






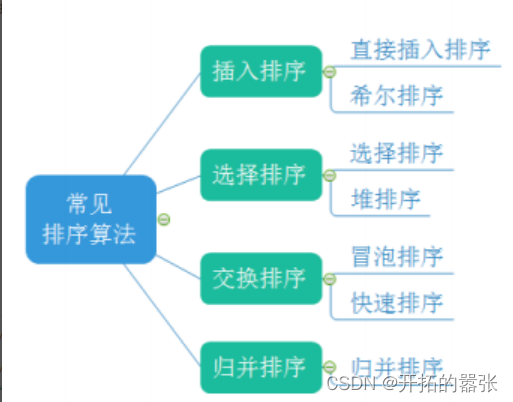
 本文详细介绍了排序算法,包括插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序、归并排序和计数排序。其中,详细讨论了每种排序算法的实现细节、时间复杂度和空间复杂度,帮助读者深入理解各种排序算法的原理和应用场景。
本文详细介绍了排序算法,包括插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序、归并排序和计数排序。其中,详细讨论了每种排序算法的实现细节、时间复杂度和空间复杂度,帮助读者深入理解各种排序算法的原理和应用场景。
目录
排序的概念:
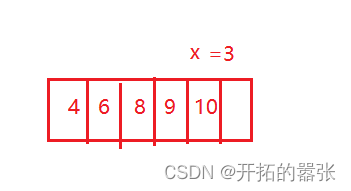
1、插入排序
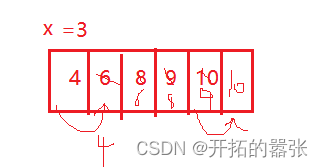
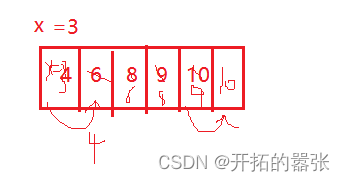
具体代码如下:
void InsertSort(int* a, int n)
{
assert(a);
int i = 0;
for (i = 0; i < n - 1; i++)
{
int end = i;
int x = a[end + 1];
while (end >= 0)
{
if (a[end] > x)
{
a[end + 1] = a[end];
end--;
}
else
break;
}
//end<0 或者 a[end] < x
a[end + 1] = x;
}
}插入排序的时间复杂度为O(N^2),空间复杂度为O(1)。
2、希尔排序
希尔排序就是在插入排序上分组优化,插入排序的gap为1,如果设gap为3,即每隔3个为一组,进行预排序。
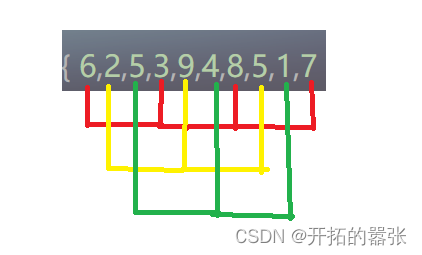
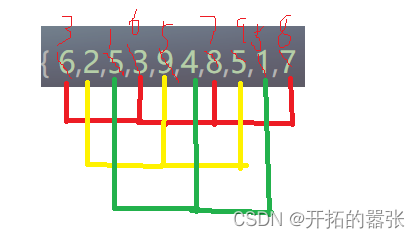
经过预排之后,看以看到,该乱序的数组越趋近于有序,接着在缩小gap,直到gap为1时,那么该数组就会有序。
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int x = a[end + gap];
while (end >= 0)
{
if (a[end] > x)
{
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = x;
}
}
}时间复杂度接近O(N^1.3) 空间复杂度O(1),不稳定。
3、选择排序
选择排序的基本思想:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。

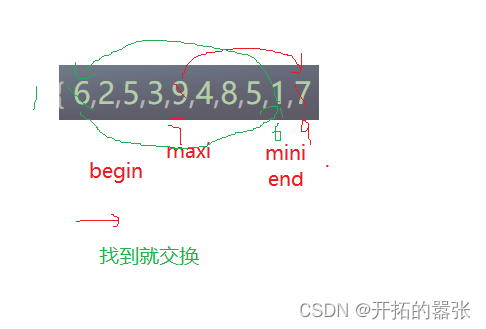
找到之后,最小的跟数组的第一个元素交换,最大的跟数组的最后一个元素交换,然后缩小区间,即begin++,--end,注意:这里找的是最大和最小元素的下标。
注意:这里还有一个BUG,如果最大的的元素出现在区间的开始位置,那么在第一次交换的时候,就会把该下标位置的值换走,所以需要处理一下。
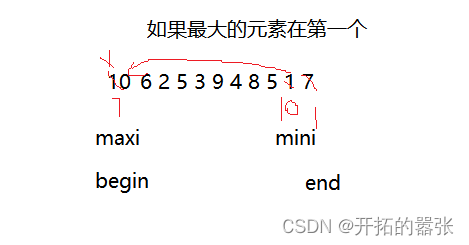
因为最大元素已经跟最小的位置换了,所以只需将最小的下标赋值给最大的下标即可。
void Swap(int* px, int* py)
{
int temp = *px;
*px = *py;
*py = temp;
}
// 选择排序 时间复杂度O(N^2)
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin < end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[begin], &a[mini]);
//begin ==maxi 时,最大被换走了,修正
if (maxi == begin)
{
maxi = mini;
}
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}4、堆排序
堆排序是根据堆的特性,如果要拍的是升序,那么应该建的是大堆,然后将堆顶的位置与最后一个元素交换,然后在向下调整。
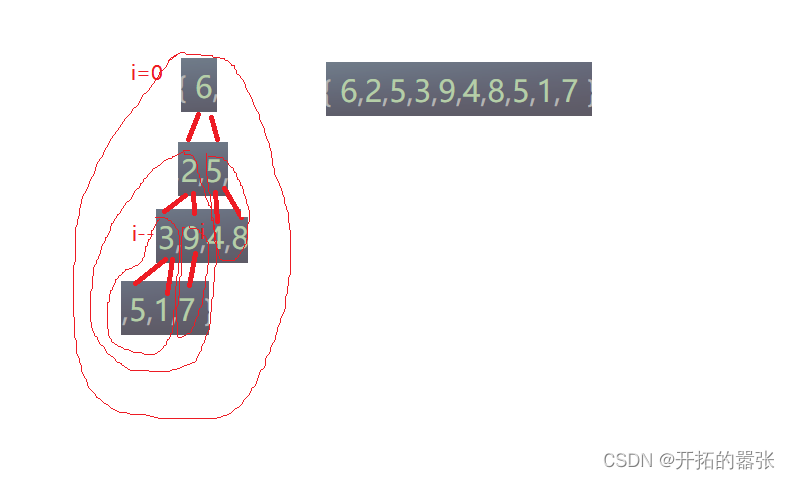
先从最后一个孩子计算父亲,从父亲位置开始建堆。
建堆之后堆顶的位置跟最后一个位置交换,在向下调整的时候,会选出次大的数,依次循环,就可完成堆排序。
void Swap(int* px, int* py)
{
int temp = *px;
*px = *py;
*py = temp;
}
void AdjustDown(int* a, int size, int parent)
{
int child = 2 * parent + 1;
while (child < size)
{
//先找孩子中最小的那一个
if (child + 1 < size && a[child + 1] > a[child])//因为这个地方child+1可能不存在
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[parent], &a[child]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
//堆排序 排升序,调大堆
void HeapSort(int* a, int n)
{
//logN
for (int i = (n - 1 - 1) / 2; i >= 0;--i)
{
AdjustDown(a, n, i);
}
int end = n - 1;
//O(N*lonN)
while (end >= 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}建堆的时间复杂度:O(N),交换后向下调整 O(N*logN)。
5、冒泡排序
冒泡排序就是交换排序的一种,交换排序的基本思想是:
void BubbleSort(int* a, int n)
{
int flag = 0;
for (int j = 0; j < n - 1; j++)
{
for (int i = 0; i < n - 1-j; i++)
{
if (a[i] > a[i + 1])
{
flag = 1; //发生了交换
Swap(&a[i], &a[i + 1]);
}
}
if (flag == 0)
{
break;
}
}
/*int end = n; //直接控制边界
while (end > 0)
{
for (int i = 0; i < end-1; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
}
}
--end;
}*/
}冒泡排序的时间复杂度是O(N^2),空间复杂度O(1)。
6、快速排序
快速排序的单趟有两个版本,第一个是hoare版本。
选最左边的为key,然后让右边先走,找比key小的值,找到之后停下,再让左边走,左边找比key大的值,找到之后跟右边的值交换,交换之后依旧是右边先走,直到左右相遇,相遇之后交换相遇地方与key的值。
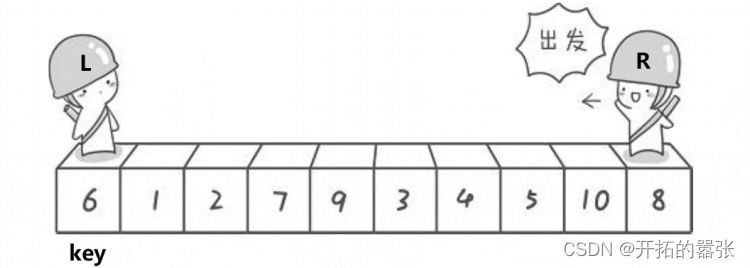
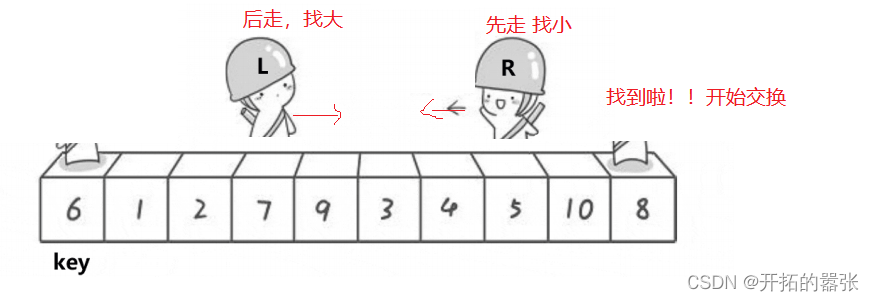
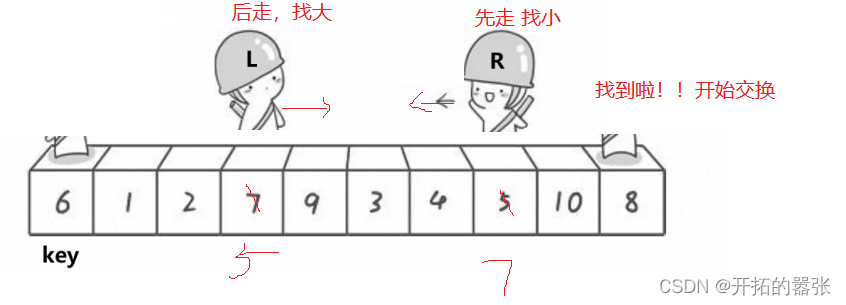
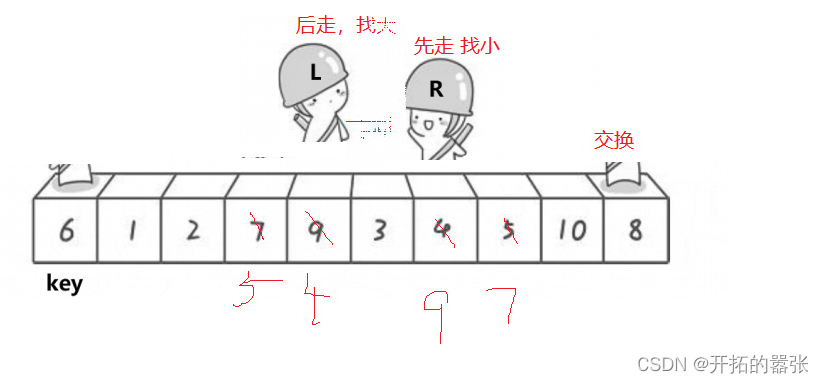
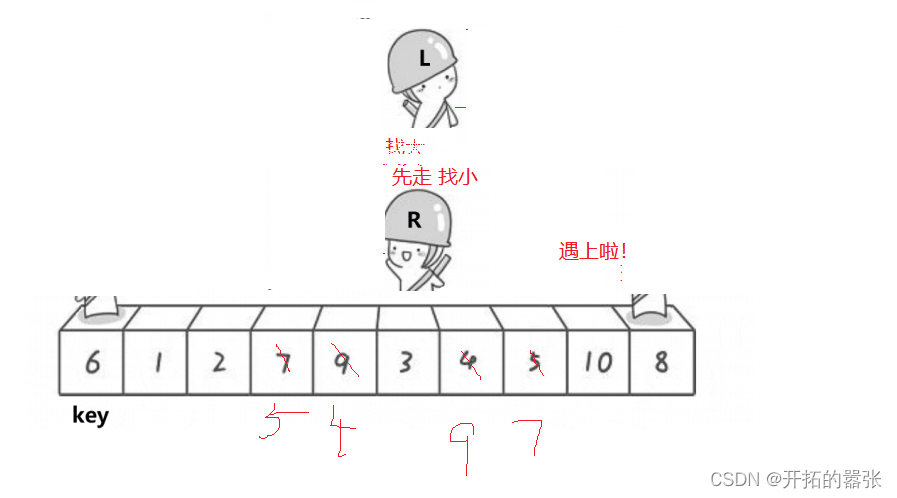
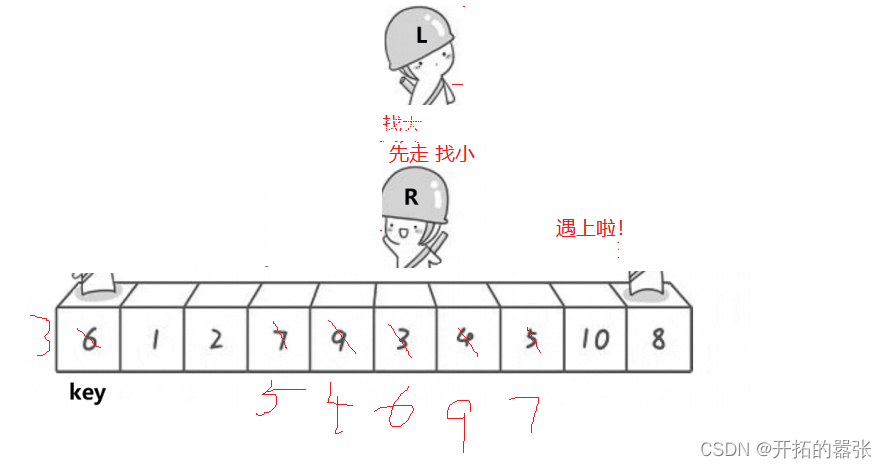
第二种方法是挖坑法:即把选出左边的key值保存起来,当成一个坑位,然后右边走找最小值,找到之后把这个值给坑位,自己形成一个新的坑位,然后左边再走,找比key大的值,找到之后给坑位,自己又形成一个新的坑位,直到相遇。相遇之后再把key的值给坑位。
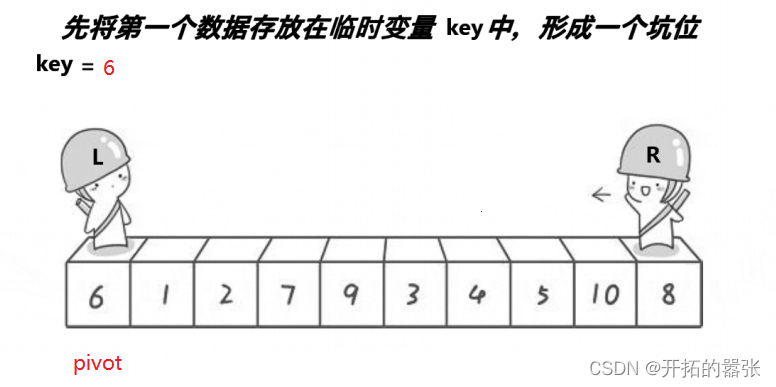
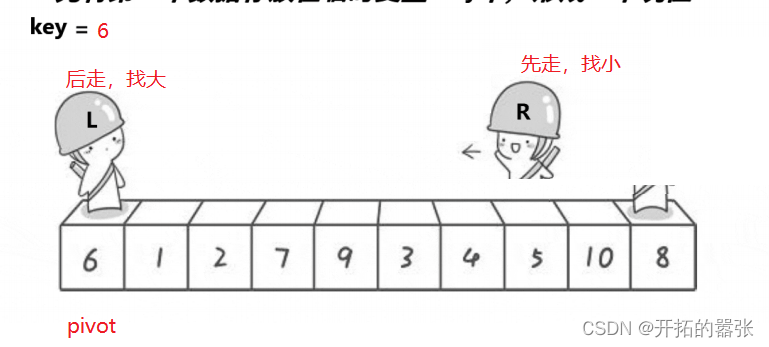
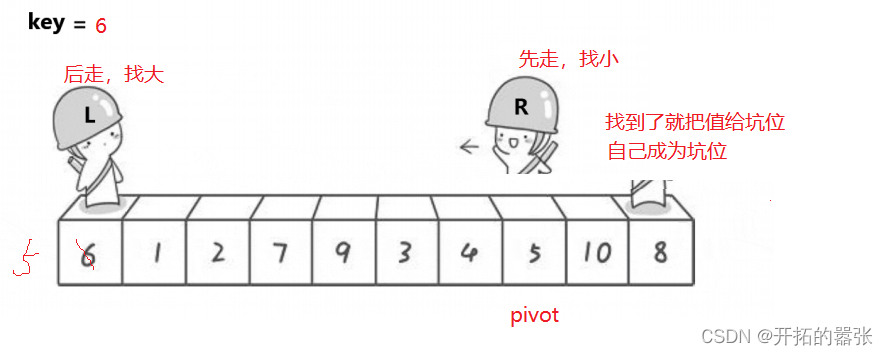
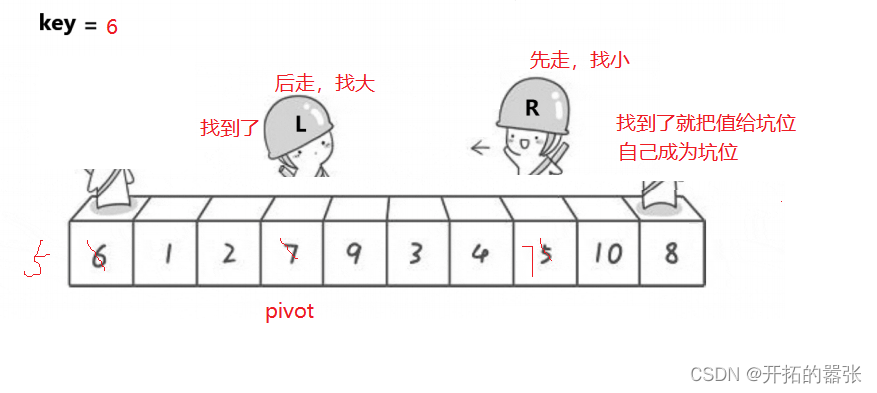
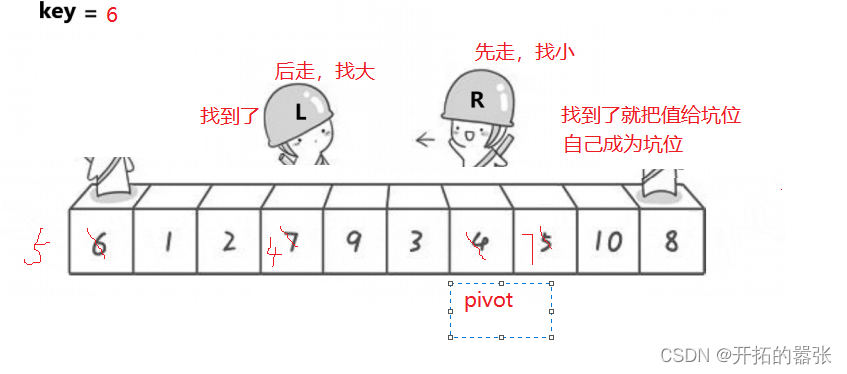
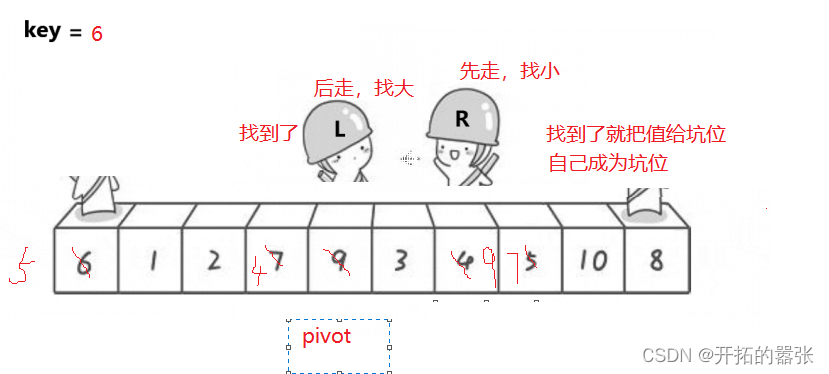
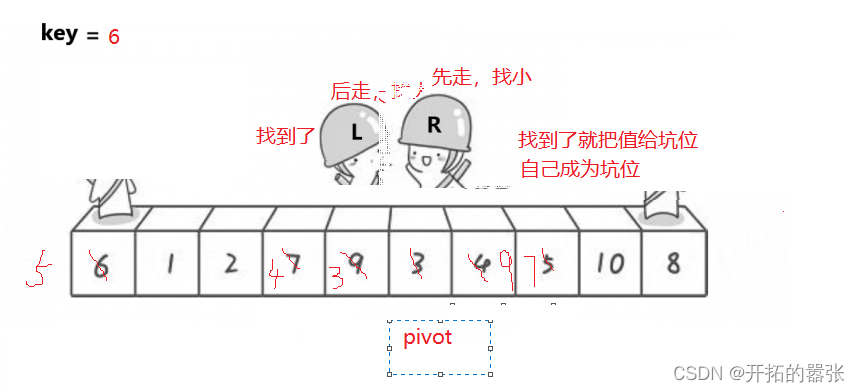
相遇的地方就是坑位,直接用key补上。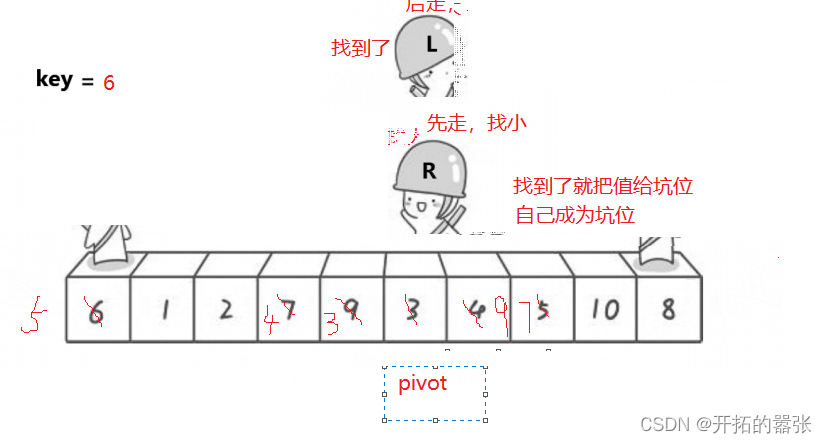
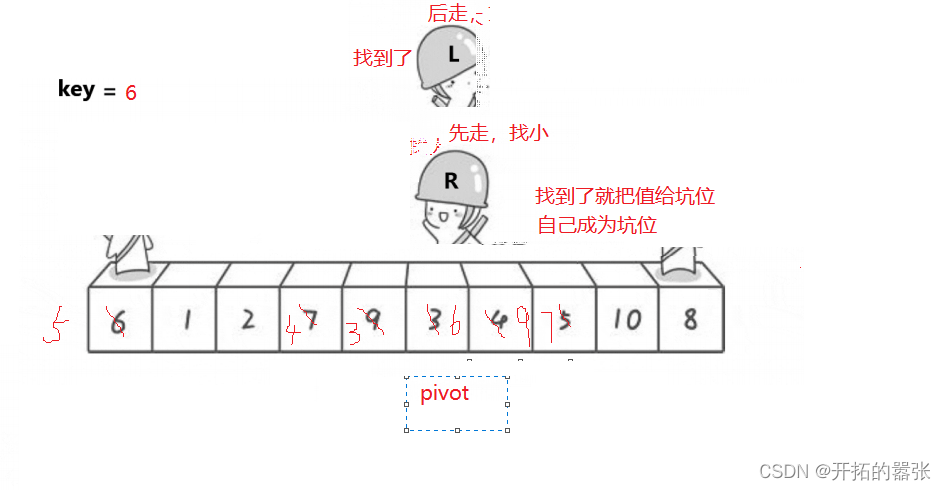
虽然方法一和方法二都是一样的思想,但是两边的数的位置还是有所差别。
这只是快排的一趟,这一趟可以看到,在区间[0 , keyi-1]中,都是比key小的数,在区间 [keyi+1 ,right]都是被key大的数,所以在第一趟排序时,返回keyi的小标,用来分隔数组,采用递归的思想,逐步缩小区间,使区间逐步有序。
int Partion(int* a, int left, int right)
{
int Mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[Mid]);
int keyi = left;
while (left < right)
{
//右边先走,找小
while (left < right && a[right] >=a[keyi]) //有等于是防止进入死循环
{
right--;
}
//左边在走,找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
//走到这左右相遇了
Swap(&a[left], &a[keyi]);
return left;
}
//快排的缺点:有序
//针对有序方法一: 随机选keyi 不靠谱
//方法二:三数取中 左数 中间 和 右数 去值在中间的那一个
int Partion1(int* a, int left, int right) //挖坑法
{
int Mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[Mid]);
int key = a[left];
int pivot = left;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
a[pivot] = a[right];
pivot = right;
while (left < right && a[left] <= key)
{
left++;
}
a[pivot] = a[left];
pivot = left;
}
a[pivot] = key;
return pivot;
}方法三:双指针法
依旧选取最左边为key,prev在key的位置,cur在prev的前一个位置。从cur出发找比key小的值,找到之后,先++prev,然后交换,直到cur走出数组范围后,在交换prev与key的值。
如果选取右边为key值,那么cur和prev都在key值得位置。
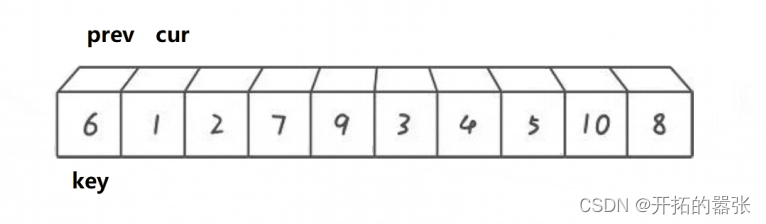
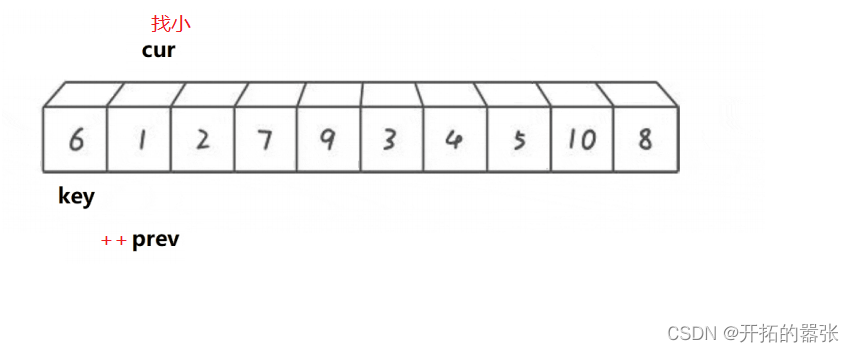
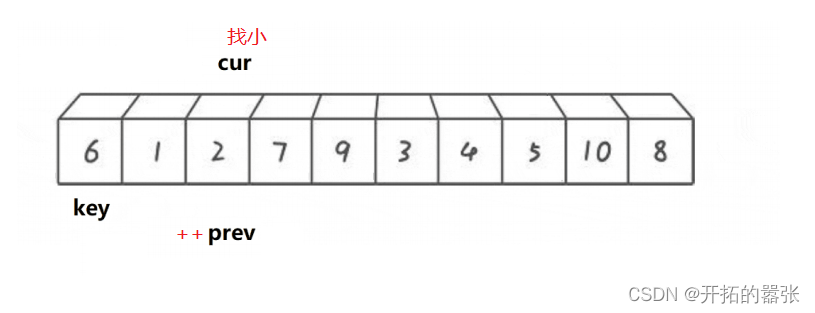
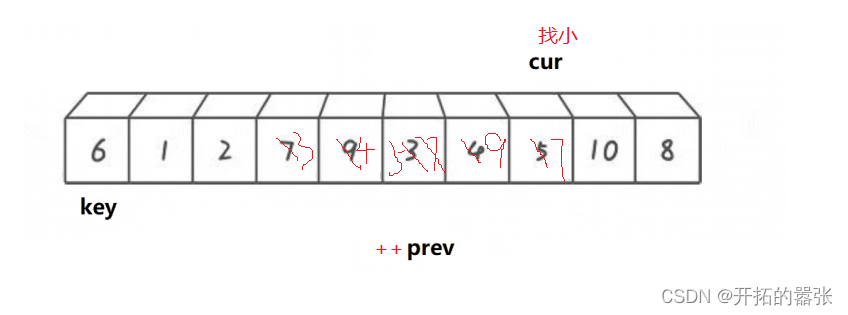
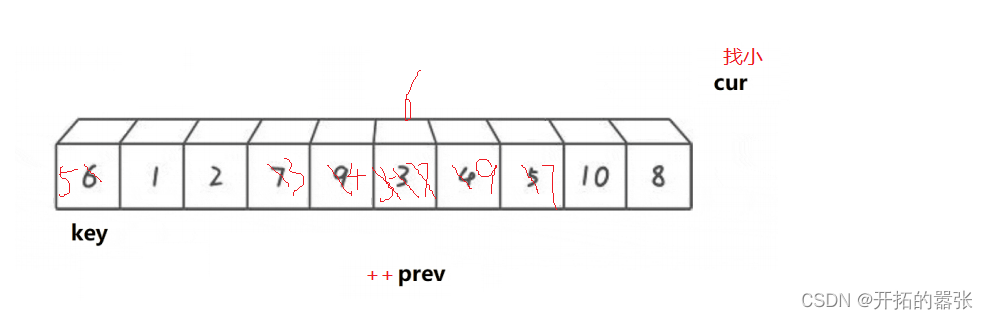
int Partion2(int* a, int left, int right)
{
int Mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[Mid]);
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
//while (cur <= right && a[cur] >= a[keyi]) //找小
//{
// ++cur;
//}
这地方要防止cur越界了 所以要加个判断条件
//if (cur <= right)
//{
// Swap(&a[cur], &a[++prev]);
// cur++; //交换完也要走
//}
if (a[cur] < a[keyi] && ++prev != cur) //不用跟自己交换
{
Swap(&a[cur], &a[prev]);
}
++cur;
//cur找小,把小的往左边翻,prev把大的序列往右边推
}
Swap(&a[prev], &a[keyi]);
return prev;
}快排最坏的情况是当数组有顺序时,快排的时间复杂度是O(N^2)。所以要采用三数取中的思想,即选取最左边、最右边以及中间下标中的中间值,然后给left交换。可以优化时间。
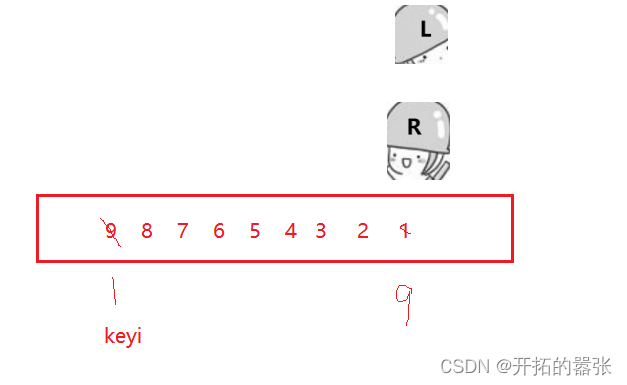
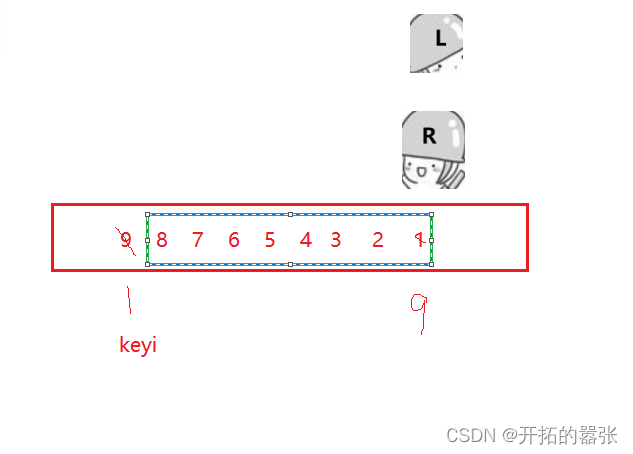
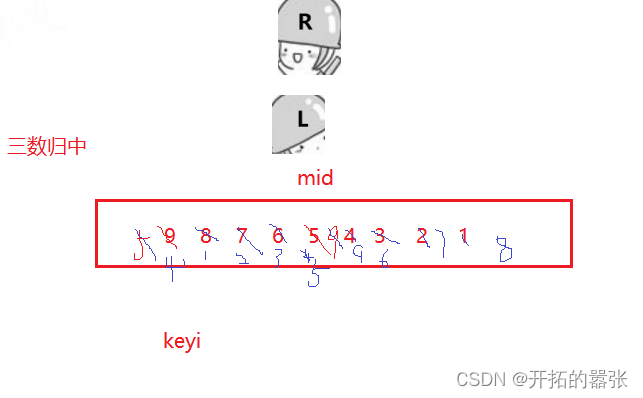
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
/*mid=left+(right-left)/2;*/
if (a[left] < a[right])
{
if (a[right] < a[mid])
{
return right;
}
else if (a[mid] < a[left])
{
return left;
}
else
{
return mid;
}
}
else //a[left] > a[right]
{
if (a[right] > a[mid])
{
return right;
}
else if (a[mid] > a[left])
{
return left;
}
else
{
return mid;
}
}
}void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = Partion1(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi+1,right);
}
快排的优化:当left和right之间的差值很小时,可以使用插入排序,减少递归次数。插入排序相比于堆排、冒泡排序比较的次数少,相对简单。
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
//小区间优化。当分割到小区间时,不在用递归
if (right - left < 10)
{
InsertSort(a+left, right - left+1);
}
else
{
int keyi = Partion2(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
}快排的非递归实现:要想写出快排的非递归实现,就要知道递归的具体原理,这里建议大家自己动手画一画递归展开图,这样更有助于理解递归。
快排的递归类似与下图:
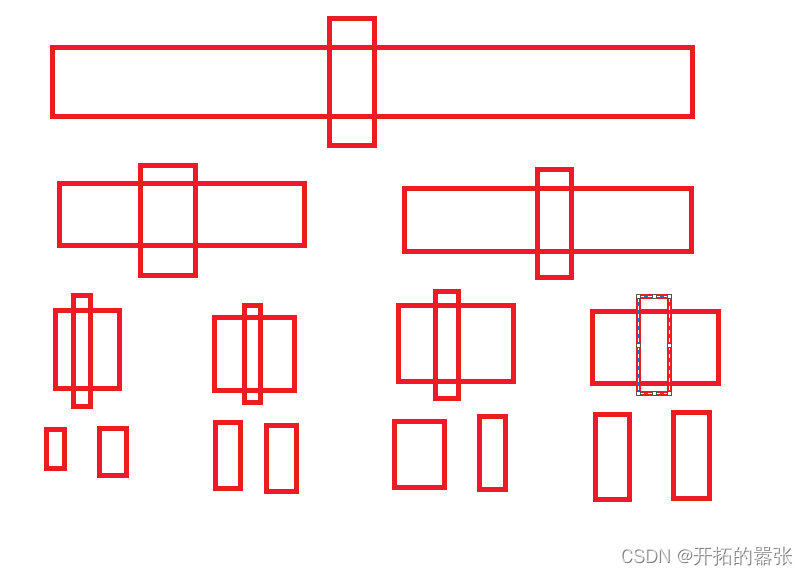
快排的非递归最好是用栈来实现:栈中存储的是数组的左右区间。先入左右区间,然后在循环出左右区间,然后单趟排序,当左区间大于右区间时,就不入栈。
void QuickSortNonR(int* a, int left, int right)
{
Stack st;
StackInit(&st);
StackPush(&st,left);
StackPush(&st,right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = Partion(a, begin, end);
if (keyi + 1 < end)
{
StackPush(&st, keyi+1);
StackPush(&st, end);
}
if (keyi - 1 > begin)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
}
StackDestroy(&st);
}7、归并排序
归并排序就是类似于之前学的链表的练习题,合并两个数组。将两个无序的数组合并成一个有序的数组。
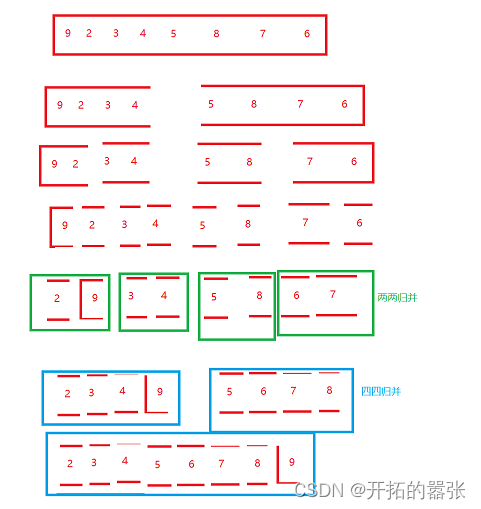
归并排序的两个核心步骤就是分解和合并。
递归代码如下:
void _MergeSort(int* a, int left, int right, int* temp)
{
if (left >= right)
{
return;
}
int mid = (left + right) / 2;
_MergeSort(a, left, mid, temp);
_MergeSort( a, mid+1, right, temp);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
temp[i++] = a[begin1++];
}
else
{
temp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
temp[i++] = a[begin2++];
}
for (int j = left; j <= right; j++)
{
a[j] = temp[j];
}
}
void MergeSort(int* a, int n)
{
int* temp = (int*)malloc(sizeof(int) * n);
if (temp == NULL)
{
printf("malloc is fail\n");
exit(-1);
}
_MergeSort(a, 0, n - 1, temp);
free(temp);
}归并的非递归实现:
归并的非递归不需要用栈或者队列,类似于层序遍历。递归的区间是 [0 0] 、[1 1]……[0 4] [4 8] ……每次区间长度增加二倍。所以在非递归中,要用到gap来控制区间大小。同时还要注意区间的修正,因为归并的非递归方式会产生一些非法的区间,所以需要手动修正区间,当end1越界时,把end1给右值,当begin2越界时第二个区间已经无效,但是越需要手动给定一个非法区间。
void MergeSortNonR(int* a, int n)
{
int* temp = (int*)malloc(sizeof(int) * n);
if (temp == NULL)
{
printf("malloc is fail\n");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
// [i,i+gap-1] [i+gap, i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int index = i;
//end1越界, [begin2,end2] 不存在
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
begin2 = n; // 修正成不存在的区间 要不然index会多加一项
end2 = n - 1;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
temp[index++] = a[begin1++];
}
else
{
temp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
temp[index++] = a[begin2++];
}
}
//归并可以,走完了在返回去
for (int j = 0; j < n; j++)
{
a[j] = temp[j];
}
gap *= 2;
}
free(temp);
}归并排序的非递归优化:主要针对修正区间的问题,如果end1越界,那么 区间[begin2 end2]也越界,直接跳出就好。
void MergeSortNonR1(int* a, int n)
{
int* temp = (int*)malloc(sizeof(int) * n);
if (temp == NULL)
{
printf("malloc is fail\n");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
// [i,i+gap-1] [i+gap, i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int index = i;
//end1越界, [begin2,end2] 不存在
if (end1 >= n|| begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
temp[index++] = a[begin1++];
}
else
{
temp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
temp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
temp[index++] = a[begin2++];
}
for (int j =i; j <=end2; j++)
{
a[j] = temp[j];
}
}
gap *= 2;
}
free(temp);
}
8、计数排序
计数排序是非比较排序,原理是映射。不需要比较数组元素的大小,只需要遍历一遍,便可知道数组元素的个数,然后以数组元素的大小映射第二个数组的下标。然后再用下标映射到数组中排序。

在第一次遍历时,遍历出数组的最大和最小值,这样是为了节省空间。
void CountSort(int* a, int n)
{
int max = a[0], min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min+1;
int* temp = (int*)malloc(sizeof(int) * range);
if (temp == NULL)
{
printf("malloc is fail\n");
exit(-1);
}
memset(temp, 0, sizeof(int) * range);
for (int i = 0; i < n; i++)
{
temp[a[i]-min]++; //用数值映射下标
}
//根据次数进行排数
int j = 0;
for (int i = 0; i < range; i++)
{
while (temp[i]--)
{
a[j++] = i+min;
}
}
}

















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











