加载基址
BaseAddress = reinterpret_cast<HMODULE>(me32.modBaseAddr);
if (hModule == BaseAddress) { // 如果地址匹配,则结束
// 关闭句柄
CloseHandle(hModuleSnap);
return TRUE;
}
// 获取快照中下一条信息
bResponse = Module32NextW(hModuleSnap, &me32);
}
// 关闭句柄
CloseHandle(hModuleSnap);
return FALSE;
}
FARPROC WINAPI GetInternalProcAddress(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName,
_In_ DWORD dwSearchLen,
_Inout_ LPMYSTATUS dwResponse
)
{
LARGE_INTEGER StartingTime = { 0 }, EndingTime = { 0 }, ElapsedMicroseconds = { 0 };
LARGE_INTEGER Frequency;
QueryPerformanceFrequency(&Frequency);
QueryPerformanceCounter(&StartingTime);
// 判断模块句柄是否有效
if (!ProcessModuleHandlerWorker(hModule)
|| dwSearchLen > 0x7FFF)
{
// 左移 24 位,构造高位 Magic 值 0x8C,低位表示错误码/偏移量
// 低位一共 16 位,2 字节,可以容纳最大偏移量 32767(`10)
*dwResponse = MODULE_NOT_LOADED;
return NULL;
}
FARPROC lpExternalFunc = NULL;
PBYTE insSeqList = NULL;
size_t rSearchLen = 0;
int dwCalljump = 0;
DWORD dwTargetPos = 0;
DWORD nIndex_A = 0,
nIndex_B = 0;
int64_t ullTargetProc = 0;
lpExternalFunc = // 读取导出函数的地址
GetProcAddress(hModule, lpProcName);
if (lpExternalFunc == NULL)
{
*dwResponse = ENTRY_ADDRESS_ERROR;
return NULL;
}
/*
* 申请用于分析指令的内存
* 大小取决于函数窗口的大小
* */
if (dwSearchLen <= 0)
rSearchLen = 1000;
else
rSearchLen = static_cast<size_t>(dwSearchLen);
insSeqList = (BYTE*)malloc(rSearchLen + 1);
if (insSeqList == NULL)
{
*dwResponse = HEAP_ALLOC_FAILED;
return NULL;
}
memset(insSeqList, 0, rSearchLen);
// 从导出函数的首地址开始拷贝内存
if ( memcpy_s(insSeqList, rSearchLen,
lpExternalFunc, rSearchLen) != 0 )
{
*dwResponse = HEAP_ALLOC_FAILED;
return NULL;
}
// 开始循环搜索
for (nIndex_A = 0; nIndex_A < rSearchLen; nIndex_A++)
{
// Win 10, 11
if (insSeqList[nIndex_A] == 0x74 && insSeqList[nIndex_A + 2] == 0x65)// jz
{
dwTargetPos = SUSPICIOUS_INSTRUCTION_CONTEXT; // 设置错误码
// lea rcx, [rsp+0D8h+var_B8] ; struct _MSGBOXDATA *
// 首先 i + 2 表示 jz short 下一条指令,然后根据 ((BYTE*)Proc)[i + 1] 表示的偏移量计算跳转地址
// 随后越过寄存器存储结构体struct _MSGBOXDATA *的指令,指令长度为 5 字节,找到 E8 Call指令
int nBaseShift = (nIndex_A + 2) + insSeqList[nIndex_A + 1];// E8 @ptr; Call @ptr
for (int k = 0; k < 8; k++)
{
if (insSeqList[++nBaseShift] == 0xE8)
{
dwTargetPos = nBaseShift;
break;
}
}
}
// 如果找到或者发生错误,就跳出外循环
if (dwTargetPos ||
dwTargetPos == SUSPICIOUS_INSTRUCTION_CONTEXT) break;
// Win 8, 没有 jz跳转 只有jnz跳转,属于大跳且跳到目标函数内部,不适合于定位
// 采用Call指令的上一条寄存器指令来判断,经检索,在一定范围内该指令不会出现重复
if (insSeqList[nIndex_A] == 0x0F && insSeqList[nIndex_A + 1] == 0x85)
{
for (nIndex_B = nIndex_A; nIndex_B < rSearchLen; nIndex_B++)
{
if (insSeqList[nIndex_B] == 0xC3)// retn
{
nIndex_B = static_cast<DWORD>(rSearchLen);
break;
}
if (insSeqList[nIndex_B] == 0x48 &&
insSeqList[nIndex_B + 1] == 0x8B)
{
break;
}
}
// 防止越界
if (nIndex_B >= rSearchLen)
break;
for (nIndex_A; nIndex_A < nIndex_B; nIndex_A++)
{
dwTargetPos = SUSPICIOUS_INSTRUCTION_CONTEXT; // 设置错误码
if (insSeqList[nIndex_A] == 0xE8)
{
dwTargetPos = nIndex_A; // 找到 E8,跳出循环
break;
}
}
// 如果找到或者发生错误,就跳出外循环
if (dwTargetPos ||
dwTargetPos == SUSPICIOUS_INSTRUCTION_CONTEXT) break;
}
}
free(insSeqList);
insSeqList = NULL;
if (!dwTargetPos || dwTargetPos == SUSPICIOUS_INSTRUCTION_CONTEXT)
{
*dwResponse = BINARY_SEARCH_ERROR;
return NULL;
}
// 找到 E8 后,解析跳转地址
ullTargetProc =
reinterpret_cast<int64_t>(lpExternalFunc) + dwTargetPos + 1;
// 拷贝 Call 的偏移量(4 字节)
memcpy(&dwCalljump, reinterpret_cast<FARPROC>(ullTargetProc), 4);
// 计算真实地址
ullTargetProc =
reinterpret_cast<int64_t>(lpExternalFunc) + dwTargetPos + 5 + dwCalljump;
// 拷贝 函数入口点上方的字节(4 字节)
if (memcpy_s(&dwCalljump, 4,
reinterpret_cast<FARPROC>(ullTargetProc - 4), 4) != 0)
{
*dwResponse = BUFFER_OVERFLOW_ERROR;
return NULL;
}
// 检查入口点上方 HotPatch 特征
if (!!(dwCalljump ^ 0x90909090) &&
!!(dwCalljump ^ 0xcccccccc))
{
*dwResponse = BINARY_SEARCH_ERROR;
return NULL;
}
*dwResponse = dwTargetPos;
QueryPerformanceCounter(&EndingTime);
ElapsedMicroseconds.QuadPart = EndingTime.QuadPart - StartingTime.QuadPart;
//
// We now have the elapsed number of ticks, along with the
// number of ticks-per-second. We use these values
// to convert to the number of elapsed microseconds.
// To guard against loss-of-precision, we convert
// to microseconds *before* dividing by ticks-per-second.
//
ElapsedMicroseconds.QuadPart *= 1000000;
ElapsedMicroseconds.QuadPart /= Frequency.QuadPart;
printf("SearchTimeCost: %zd us\n", ElapsedMicroseconds.QuadPart);
return reinterpret_cast<FARPROC>(ullTargetProc);
}四、相关练习
使用上文提出的方法,同样可以尝试定位 LoadLibraryExW 函数的内部调用函数 BasepLoadLibraryAsDataFileInternal,该函数用于将模块加载为数据,而非可执行区;另一个定位就是定位 LdrpLoadLibrary 函数。
BasepLoadLibraryAsDataFileInternal 的声明经过逆向分析应该是:
NTSTATUS __fastcall BasepLoadLibraryAsDataFileInternal(
PUNICODE_STRING FileNameString,
PCWSTR SourceString,
PCWSTR SearchPaths,
DWORD dwFlags,
PVOID * DllBaseAddress
)
LoadLibraryExW 在 Win8~Win11 上反编译(IDA F5 结果的修正)代码如下:
/**
* 由Lianyiyou516 分析。 create: 2023.10.13, changed 2024.01.14
*/
HMODULE WINAPI LoadLibraryExW(LPCWSTR lpLibFileName, HANDLE hFile, DWORD dwFlags)
{
DWORD dwLoaderInitFlags; // bx
//NTSTATUS inited; // eax
USHORT Length; // cx
//NTSTATUS dwLowerStatus; // eax
//NTSTATUS dwStatus; // edi
NTSTATUS dwLastNTError; // rcx
ULONG dwLowBufferFlags = 0; // eax
bool BufferComparedFlag; // zf
PWSTR SourceString; // [rsp+30h] [rbp-20h] BYREF
PWSTR SearchPaths; // [rsp+38h] [rbp-18h] BYREF
UNICODE_STRING DestinationString; // [rsp+40h] [rbp-10h] BYREF
ULONG dwInternalLoadFlags = 0; // [rsp+70h] [rbp+20h] BYREF
PVOID BaseAddress = NULL; // [rsp+88h] [rbp+38h] BYREF
dwLoaderInitFlags = dwFlags;
if (!lpLibFileName || hFile ||
(dwFlags & 0xFFFF0000) != 0 || // 标志位高位取不到,如果传入高位不为0的参数,则视为无效传参
(dwFlags & 0x42) == 0x42) // 不能组合使用 LOAD_LIBRARY_AS_DATAFILE_EXCLUSIVE(0x40) | LOAD_LIBRARY_AS_DATAFILE(0x02)
{
dwLastNTError = STATUS_INVALID_PARAMETER;// 3221225485, 0XC000000DL
goto ErrorEndFunc;
}
// 转为 UNICODE 字符串
dwLastNTError = RtlInitUnicodeStringEx(&DestinationString, lpLibFileName);
if (dwLastNTError < 0)
goto ErrorEndFunc;
Length = DestinationString.Length;
if (!DestinationString.Length)
{
dwLastNTError = STATUS_INVALID_PARAMETER;// 3221225485, 0XC000000DL
goto ErrorEndFunc;
}
// 忽略字符串末尾 N 个空格,修正 Length 大小
do
{
if (DestinationString.Buffer[((uint64_t)Length >> 1) - 1] != 32)
break;
BufferComparedFlag = (Length == 2);
Length -= 2;
DestinationString.Length = Length;
} while (!BufferComparedFlag);
// 要加载 Dll 文件字符串的长度不能为空
if (!Length)
{
dwLastNTError = STATUS_INVALID_PARAMETER;// 3221225485, 0XC000000DL
goto ErrorEndFunc;
}
/* LOAD_LIBRARY_AS_DATAFILE, LOAD_LIBRARY_AS_DATAFILE_EXCLUSIVE, LOAD_LIBRARY_AS_IMAGE_RESOURCE
* 这三个标志位只要有一个被指定时候,就不加载为可执行文件,所以走下面的 else 分支
*/
if ((dwLoaderInitFlags & LOAD_LIBRARY_AS_FILE) == FALSE)
{
if ((dwLoaderInitFlags & DONT_RESOLVE_DLL_REFERENCES) != 0)
{
dwLowBufferFlags = 2;
dwInternalLoadFlags = 2;
}
if ((dwLoaderInitFlags & LOAD_LIBRARY_REQUIRE_SIGNED_TARGET) != 0)
{
dwLowBufferFlags |= 0x800000u;
dwInternalLoadFlags = dwLowBufferFlags;
}
// 未知,似乎与 ASLR 有关
if ((dwLoaderInitFlags & 4) != 0)
{
dwLowBufferFlags |= 4u;
dwInternalLoadFlags = dwLowBufferFlags;
}
if ((dwLoaderInitFlags & 0x8000) != 0) {
dwInternalLoadFlags = dwLowBufferFlags | 0x80000000;
}
// 加载 Dll
dwLastNTError = LdrLoadDll(
(PWSTR)(dwLoaderInitFlags & 0x7F08 | 1),
&dwInternalLoadFlags,
&DestinationString,
&BaseAddress);
}
else { // 作为资源文件加载走该分支
dwLastNTError = LdrGetDllPath(
DestinationString.Buffer,
dwLoaderInitFlags & 0x7F08,
&SourceString,
&SearchPaths
);
if (dwLastNTError < 0)
goto ErrorEndFunc;
dwLastNTError = BasepLoadLibraryAsDataFileInternal(
&DestinationString,
SourceString,
SearchPaths,
dwInternalLoadFlags,
&BaseAddress);
// 二次尝试
if (
(int)(dwLastNTError + 0x80000000) >= 0 &&
dwLastNTError != STATUS_NO_SUCH_FILE && //-1073741809
(dwLoaderInitFlags & LOAD_LIBRARY_AS_IMAGE_RESOURCE) != 0 && // 0x20
(dwLoaderInitFlags &
(LOAD_LIBRARY_AS_DATAFILE_EXCLUSIVE|LOAD_LIBRARY_AS_DATAFILE)
) != 0 // 0x40, 0x02
)
{
dwLastNTError = BasepLoadLibraryAsDataFileInternal(
&DestinationString,
SourceString,
SearchPaths,
dwInternalLoadFlags,
&BaseAddress);
}
RtlReleasePath(SourceString);
}
if (dwLastNTError >= 0)
return (HMODULE)BaseAddress;
ErrorEndFunc:
BaseSetLastNTError(dwLastNTError);
return 0;
}最终效果如下面多张图片所示:
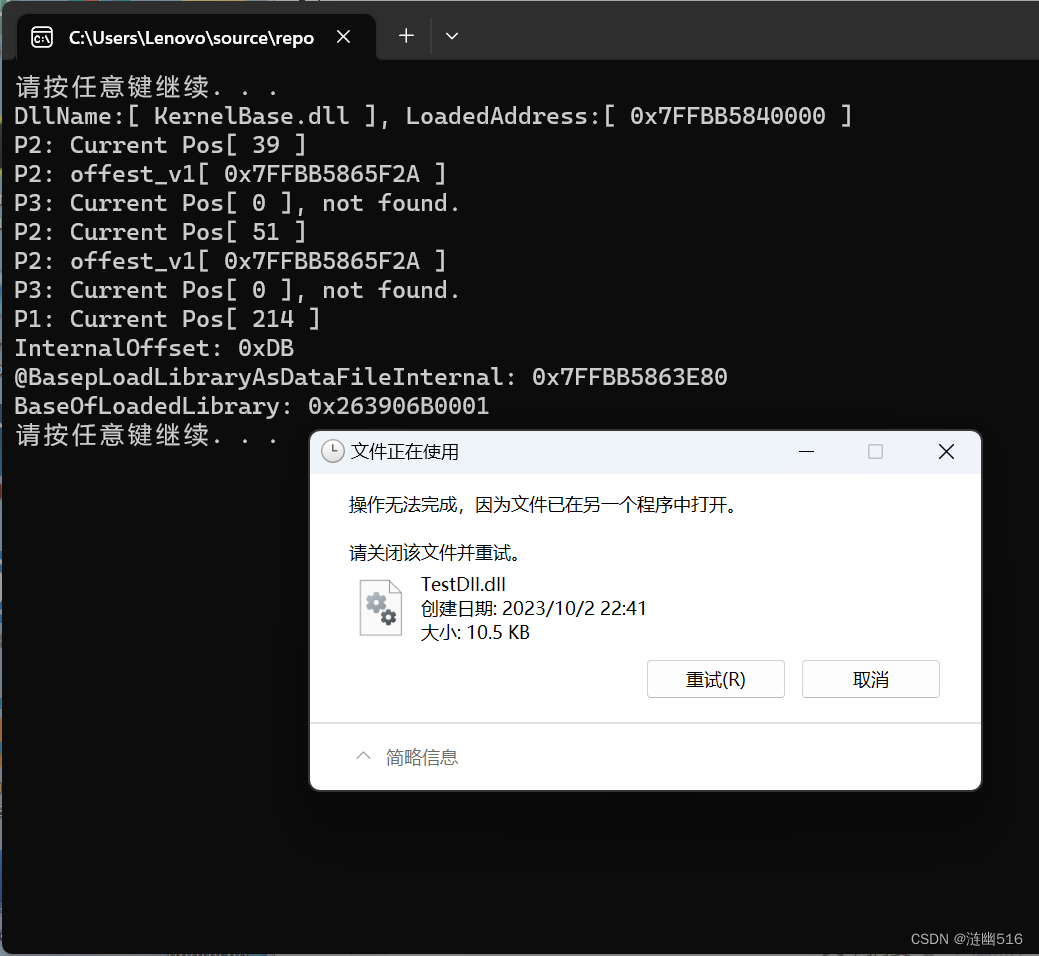
(1)独占方式打开文件(回溯法搜索特征,还有更好的搜索算法):
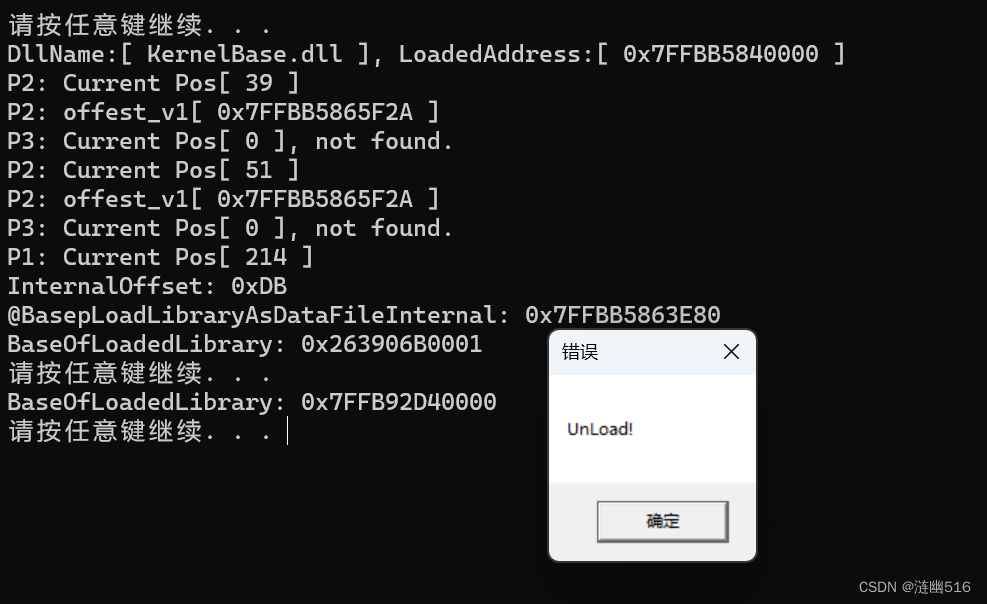
(2)加载DLL 的Main函数效果:
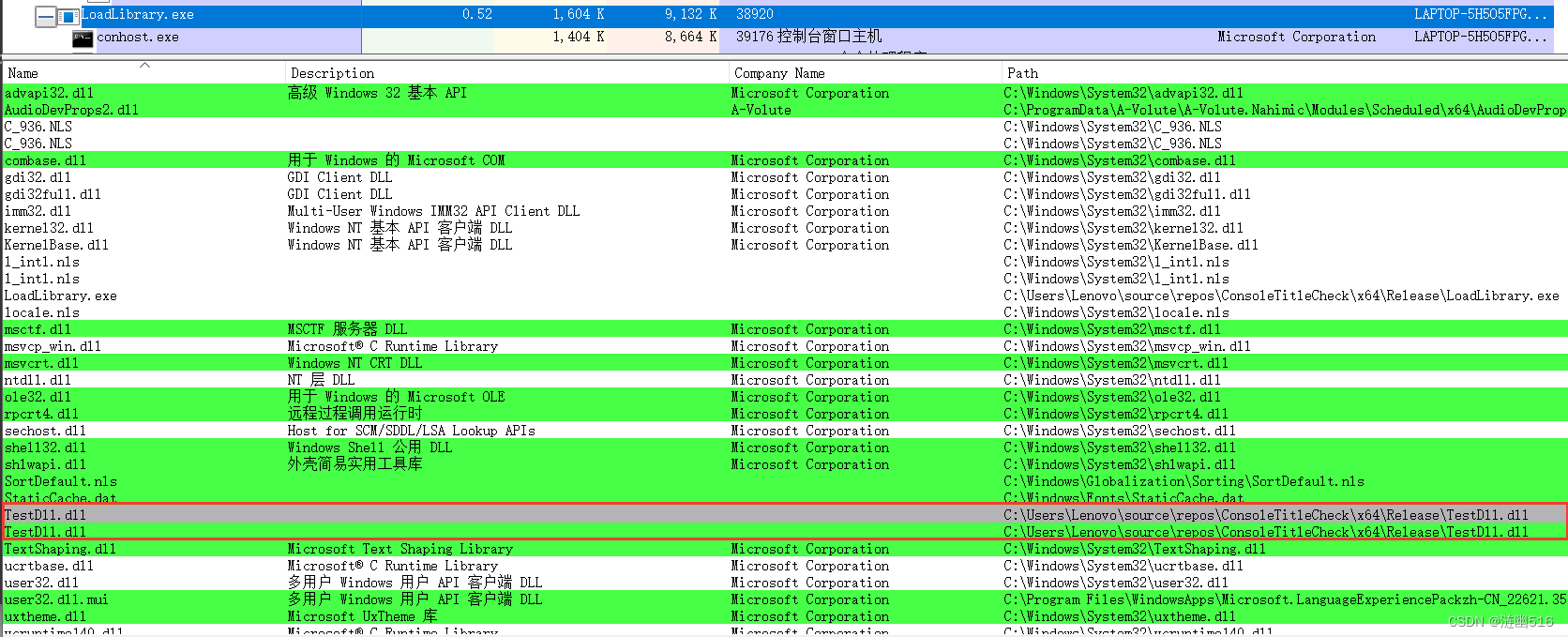
(3)ProcExp 监视注入发生时的信息:
总结&后记
还是那句话,本文提出的方法只是作为一种思路参考,不一定比传统的特征码匹配效果好。更多分析见后期补充。如有问题,也欢迎在评论区讨论。
发布于:2024.01.22,更新于:2024.01.28,2024.04.13.



















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











