






我们首先回顾一下模型训练的过程,模型参数的训练实际上就是一个不断迭代,寻找到一个方程 来拟合数据集。然而到这里,我们只知道需要去拟合训练集,但拟合的最佳程度我们并没有讨论过。看看下面回归模型的拟合程度,看看能发现什么。

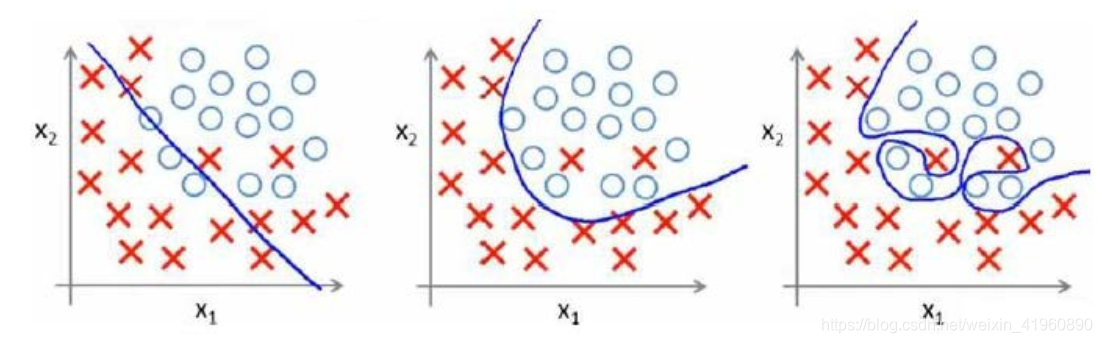
最左边的图中,拟合程度比较低,显然这样的 并不是我们想求的。连训练集的准确率如此低,那么测试集肯定也不高,也就是模型的泛化能力不高。
最右边的图中,拟合程度非常高,甚至每一个点都能通过 表达,这个难道就是我们所渴望得到的 吗?并不是!我们的数据集中无法避免的存在着许多噪声,而在理想情况下,我们希望噪声对我们的模型训练的影响为0。而如果模型将训练集中每一个点都精准描述出来,显然包含了许许多多噪声点,在后续的测试集中得到的准确率也不高。另一方面,太过复杂的 直接导致函数形状并不平滑,而会像图中那样拐来拐去,并不能起到预测的作用,“回归”模型也丧失了其预测能力(也就是模型泛化能力),显然这也不是我们想要的。
中间的图中,展现的是最适合的拟合程度, 不过于复杂或过于简单,并且能够直观的预测函数的走向。虽然它在测试集的中准确列不及图三高,但在测试集中我们得到的准确率是最高的,同时泛化能力也是最强的。
同样,在分类模型中也存在过拟合与欠拟合的情况。
总结一下:
欠拟合:泛化能力差,训练样本集准确率低,测试样本集准确率低。
过拟合:泛化能力差,训练样本集准确率高,测试样本集准确率低。
合适的拟合程度:泛化能力强,训练样本集准确率高,测试样本集准确率高
欠拟合原因:
训练样本数量少
模型复杂度过低
参数还未收敛就停止循环
欠拟合的解决办法:
增加样本数量
增加模型参数,提高模型复杂度
增加循环次数
查看是否是学习率过高导致模型无法收敛
过拟合原因:
数据噪声太大
特征太多
模型太复杂
过拟合的解决办法:
清洗数据
减少模型参数,降低模型复杂度
增加惩罚因子(正则化),保留所有的特征,但是减少参数的大小(magnitude)
原文链接:https://blog.youkuaiyun.com/weixin_41960890/article/details/104891561

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









